Redis4.0 单节点集群到三主三从节点集群实验
环境相关:
OS:CentOS release 7.4.1708
IP:192.168.77.101/102/103
MEM:16G
DISK:50G
简单说明
参照《Redis4.0 三主三备集群安装配置》配置三节点主机6个redis实例并启动
第五步配置集群使用本博文操作进行
集群创建
1,在节点一上创建单实例集群:
cp -av /usr/local/redis/src/redis-trib.rb /usr/local/bin
redis-trib.rb create --replicas 0 192.168.77.101:7000
# 创建一个单实例集群会报错,因为redis的集群需要至少3个master实例
# 该报错可以忽略掉,使用fix命令进行修复

redis-trib.rb fix 192.168.77.101:7000
# 使用fix命令修复集群,需要交互式输入yes进行确认

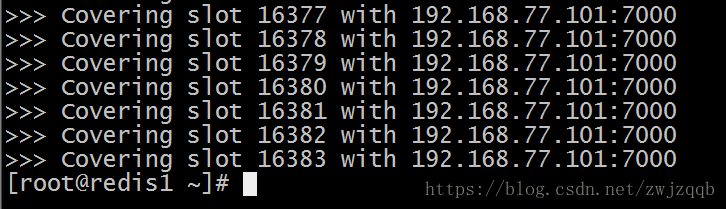
redis-cli -c -h 192.168.77.101 -p 7000 cluster nodes
redis-trib.rb check 192.168.77.101:7000
# 查看集群状态,目前集群只有一个master实例,所有的数据槽都在该实例上
# 单实例集群创建就完成了
2,添加两个主节点:
redis-trib.rb add-node 192.168.77.102:7002 192.168.77.101:7000
redis-trib.rb add-node 192.168.77.103:7004 192.168.77.101:7000
# 使用add-node命令,将102的7002和103的7004添加到集群里
redis-trib.rb check 192.168.77.101:7000
# 查看集群状态,发现目前集群中有三个master实例,但是所有的slot都在第一个master之上
# 此时,新加入的两个master实例没有任何的slot,是可以直接删掉的
redis-trib.rb reshard 192.168.77.101:7000
# 使用reshard命令重新分配slot,需要交互输入重新分配的slot数量和接收实例以及来源实例
# 两次使用该命令,将新添加的两个实例都分配一定数量的slot
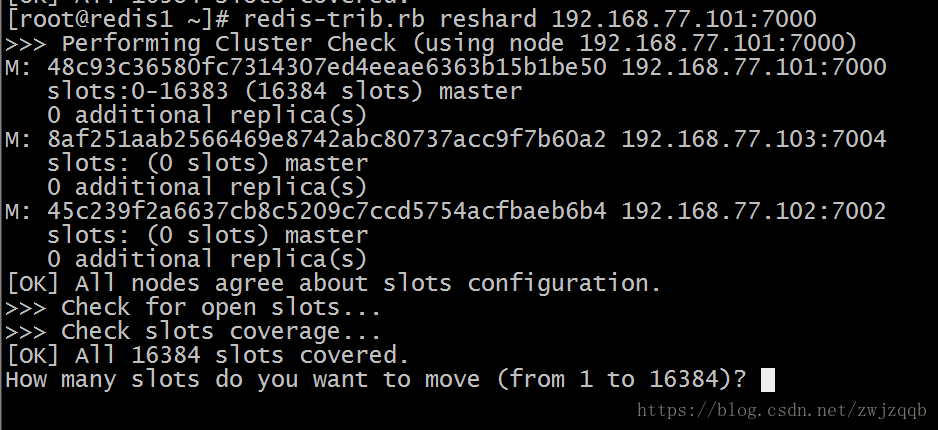
输入需要重新分配的slot数量
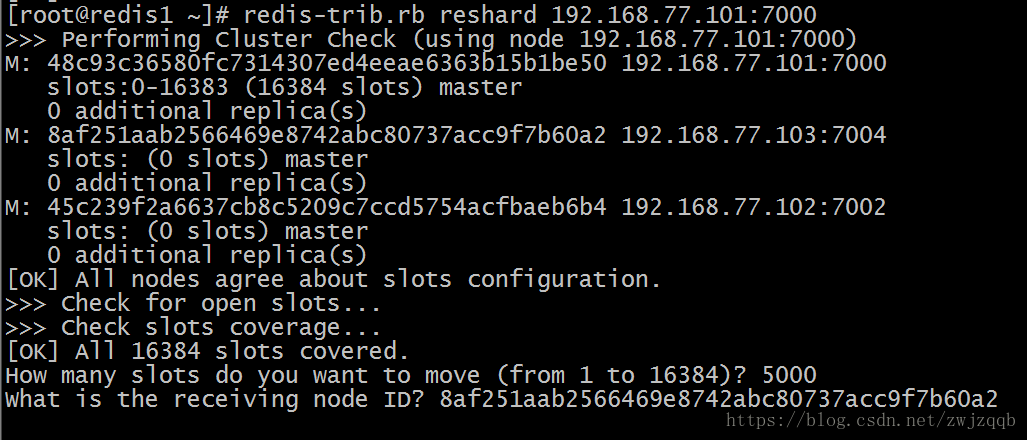
输入接收这些slot的实例ID
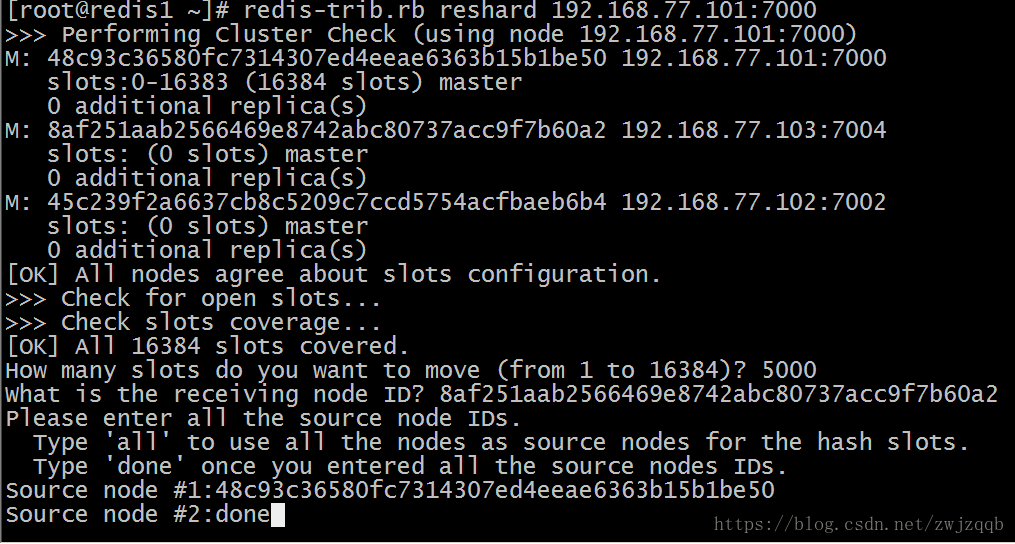
输入这些slot的来源实例ID

确认移动
如果是真实的生产环境,在移动数据槽的时候,有可能会超时失败,如移动1000个数据槽到另外一个主实例
原因是某个或某些数据槽占用内存较大,移动操作超时,就需要使用fix命令进行修复
超时失败不会对集群造成影响,已经移动成功的数据槽状态也是没问题的
可以修复后再次重新分布数据槽,减少数据槽的数量,防止再次超时失败
redis-trib.rb fix 192.168.77.101:7000
redis-trib.rb check 192.168.77.101:7000
# 检查集群节点状态,发现三个master实例都有slot存在,此时就不能直接删除master实例
3,添加三个从实例:
redis-trib.rb add-node --slave 192.168.77.101:7001 192.168.77.101:7000
redis-trib.rb add-node --slave 192.168.77.102:7003 192.168.77.101:7000
redis-trib.rb add-node --slave 192.168.77.103:7005 192.168.77.101:7000
# 添加三个slave实例,每个slave实例会自动分配到一个master实例之下
redis-cli -c -h 192.168.77.101 -p 7000 cluster nodes|sort -k2
redis-trib.rb check 192.168.77.101:7000
# 查看集群节点状态
4,生成集群状态报表:
此时的信息输出太多了,可以对cluster nodes命令的输出结果做一下转换,生成状态报表
redis-cli -c -h 192.168.77.101 -p 7000 cluster nodes|\
awk 'BEGIN{print"节点 角色 自身ID 挂接的主实例ID"}
{if($4=="-") {print $2,$3,$1,$1}
else {print $2,$3,$1,$4}}'|\
sort -rk4|column -t
# 查看集群状态,主备关系
# 当自身ID和挂接的主实例ID相同时,代表本实例是一个master实例
# 否则代表本实例是一个slave实例
5,手动调整master实例和slave实例之间的关系
当一个节点上存在两个以上的实例的时候,如果运行期间发生了宕机实例切换
会产生一个节点上运行多个master实例或者一个节点全部都是slave的情况
或者出现一个节点上的两个实例正好是一对master实例和slave实例
此时就需要手动调整master实例和slvae实例之间的对应关系,以免在节点故障时产生不可用的情况
redis-cli -c -h 192.168.77.101 -p 7001 cluster replicate 45c239f2a6637cb8c5209c7ccd5754acfbaeb6b4
redis-cli -c -h 192.168.77.102 -p 7003 cluster replicate 8af251aab2566469e8742abc80737acc9f7b60a2
redis-cli -c -h 192.168.77.103 -p 7005 cluster replicate 48c93c36580fc7314307ed4eeae6363b15b1be50
# 根据 生成集群状态报表 命令查看集群状态,验证切换操作
6,手动宕机master实例,查看集群热切:
redis-cli -c -h 192.168.77.102 -p 7002 debug segfault
# 将102的7002实例停机
# 根据 生成集群状态报表 命令查看集群状态,验证集群热切
# 发现角色一栏102的7002实例 出现 master,fail 信息
# 该实例原本的slave实例现在变成的master实例,集群热切成功
节点2将停掉的实例启动
/usr/local/bin/redis-server /usr/local/redis/redis_cluster/redis_7002.conf
# 根据 生成集群状态报表 命令查看集群状态,查看集群状态
# 发现停掉的实例启动后变成了slave状态的实例
集群删除
1,删除slave实例:
redis-trib.rb del-node 192.168.77.101:7000 45c239f2a6637cb8c5209c7ccd5754acfbaeb6b4
redis-trib.rb del-node 192.168.77.101:7000 d65247f83fbe5f3c9bc0b25c8ffbd3aace203bea
redis-trib.rb del-node 192.168.77.101:7000 a1c5ede35007ba6c1bf6d9fad907dbe09f7c6f62
# slave角色的实例可以直接删除
# 实例从集群删除后,实例会关闭
2,删除master实例:
redis-trib.rb reshard 192.168.77.101:7000
# 需要将即将删除的master实例上的slot移动到其他master实例上
# 当master实例上有slot存在时,是无法删除的
redis-trib.rb check 192.168.77.101:7000
# 查看待删除的实例上已经没有slot了
redis-trib.rb del-node 192.168.77.101:7000 f2b7cb07b0f3a16c7c650df205ef269933d5badc
redis-trib.rb del-node 192.168.77.101:7000 8af251aab2566469e8742abc80737acc9f7b60a2
# 根据 生成集群状态报表 命令查看集群状态 只剩下一个master实例了
redis-cli -c -h 192.168.77.101 -p 7000 debug segfault
# 将最后一个master实例关闭
3,残余信息删除:
实例删除后,存在残余信息,需要删除才可以做集群的再次创建添加等操作
这些残余信息是实例运行产生的,因此三个节点主机都要删除缓存信息
cd /usr/local/redis/run/data
rm -rf nodes*.conf
# 删除集群配置信息
rm -rf dump*.rdb
# 删除内存快照
rm -rf appendonly*.aof
# 删除aof日志文件
cd ..
rm -rf log/redis*.log
# 删除实例运行日志
tree
简单总结
从本次实验可以看出,redis集群其实没有对master数量和slave数量做限制
两种实例的添加和删除比较灵活,可以根据内存的使用情况增加master,然后迁移数据槽
当然被添加的master的内存限额也是没有限制的,可以根据实际生产负载添加翻倍内存限额的master
slave一般要和master内存限额一样大,因为slave在master宕机后会自动切换成master
为了集群安全,一般一个master至少有一个slave,而且要保证slave不会先于master宕机
如果一个master的所有slave都已经宕机,此时master再宕机的话就会对服务产生影响了
[TOC]