关联规则挖掘
直接用实例来解释概念更清楚一些,加入数据库中存在10条交易记录(Transaction),具体如下表所示:
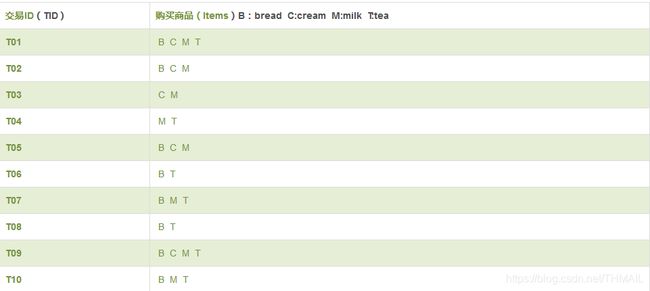
几个概念:
项目(item):其中的B C M T 都称作item。
项集(itemset):item的集合,例如{B C}、{C M T}等,每个顾客购买的都是一个itemset。其中,itemset中item的个数成为itemset的长度,含有k个item的itemset成为K-itemset.
交易(transaction):定义I为所有商品的集合,在这个例子中I={B C M T}。每个非空的I子集都成为一个交易。所有交易构成交易数据库D。
项集支持度(support):回个一下项集概念,项集X的支持度定义为:项集X在交易库中出现的次数(频数)与所有交易次数的比。例如T02的项集X={B C M},则support(X)=2/10=0.2。项集支持度也就是项集出现的频率。
频繁集(frequent itemset):如果一个项集的支持度达到一定程度(人为规定),就称该项集为频繁项集,简称频繁集。这个人为规定的界限就被叫做项集最小支持度(记为supmin)。更通俗地说,如果某个项集(商品组合)在交易库中出现的频率达到一定值,就称作频繁集。如果K项集支持度大于最小支持度,则称作K-频繁集,记为Lk。
关联规则(association rule):R:X→Y
其中,X、Y都是I的子集,且X、Y交集为空。这一规则表示如果项集X在某一交易中出现,则会导致项集Y以某一概率同时出现在这一交易中。例如R1:{B}→{M} 表示如果面包B出现在一个购物篮中,则牛奶M以某一概率同时出现在该购物篮中。X称为条件(antecedent or left-hand-side LHS),Y称为结果(consequence or right hand side RHS)。衡量某一关联规则有两个指标:关联规则的支持度(support)和可信度(confidence)。
关联规则的支持度:交易库中同时出现X、Y的交易数与总交易数之比,记为support(X→Y)。其实也就是两个项集{X Y}出现在交易库中的频率。
关联规则的可信度:包含X、Y的交易数与包含X的交易数之比,记为confidence(X→Y)。也就是条件概率:当项集X出现时,项集Y同时出现的概率,P(Y|X)。
Conviction:conv(X→Y)=【 1-sup(Y)】/【1-conf(X→Y)】表示X出现而Y不出现的概率。也就是规则预测错误的概率。
综合一下,关联规则R就是:如果项集X出现在某一购物篮,则项集X同时出现在这一购物篮的概率为confidence (X→Y)。
如果我们定义一个关联规则最小支持度和关联规则最小可信度,当某一规则两个指标都大于最低要求时,则成为强关联规则。反之成为弱关联规则。
例如,在上表中,对于规则R:B → M,假设这一关联规则的支持度为6/10=0.6,表示同时包含C和M的交易数占总交易的60%.可信度为6/8=0.75,表示购买面包B的人,有75%可能性同时购买牛奶。也就是当抽样样本足够大时,每100个人当中,有75个人同时买了面包和牛奶,两外25个人只买其中一样。
Rakesh Agrawal
关联规则的发现一般分为两个步骤:
1) 根据给定的最小项集支持度,找出所有满足条件的项集,即频繁项集。
2) 根据最小可信度,在所有频繁集中找出符合条件的关联规则。
步骤1中,可能的项集组合(itemset)有2n-1(排除空集),找出所有频繁集不是一个简单的任务。注意的是,如果某个项集X是频繁集,则X的子集也必定为频繁集。
关联规则分类:
数据的维度:单维和多维,例如面包-->牛奶为单维关联规则。而 性别=“女”--->职业=“教师”为多维。
数据的抽象层次:单层关联规则和多层关联规则。 单层的还是面包牛奶的例子,多层的比如:面包--->伊利牌牛奶。
变量的类型:布尔型关联规则和数值型。布尔型: 性别=“女”--->职业=“教师。 数值型:工龄=“5”----->平均工资=“3000”
频繁项集常用挖掘算法:Apriori算法、FP-growth算法、Eclat算法
在IBM SPSS Modeler中,用简单的数据集测试Apriori算法。详细请参考:
http://blog.sciencenet.cn/blog-71538-682195.html