爬虫入门(7)——bilibili的用户信息的爬取
文章目录
- 1.jsonp
- 2.网站的分析
- 3.数据库的使用
- 4.代码
- 5.结果
- 6.获取face的图片
1.jsonp
JSON和JSONP虽然只有一个字母的差别,但其实他们根本不是一回事儿:JSON是一种数据交换格式,而JSONP是一种依靠开发人员的聪明才智创造出的一种非官方跨域数据交互协议。
jsonp是一种跨域通信的手段,它的原理其实很简单:
- 首先是利用script标签的src属性来实现跨域
- 通过将前端方法作为参数传递到服务器端,然后由服务器端注入参数之后再返回,实现服务器端向客户端通信
- 由于使用script标签的src属性,因此只支持get方法
ajax 的核心是通过 XmlHttpRequest 获取非本页内容,而 jsonp 的核心则是动态添加
2.网站的分析
我们需要解析的是jsonp的三个链接,里面的response有我们需要的数据,和拉钩网差不多,拉钩网是ajax的。

根据request headers构建session,根据query string parameter传递参数,根据general的url获得数据,获得数据的方法(post,get)
剩下的就是将获得的数据进行解析,保存(数据库或是excel)
3.数据库的使用
数据库的命令:
C:\Windows\system32>mysql -uroot -p
> create database bilibili;
> show databases;
> use bilibili;
use bilibili;
DROP TABLE IF EXISTS bilibili_user_info;
create table bilibili_user_info (
id int(10) unsigned NOT NULL AUTO_INCREMENT,
mid int(20) unsigned NOT NULL,
name_ varchar(45) NOT NULL,
sex varchar(45) NOT NULL,
rank_ varchar(45) NOT NULL,
face varchar(200) NOT NULL,
regtime varchar(45) NOT NULL,
birthday varchar(45) NOT NULL,
sign varchar(300) NOT NULL,
level_ varchar(45) NOT NULL,
OfficialVerifyType varchar(45) NOT NULL,
OfficialVerifyDesc varchar(100) NOT NULL,
vipType varchar(45) NOT NULL,
vipStatus varchar(45) NOT NULL,
coins int(20) unsigned NOT NULL,
following_ int(20) unsigned NOT NULL,
fans int(20) unsigned NOT NULL,
archiveview int(20) unsigned NOT NULL,
article int(20) unsigned NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
4.代码
import requests
import json
import pymysql
import time
import codecs
from multiprocessing.dummy import Pool as ThreadPool
def datetime_to_timestamp_in_milliseconds(d):
def current_milli_time():
return int(round(time.time() * 1000))
return current_milli_time()
face_fn = codecs.open('bilibili_user_face.txt', 'a', 'utf-8')
time1 = time.time()
urls = []
# Please change the range data by yourself.
for m in range(5214, 5215):
for i in range(m * 100, (m + 1) * 100):
url = 'https://space.bilibili.com/' + str(i)
urls.append(url)
def getsource(url):
mid = url.replace('https://space.bilibili.com/', '')
# network里的headers的query string parameters
payload = {
'jsonp': 'jsonp',
'mid': mid
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'Referer': url
}
# general里的 request url,Request Method: GET
jscontent = requests \
.session() \
.get('https://api.bilibili.com/x/space/acc/info?mid={}&jsonp=jsonp'.format(mid),
headers=headers,
data=payload,).text
time2 = time.time()
try:
jsDict = json.loads(jscontent)
if 'data' in jsDict.keys():
jsData = jsDict['data']
mid = jsData['mid']
name = jsData['name']
sex = jsData['sex']
rank = jsData['rank']
face = jsData['face']
sign = jsData['sign']
regtimestamp = jsData['jointime']
regtime_local = time.localtime(regtimestamp)
regtime = time.strftime("%Y-%m-%d %H:%M:%S",regtime_local)
birthday = jsData['birthday'] if 'birthday' in jsData.keys() else 'nobirthday' #
level = jsData['level']
OfficialVerifyType = jsData['official']['type']
OfficialVerifyDesc = jsData['official']['desc']
vipType = jsData['vip']['type']
vipStatus = jsData['vip']['status']
coins = jsData['coins']
print("Succeed get user info: " + str(mid) + "\t" + str(time2 - time1))
face_fn.write(face+'\n')
try:
res = requests.get(
'https://api.bilibili.com/x/relation/stat?vmid=' + str(mid) + '&jsonp=jsonp').text
js_fans_data = json.loads(res)
following = js_fans_data['data']['following']
fans = js_fans_data['data']['follower']
except:
following = 0
fans = 0
try:
viewinfo = requests.get(
'https://api.bilibili.com/x/space/upstat?mid=' + str(mid) + '&jsonp=jsonp').text
js_viewdata = json.loads(viewinfo)
archiveview = js_viewdata['data']['archive']['view']
article = js_viewdata['data']['article']['view']
except:
archiveview = 0
article = 0
else:
print('no data now')
try:
# 保存数据到数据库中
conn = pymysql.connect(
host='localhost', user='root', passwd='123456', db='bilibili', charset='utf8')
cur = conn.cursor()
cur.execute('INSERT INTO bilibili_user_info(mid, name_, sex, rank_, face, regtime, \
birthday, sign, level_, OfficialVerifyType, OfficialVerifyDesc, vipType, vipStatus, \
coins, following_, fans ,archiveview, article) \
VALUES ("%s","%s","%s","%s","%s","%s","%s","%s","%s",\
"%s","%s","%s", "%s","%s","%s","%s","%s","%s")'
%
(mid, name, sex, rank, face, regtime, \
birthday, sign, level, OfficialVerifyType, OfficialVerifyDesc, vipType, vipStatus, \
coins, following, fans ,archiveview, article))
conn.commit()
except Exception as e:
print(e)
except Exception as e:
print(e)
pass
if __name__ == "__main__":
pool = ThreadPool(1)
try:
results = pool.map(getsource, urls)
except Exception as e:
print(e)
# 测试
# getsource(urls[7])
pool.close()
pool.join()
face_fn.close()
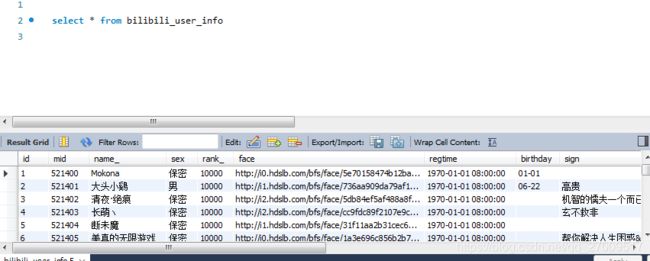
5.结果
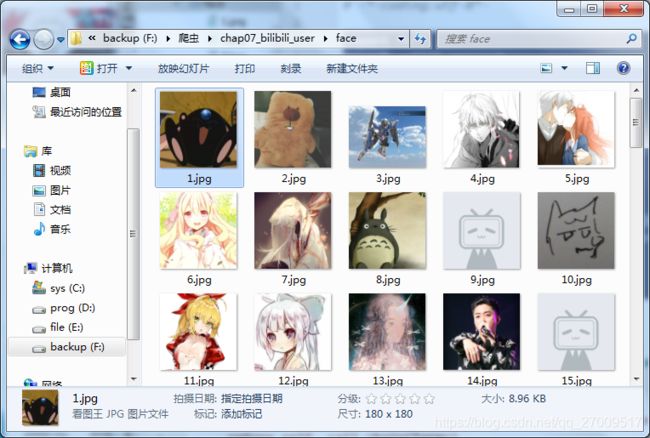
6.获取face的图片
import re
import urllib.request
f = open("bilibili_user_face.txt")
line = f.readline()
for i in range(1, 1000):
print (line),
if re.match('http://static.*', line):
line = f.readline()
print ('noface:' + str(i))
else:
path = r"./face/" + str(i) + ".jpg"
data = urllib.request.urlretrieve(line, path)
line = f.readline()
print ('succeed:' + str(i))
f.close()