Deep Learning入门
主要探讨三个问题:
1.什么是深度学习?
2.他是如何实现的?
3.他可以做什么?
4.他的局限性?
一、Deep Learning简介
深度学习的概念由Hinton等人于2006年提出。
2012年6月,《纽约时报》披露了Google Brain项目,吸引了公众的广泛关注。
2012年11月,微软在中国天津演示了一个全自动的同声传译系统,后面支撑的关键技术也是DNN。
2013年1月,在百度年会上,创始人兼CEO李彦宏高调宣布要成立百度研究院,其中第一个成立的就是“深度学习研究所”(IDL,Institue of Deep Learning)。
下图即为一个简单的计算机视觉的模式识别模型,从图片(人在吃馒头)到真正得到“人在吃馒头”这个信息

其中“Black Box”这个黑盒子就是特征提取和特征选择的一个过程,这也就是deep learning要做的事情。对raw data做一个特征提取或者是说,对数据进行降维,同时又要保留图片的信息。
下面即模式识别的经典模型,包括原始数据的获得->数据预处理->特征提取->特征选择->分类、预测等。

但是在预处理、特征提取和特征选择的过程中需要大量的计算,以及人为的设定,像几何特征、纹理特征、梯度特征等。我们能不能设计一个自动学习的特征学习机器呢?答案当然是一定的,这就是deep learning可以做的事情。
Sparse coding offers an effective building block to learn useful features。稀疏编码提供了一个非常好的学习有用特征的方法。什么是稀疏编码呢?可以用下图来解释:
二、Sparse Coding
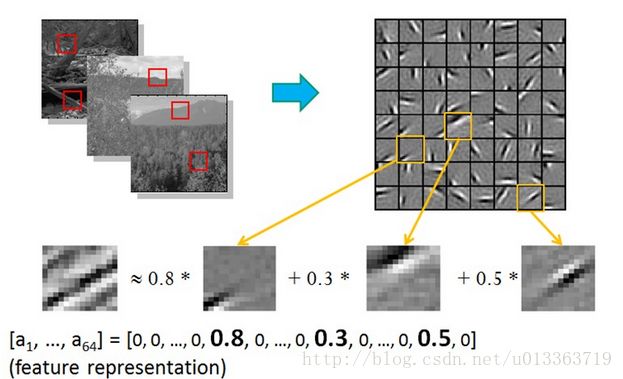
上述左面的图可以通过右面的基特征来通过一个稀疏权重来进行表示,稀疏向量(权重)即是一个向量,其中大多数为0元素,少数为非零元素,也就是非零元素是稀疏的。这个我们也可以从大脑对于特征任务的激活反应来表示,对于一个特定的任务,大脑中是由很少一部分神经元来接收和处理信息的,即神经元对于特定任务的响应是稀疏的。

稀疏编码的求解可以通过上述式子来进行解答,即LASSO问题,目前已经有很多对于这个问题的成熟解法。
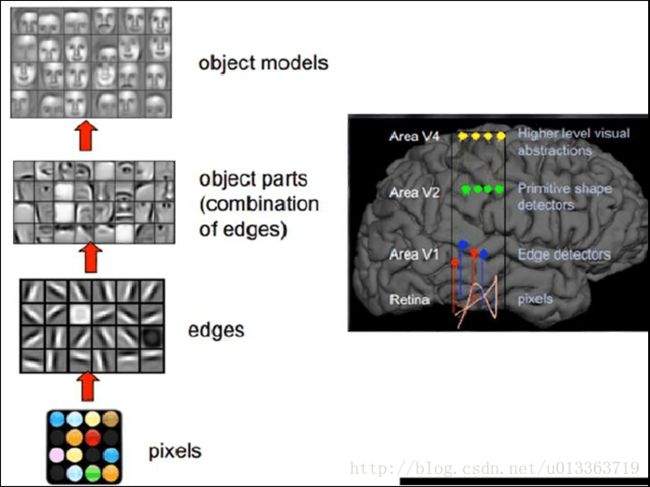
下图是对于深度学习模型的一个图解,有好多层来进行学习,每一层都是对于原始数据的不同意义抽象,但是中间层与层之间是如何进行交互的呢,或者说是如何进行编码的呢?
三、Deep Learning
对于上述问题的回答,在介绍Deep Learning之前,首先需要介绍下神经网络的概念。神经网络包括三个基本概念:
1.输入层;2.隐含层;3.输出层。
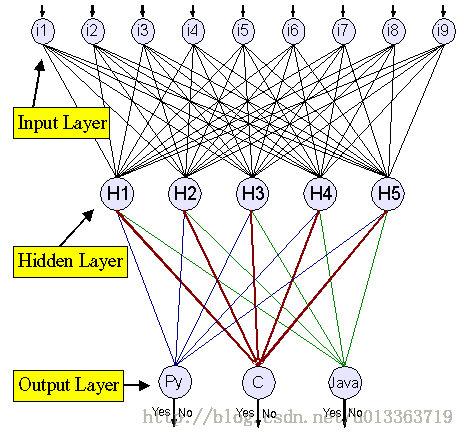
神经网络模型主要包括上述三个层,当然隐含层可以有多个层。是一种有监督的学习方法,对于神经网络参数的调整主要是通过训练样本的输入与样本标签的对应关系来做。
Deep Learning是一种无监督学习,他为特征提取提供了一种很好的方法,在Deep Learning中,主要的模型是基础是Encoder-Decoder 模型,如下图所示:
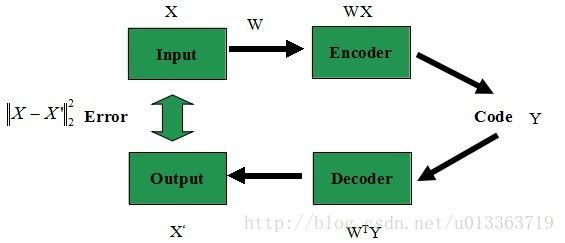
过程是从输入开始的,输入(X)通过encoder(W),将其编码(提取特征)为Code(Y),然后再通过Decoder(W'),最后输出到X',然后通过比较X和X',目标是缩小X和X‘的误差,来达到Code保留原始信息的目的。使得重建后的X’与最初的输入X是一致的。
通过上述Deep Learning框架的描述可以看到Deep Learning与神经网络的差别就是:神经网络是一种有监督的学习方法,而Deep Learning则是一种无监督的学习方法;最终的优化目标是不一样的,神经网络最终的目标是要使得已知输入最后能够得到正确的输出,而Deep Learning做的是要保证在编码(提取特征)的过程中尽量能够保留原始的信息不丢失,最后能够重建原始数据;还有一个区别就是所谓的Depth,Deep Learning中Depth的含义类似于神经网络中隐含层的层数,神经网络一般的层数是一、二层,最多也就三层,而Deep Learning层数则要有好多层。具体的层数概念可以看下图:
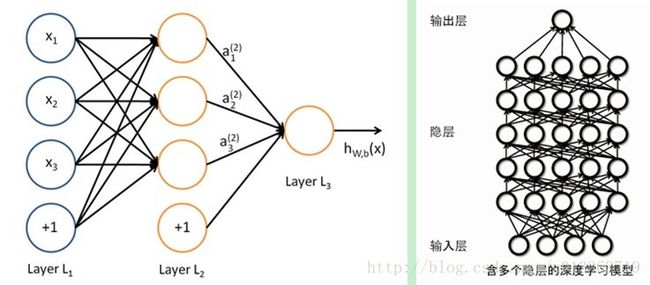
左面是神经网络,右面是Deep Learning,二者的层数区别可以明显看出。
但是局限性在于深度网络的深度如何确定,以及每一层的节点个数如何选择,目前尚没有很好的解决方案
四、应用
Deep Learning作为一种特征提取的方法,可以用于模式识别后续的许多操作,像识别分类、图像重建、压缩等,在Hinton2006年的文章中就可以看到其有关数据降维、文本聚类的相关应用。