逻辑回归,决策树,支持向量机 选择方案
逻辑回归 vs 决策树 vs 支持向量机
原文 part1
原文 part2
分类是我们在工业界经常遇到的场景,本文探讨了3种常用的分类器,逻辑回归LR,决策树DT和支持向量机SVM。
这三个算法都被广泛应用于分类(当然LR,DT和SVR也可以用于回归,但是本文先不讨论)。我经常看到人们会问,这个问题我该使用LR呢还是决策树(或者GBDT)还是SVM呢。然后你会听到一个“经典”而且“绝对正确”的答案:”It depends.”这个答案简直毫无卵用。所以本文将探讨一下面临模型选择的时候到底depends on what。
接下来是一个简单的2-D的解释,至于向更高维度的扩展延伸,就靠你们了~
从最重要的问题入手:我们在分类时想要做什么~听起来很蠢有木有,重新组织一下问题~为了完成分类,我们尝试得到一个分类边界或者是一个你和曲线,哪个方式能够在我们的特征空间里更好的进行分类呢?
特征空间听起来很fancy,看一个简单的例子,我有一些样本数据,特征(x1,x2)和标签(0或1)。
可以看到我们的特征是2-D的,不同的颜色代表着不同的类别标签,我们想要使用算法来获得一个曲线来区分这些不同类别的样本。
其实可以很直观的看出来,这个场景下圆是一个比较理想的分类边界。而不同的分类边界也就是LR,DT和SVM的区别所在。
首先看一下逻辑回归,对于LR给出的决策边界,我们对于这个经典的S型曲线会有不少困惑:
其实这个蓝色的曲线并不是决策边界,它只是把二分类的答案使用连续值输出置信度的一个方式,例如给出分类结果为1的置信度。LR决策面其实是一条直线( 高维情况下平面或超平面 ),为什么呢?
来看下逻辑回归的公式:
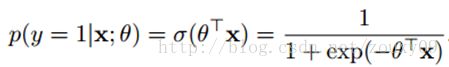
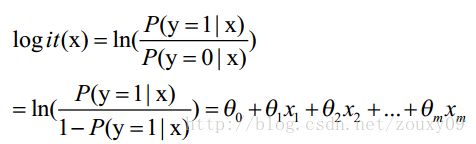
图摘自zouxy09的博客
为了判定样本属于哪一类,需要设置一个截断分数,高于这个分数就预测为正例,低于这个分数就预测为负例。例如阶段分数是c,所以我们的决策过程如下:
Y=1 当 p>c,否则为0。因而解决了之前的一个问题:LR的决策边界其实是一条直线。
所以对于之前的数据集我们得到的LR的决策边界如下:
可以看出来LR的效果并不好,因为不管你怎么调,决策边界都是线性的,无法拟合出来一个圆形的决策边界,所以LR比较适合解决线性可分的问题(虽然你也可以通过对特征进行变换从而使样本数据线性可分,但是目前不讨论这个东西,这个是特征工程的工作,和模型没关系)。
现在看一下决策树的工作原理,决策树是按照单个变量进行一层一层的规则过滤,例如:
x1大于或小于const或者x2大于或小于某个const做的工作是使用直线来划分特征空间,如下图:
如果我们让决策树更复杂一点,例如深度更大,则这些判断条件能够更细地划分特征空间,从而越来越逼近那个圆形的决策边界。
因此,如果决策边界是非线性的,而且能够通过矩形来划分特征空间,那么决策树就是优于LR的模型。
最后,看一下SVM的工作模式,SVM通过核函数把特征空间映射到其他维度,从而使得样本数据线性可分,换个说法,SVM通过添加新的维度的特征从而使得样本线性可分。从下图可以看到,当把特征映射到另一个空间,那么一个决策面可以把数据区分开,换言之,如果把这个决策面映射到初始特征空间,我们就相当于得到了一个非线性的决策边界。
在原始的2-D的特征基础上添加一个新的特征,我们就可以通过一个平面,使得这个3-D的样本数据线性可分了(使用n-1维的超平面把n维的样本分开),如果把这个分类面投射到原始的2-D空间,那么其实我们会得到一个圆哦,虽然这个分类边界并不会像下图这样理想,但是也是能够逼近这个圆的。
到这里我们大致明白了3个模型的工作原理,但是一开始提出的问题并没有解决,it depends on what? 什么情况下使用什么模型,优势是什么,劣势又是什么?我们下面来探讨这个问题~
LR,DT,SVM都有自身的特性,首先来看一下LR,工业界最受青睐的机器学习算法,训练、预测的高效性能以及算法容易实现使其能轻松适应工业界的需求。LR还有个非常方便实用的额外功能就是它并不会给出离散的分类结果,而是给出该样本属于各个类别的概率(多分类的LR就是softmax),可以尝试不同的截断方式来在评测指标上进行同一模型的性能评估,从而得到最好的截断分数。LR不管是实现还是训练或者预测都非常高效,很轻松的handle大规模数据的问题(同时LR也很适合online learning)。此外,LR对于样本噪声是robust的,对于“mild”的多重共线性问题也不会受到太大影响,在特征的多重共线性很强的情况下,LR也可以通过L2正则化来应对该问题,虽然在有些情况下(想要稀疏特征)L2正则化并不太适用。
但是,当我们有大量的特征以及部分丢失数据时,LR就开始费劲了。太多的分类变量(变量值是定性的,表现为互不相容的类别或属性,例如性别,年龄段(1,2,3,4,5)等)也会导致LR的性能较差(这个时候可以考虑做离散化,其实肯定是要做离散化的)。还有一种论调是LR使用所有的样本数据用于训练,这引发了一个争论:明显是正例或者负例的样本(这种样本离分类边界较远,不大会影响分类的curve)不太应该被考虑太多,模型理想情况是由分类边界的样本决定的(类似SVM的思想),如下图。还有一个情况就是当特征是非线性时,需要做特征变换,这可能会导致特征维度急剧上升。下面是我认为的LR的一些利弊:
LR的优势:
- 对观测样本的概率值输出
- 实现简单高效
- 多重共线性的问题可以通过L2正则化来应对
- 大量的工业界解决方案
- 支持online learning(个人补充)
LR的劣势
- 特征空间太大时表现不太好
- 对于大量的分类变量无能为力
- 对于非线性特征需要做特征变换
- 依赖所有的样本数据(作者认为这其实不是啥问题。。)
接下来我们聊一下决策树和SVM。
决策树对于单调的特征变换是”indifferent”的,也就是说特征的单调变换对于决策树来说不会产生任何影响(我本人最早使用决策树时没有理解内部的机制,当时还做了特征归一化等工作,发现效果没有任何变化),因为决策树是通过简单的使用矩形切分特征空间的,单调的特征变换只是做了特征空间的缩放而已。由于决策树是的分支生成是使用离散的区间或类别值的,所以对于不管多少分类变量都能够轻松适应,而且通过决策树生成出来的模型很直观而且容易解释(随着决策树的分支解释即可),而且决策树也可以通过计算落到该叶子类目的标签平均值获得最终类别的概率输出。但是这就引发了决策树的最大问题:非常容易过拟合,我们很容易就会生成一个完美拟合训练集的模型,但是该模型在测试集合上的表现却很poor,所以这个时候就需要剪枝以及交叉验证来保证模型不要过拟合了。
过拟合的问题还可以通过使用随机森林的方式来解决,随机森林是对决策树的一个很smart的扩展,即使用不同的特征集合和样本集合生成多棵决策树,让它们来vote预测样本的标签值。但是随机森林并没有像单纯决策树一样的解释能力。
Also by decision trees have forced interactions between variables , which makes them rather inefficient if most of your variables have no or very weak interactions. On the other hand this design also makes them rather less susceptible to multicollinearity.
这段是在说决策树也不会受到多重共线性的影响,但是我本人不是很理解
DT的优势:
- 直观的决策过程
- 能够处理非线性特征
- 考虑了特征相关性
DT的劣势
- 极易过拟合(使用RF可以一定程度防止过拟合,但是只要是模型就会过拟合!)
- 无法输出score,只能给出直接的分类结果
最后谈一下支持向量机SVM,SVM最大的好处就是它只依赖于处于分类边界的样本来构建分类面,可以处理非线性的特征,同时,只依赖于决策边界的样本还可以让他们能够应对”obvious”样本缺失的问题。由于SVM能够轻松搞定大规模的特征空间所以在文本分析等特征维度较高的领域是比较好的选择。SVM的可解释性并不像决策树一样直观,如果使用非线性核函数,SVM的计算代价会高很多。
SVM的优势:
- 可以处理高维特征
- 使用核函数轻松应对非线的性特征空间
- 分类面不依赖于所有数据
SVM的劣势:
- 对于大量的观测样本,效率会很低
- 找到一个“合适”的核函数还是很tricky的
我总结出了一个工作流程来让大家参考如何决定使用哪个模型:
1. 使用LR试一把总归不会错的,至少是个baseline
2. 看看决策树相关模型例如随机森林,GBDT有没有带来显著的效果提升,即使最终没有用这个模型,也可以用随机森林的结果来去除噪声特征
3. 如果你的特征空间和观测样本都很大,有足够的计算资源和时间,试试SVM吧,
最后是这位老司机的一点人生经验:好的数据远比模型本身重要,记住一定要使用你在对应领域的知识来进行完备的特征工程的工作;然后还有一个有效途径就是多使用ensembles,就是多个模型混合,给出结果。
个人想法:
本文加粗或者斜体字都是我自己的观点和补充。本文提到了多重共线性和正则化,如果不知道这个的话,是无法很好的理解这些内容的,我后面会写文章总结介绍一下多重共线性以及正则化相关的内容~