Python内置四大数据结构之字典的介绍及实践案例
Python字典的介绍及实践案例
一、字典(Dict)介绍
字典是Python内置的四大数据结构之一,是一种可变的容器模型,该容器中存放的对象是一系列以(key:value)构成的键值对。其中键值对的key是唯一的,不可重复,且一旦定义不可修改;value可以是任意类型的数据,可以修改。通过给定的key,可以快速的获取到value,并且这种访问速度和字典的键值对的数量无关。字典这种数据结构的设计还与json的设计有异曲同工之妙。(更好的阅读体验,请移步我的个人博客)
格式如下所示:
d = {key1 : value1, key2 : value2 }
二、使用示例
2.1. 字典的创建:
d = {'name': 'IT之旅', 'age': 25, 'hobby': ['编程', '看报', 111], 'location': {'天涯', '海角'}, ('male', 'female'): 'male'}
print(d) # {'name': 'IT之旅', 'age': 25, 'hobby': ['编程', '看报', 111], 'location': {'海角', '天涯'}, ('male', 'female'): 'male'}
注意事项:Dict的key必须要是可被hash的,在python中,可被hash的元素有:int、float、str、tuple;不可被hash的元素有:list、set、dict。如下所示:
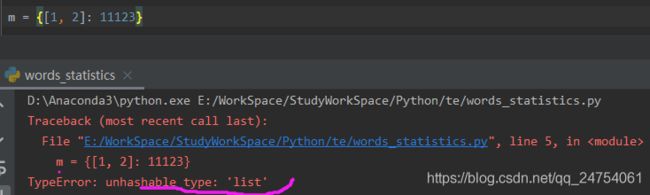
2.2. 字典的访问:
d = {'name': 'IT之旅', 'age': 25, 'hobby': ['编程', '看报', 111], 'location': {'天涯', '海角'}, ('male', 'female'): 'male'}
# 根据键获取值
print(d['name']) # IT之旅
print(d.get('name')) # IT之旅
# 成员存在则进行访问
if 'age' in d:
print(d.get('age')) # 25
# 循环遍历访问
for k in d:
print(k, d[k])
'''
name IT之旅
age 25
hobby ['编程', '看报', 111]
location {'天涯', '海角'}
('male', 'female') male
'''
for k, v in d.items():
print(k, '-->', v)
'''
name --> IT之旅
age --> 25
hobby --> ['编程', '看报', 111]
location --> {'海角', '天涯'}
('male', 'female') --> male
'''
for v in d.values():
print(v)
'''
IT之旅
25
['编程', '看报', 111]
{'海角', '天涯'}
male
'''2.2. 修改字典的值:
d = {'name': 'IT之旅', 'age': 25, 'hobby': ['编程', '看报', 111], 'location': {'天涯', '海角'}, ('male', 'female'): 'male'}
print(d['age']) # 25
d['age'] = 27
print(d['age']) # 272.3. 删除字典的元素:
d = {'name': 'IT之旅', 'age': 25, 'hobby': ['编程', '看报', 111], 'location': {'天涯', '海角'}, ('male', 'female'): 'male'}
del d['name']
print(d) # name键值对已被删除
d.clear()
print(d) # d已被清除,输出为空的对象 {}
del d
print(d) # name 'd' is not defined2.4. 增加字典元素:
d = {'name': 'IT之旅', 'age': 25, 'hobby': ['编程', '看报', 111], 'location': {'天涯', '海角'}, ('male', 'female'): 'male'}
del d['name']
del d['hobby']
del d['location']
print(d) # {'age': 25, ('male', 'female'): 'male'}
d.update({'name_1': '测试用户名'}) # 添加元素值
print(d) # {'age': 25, ('male', 'female'): 'male', 'name_1': '测试用户名'}
m = {'test': 'test', 1: 1} # 合并字典值
d.update(m)
print(d) # {'age': 25, ('male', 'female'): 'male', 'name_1': '测试用户名', 'test': 'test', 1: 1}2.5. 字典的复制:
d = {'name': 'IT之旅', 'age': 25, 'hobby': ['编程', '看报', 111], 'location': {'天涯', '海角'}, ('male', 'female'): 'male'}
m = d.copy() # 浅复制
print(m == d) # True
print(id(m) == id(d)) # False
n = d # 直接赋值
print(id(n) == id(d)) # True
'''
需要注意直接赋值和浅拷贝的区别
'''2.6. python内置了一些函数用于操作字典,包含有:计算字典元素个数的len()函数,以可打印字符串输出的str()函数,删除字典给定键 key 所对应值的pop()函数,等等。
三、实践案例 - 统计英文文章中单词出现的频率
英文句子如下:
With the gradual deepening of Internet of things, artificial intelligence, big data and other concepts, the construction of smart city is particularly urgent, and smart transportation is an important step in this link, which is not only the key words of urban construction,
It is also an important traffic information data of each city component. In order to strengthen data information sharing and exchange, each region has begun to make efforts to build.
As an important indicator of road section, traffic indicator cone plays an important role in road section status indication and vehicle drainage.
The traditional cone barrel has some disadvantages, such as single function, poor warning effect, inconvenient transportation and poor ability to withstand harsh conditions, which can not meet the requirements of current conditions. Based on this situation,
We start to use NB-IoT communication technology and IPv6 protocol to further explore the use value of cone barrel and further improve the utilization rate.
What is the next direction of the Internet of things? We'll see
代码如下:(将上面的单词放进一个文本中,然后修改代码中文本文件的位置即可运行代码)
original_words = open(r'C:\Users\itour\Desktop\words-original.txt', 'r', encoding='utf-8')
# 将文本中的句子分割成一个一个单次,去除标点符号后存入word_list列表中。
word_list = []
for lines in original_words:
word = lines.replace('\n', '').split(' ')
for reduce_word in word: # 去除单次中的标点符号
word_list.append(reduce_word.strip(',').strip('?').strip('.'))
# 使用字典数据结构统计单词出现的频率
word_dict = {}
for w in word_list:
if w in word_dict.keys():
word_dict[w] += 1
else:
word_dict[w] = 1
# 输出结果
print(word_dict)
'''
{'With': 1, 'the': 8, 'gradual': 1, 'deepening': 1, 'of': 10, 'Internet': 2,
'things': 2, 'artificial': 1, 'intelligence': 1, 'big': 1, 'data': 3, 'and': 7,
'other': 1, 'concepts': 1, 'construction': 2, 'smart': 2, 'city': 2, 'is': 5,
'particularly': 1, 'urgent': 1, 'transportation': 2, 'an': 4, 'important': 4,
'step': 1, 'in': 2, 'this': 2, 'link': 1, 'which': 2, 'not': 2, 'only': 1, 'key': 1,
'words': 1, 'urban': 1, 'It': 1, 'also': 1, 'traffic': 2, 'information': 2, 'each': 2,
'component': 1, 'In': 1, 'order': 1, 'to': 6, 'strengthen': 1, 'sharing': 1, 'exchange': 1,
'region': 1, 'has': 2, 'begun': 1, 'make': 1, 'efforts': 1, 'build': 1, 'As': 1,
'indicator': 2, 'road': 2, 'section': 2, 'cone': 3, 'plays': 1, 'role': 1,
'status': 1, 'indication': 1, 'explore': 1}
'''
四、总结
Python的字典数据结构,在很多方面都有应用,因此,掌握这个数据结构是非常必要的。