python常用模块(一) 数据处理 matplotlib numpy pandas
如果要批量安装库的话,可以建立一个requirements.txt文件,里面写上
matplotlib==2.2.2
numpy==1.14.2
pandas==0.20.3
TA-Lib==0.4.16
tables==3.4.2 hdf5
jupyter==1.0.0
然后执行 pin install -r requirements.txt
1、jupyter notebook 快捷键
Shift+Enter, 执行本单元代码,并跳转到下一单元
Ctrl+Enter,执行本单元代码,留在本单元
命令模式:按ESC进入
Y,cell切换到Code模式
M,cell切换到Markdown模式
A, 在当前cell的上面添加cell
B,在当前cell的下面添加cell
双击D:删除当前cell
Z,回退
L,为当前cell加上行号
编辑模式:按Enter进入
多光标操作:Ctrl键点击鼠标
回退:Ctrl+Z
重做:Ctrl+Y
补全代码:变量、方法后跟Tab键
为一行或多行代码添加/取消注释:Ctrl+/
屏蔽自动输出信息:可在最后一条语句之后加一个分号
2、Matplotlib
Matplotlib就是python的绘图库,库由三层结构组成: 容器层、辅助显示层、图像层,也就是画图的三个步骤。
1)容器层由画板层Canvas、画布层Figure、绘图区/坐标系Axes组成
Canvas是位于最底层的系统层,对于使用这来说是接触不到的,在绘图的过程中充当画板的角色,即放置画布(Figure)的工具
Figure是Canvas上方的第一层,也是需要用户来操做的第一层,在绘图的过程中充当画布的角色。
Axes是应用层的第二层,在绘图的过程中相当于画布上的绘图区的角色。
Figure:指整个图形(可以通过plt.figure()设置画布上的绘图区的角色)
Axes(坐标系):数据的绘图区域
Axis(坐标轴):坐标系中的一条轴,包含大小限制、刻度和刻度标签
特点是:
一个figure(画布)可以包含多个axes(坐标系、绘图区),但是一个axes只能属于一个figure
一个axes(坐标系、绘图区)可以包含多个axis(坐标轴),包含两个即为2d坐标系,3个即为3d坐标系
2)辅助显示层
辅助显示层为Axes(绘图区)内的除了根据数据绘制出的图像以外的内容,主要包括Axes外观(facecolor)、边框线(spines)、坐标轴(axis)、坐标轴名称(axis label)、坐标轴刻度(tick)、坐标轴刻度标签(tick label)、网格线(grid)、图例(legend)、标题(title)等内容。
3)图像层
图像层指Axes内通过plot、scatter、bar、histogram、pie等函数根据数据绘制出的图像。
总结:
Canvas(画板) 位于最底层,用户一般接触不到
Figure(画布) 建立在Canvas之上
Axes(绘图区) 建立在Figure之上
坐标轴(axis)、图例(legend)等辅助显示层以及图像层都是建立在Axes之上
现在开始画图
matplotlib.pyplot模块 包含了一系列的画图函数,这些函数作用于当前图形的当前坐标系(axes)
import matplotlib.pyplot as plt设置画布属性plt.figure, 要绘图的第一步就要创建画布
plt.figure(figsize=(),dpi=)
参数: figsize:知道图的长宽 dpi:图像的清晰度 ,返回fig对象,参数也可以不写使用默认值
图片保存
plt.savefig(path)
绘制折线图(plot)
# 1、创建画布
plt.figure(figsize=(20, 8), dpi=80)
# 2、绘制图像
plt.plot([1, 2, 3, 4, 5, 6, 7], [17, 17, 18, 15, 11, 11, 13])
# 保存图像
plt.savefig("test78.png")
# 3、显示图像
plt.show()注意:plt.show()会释放figure资源,如果在显示图像之后保存图片将只能保存空图片。
完善折线图
1)添加xy刻度信息、x轴y轴坐标描述、网格显示
plt.xticks(x,**kwargs) #x:要显示的刻度值
plt.yticks(y,**kwargs) #y:要显示的刻度值
#x轴y轴 标题
plt.xlabel("时间")
plt.ylabel("温度")
plt.title("温度变化图")
#网格
plt.grid(True,linestyle='--',alpha=0.5)# 需求:画出某城市11点到12点1小时内每分钟的温度变化折线图,温度范围在15度~18度
import random
# 1、准备数据 x y
x = range(60)
y_shanghai = [random.uniform(15, 18) for i in x]
# 2、创建画布
plt.figure(figsize=(20, 8), dpi=80)
# 3、绘制图像
plt.plot(x, y_shanghai)
# 修改x、y刻度
# 准备x的刻度说明
x_label = ["11点{}分".format(i) for i in x]
plt.xticks(x[::5], x_label[::5])
plt.yticks(range(0, 40, 5))
# 添加网格显示
plt.grid(linestyle="--", alpha=0.5)
# 添加描述信息
plt.xlabel("时间变化")
plt.ylabel("温度变化")
plt.title("某城市11点到12点每分钟的温度变化状况")
# 4、显示图
plt.show()
2)多次plot、显示图例
plt.plot(x, y_shanghai, color="r", linestyle="-.", label="上海")
plt.plot(x, y_beijing,color="b",label="北京")
#显示图例
plt.legend()图形设置
| 图形颜色 | 风格字符 |
| r红色 | -实线 |
| g绿色 | --虚线 |
| b蓝色 | -.点划线 |
| w白色 | :点虚线 |
| c青色 | ' '留空、空格 |
| m洋红 | |
| y黄色 | |
| k黑色 |
图例位置
| Location string | Location Code |
| 'best' | 0 |
| 'upper right' | 1 |
| 'upper left' | 2 |
| 'lower left' | 3 |
| 'lower right' | 4 |
| 'right' | 5 |
| 'center left' | 6 |
plt.legend(loc="lower left")
# 需求:再添加一个城市的温度变化
# 收集到北京当天温度变化情况,温度在1度到3度。
# 1、准备数据 x y
x = range(60)
y_shanghai = [random.uniform(15, 18) for i in x]
y_beijing = [random.uniform(1, 3) for i in x]
# 2、创建画布
plt.figure(figsize=(20, 8), dpi=80)
# 3、绘制图像
plt.plot(x, y_shanghai, color="r", linestyle="-.", label="上海")
plt.plot(x, y_beijing, color="b", label="北京")
# 显示图例
plt.legend()
# 修改x、y刻度
# 准备x的刻度说明
x_label = ["11点{}分".format(i) for i in x]
plt.xticks(x[::5], x_label[::5])
plt.yticks(range(0, 40, 5))
# 添加网格显示
plt.grid(linestyle="--", alpha=0.5)
# 添加描述信息
plt.xlabel("时间变化")
plt.ylabel("温度变化")
plt.title("上海、北京11点到12点每分钟的温度变化状况")
# 4、显示图
plt.show()
3) 多个坐标系显示 plt.subplots
matplotlib.pyplot.subplots(nrows=1,ncols=1, **fig_kw)
参数:nrows=1,ncols=1 int型 默认为1
设置标题等方法: set_xticks set_yticks set_xlabel set_ylabel
# 需求:再添加一个城市的温度变化
# 收集到北京当天温度变化情况,温度在1度到3度。
import random
# 1、准备数据 x y
x = range(60)
y_shanghai = [random.uniform(15, 18) for i in x]
y_beijing = [random.uniform(1, 3) for i in x]
# 2、创建画布
# plt.figure(figsize=(20, 8), dpi=80)
figure, axes = plt.subplots(nrows=1, ncols=2, figsize=(20, 8), dpi=80)
# 3、绘制图像
axes[0].plot(x, y_shanghai, color="r", linestyle="-.", label="上海")
axes[1].plot(x, y_beijing, color="b", label="北京")
# 显示图例
axes[0].legend()
axes[1].legend()
# 修改x、y刻度
# 准备x的刻度说明
x_label = ["11点{}分".format(i) for i in x]
axes[0].set_xticks(x[::5])
axes[0].set_xticklabels(x_label)
axes[0].set_yticks(range(0, 40, 5))
axes[1].set_xticks(x[::5])
axes[1].set_xticklabels(x_label)
axes[1].set_yticks(range(0, 40, 5))
# 添加网格显示
axes[0].grid(linestyle="--", alpha=0.5)
axes[1].grid(linestyle="--", alpha=0.5)
# 添加描述信息
axes[0].set_xlabel("时间变化")
axes[0].set_ylabel("温度变化")
axes[0].set_title("上海11点到12点每分钟的温度变化状况")
axes[1].set_xlabel("时间变化")
axes[1].set_ylabel("温度变化")
axes[1].set_title("北京11点到12点每分钟的温度变化状况")
# 4、显示图
plt.show()注意:plt函数相当于面向过程的画图方法,axes.set_ 等方法相当于面向对象的画图方法
import numpy as np
# 1、准备x,y数据
x = np.linspace(-1, 1, 1000)
y = 2 * x * x
# 2、创建画布
plt.figure(figsize=(20, 8), dpi=80)
# 3、绘制图像
plt.plot(x, y)
# 添加网格显示
plt.grid(linestyle="--", alpha=0.5)
# 4、显示图像
plt.show()绘制散点图 (plt.scatter)
# 需求:探究房屋面积和房屋价格的关系
# 1、准备数据
x = [225.98, 247.07, 253.14, 457.85, 241.58, 301.01, 20.67, 288.64,
163.56, 120.06, 207.83, 342.75, 147.9 , 53.06, 224.72, 29.51,
21.61, 483.21, 245.25, 399.25, 343.35]
y = [196.63, 203.88, 210.75, 372.74, 202.41, 247.61, 24.9 , 239.34,
140.32, 104.15, 176.84, 288.23, 128.79, 49.64, 191.74, 33.1 ,
30.74, 400.02, 205.35, 330.64, 283.45]
# 2、创建画布
plt.figure(figsize=(20, 8), dpi=80)
# 3、绘制图像
plt.scatter(x, y)
# 4、显示图像
plt.show()绘制柱状图(plt.bar)
matplotlib.pyplot.bar(x,width,align='center',**kwargs)
参数:align柱状图对齐方式 **kwargs:柱状图的颜色 参数都是可选的
# 1、准备数据
movie_names = ['雷神3:诸神黄昏','正义联盟','东方快车谋杀案','寻梦环游记','全球风暴', '降魔传','追捕','七十七天','密战','狂兽','其它']
tickets = [73853,57767,22354,15969,14839,8725,8716,8318,7916,6764,52222]
# 2、创建画布
plt.figure(figsize=(20, 8), dpi=80)
# 3、绘制柱状图
x_ticks = range(len(movie_names))
plt.bar(x_ticks, tickets, color=['b','r','g','y','c','m','y','k','c','g','b'])
# 修改x刻度
plt.xticks(x_ticks, movie_names)
# 添加标题
plt.title("电影票房收入对比")
# 添加网格显示
plt.grid(linestyle="--", alpha=0.5)
# 4、显示图像
plt.show()
# 1、准备数据
movie_name = ['雷神3:诸神黄昏','正义联盟','寻梦环游记']
first_day = [10587.6,10062.5,1275.7]
first_weekend=[36224.9,34479.6,11830]
# 2、创建画布
plt.figure(figsize=(20, 8), dpi=80)
# 3、绘制柱状图
plt.bar(range(3), first_day, width=0.2, label="首日票房")
plt.bar([0.2, 1.2, 2.2], first_weekend, width=0.2, label="首周票房")
# 显示图例
plt.legend()
# 修改刻度
plt.xticks([0.1, 1.1, 2.1], movie_name)
# 4、显示图像
plt.show() 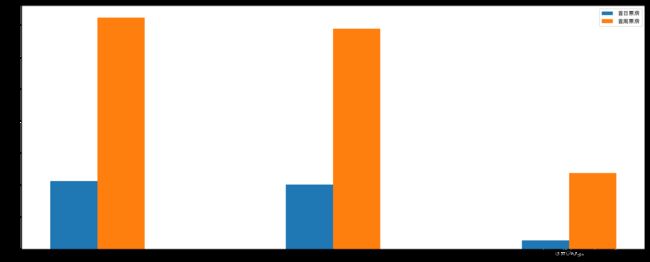
绘制直方图
matplotlib.pyplot.hist(x, bins=None, normed=Node, **kwargs)
绘制直方图首先要设置组距,然后计算组数
# 需求:电影时长分布状况
# 1、准备数据
time = [131, 98, 125, 131, 124, 139, 131, 117, 128, 108, 135, 138, 131, 102, 107,114, 119, 128, 121, 142, 127, 130, 124, 101, 110, 116, 117,
110, 128,128, 115, 99, 136, 126, 134, 95, 138, 117, 111,78, 132, 124, 113, 150,110, 117, 86, 95, 144, 105, 126, 130,126, 130, 126,
116, 123, 106, 112, 138, 123, 86, 101, 99, 136,123, 117, 119, 105, 137, 123, 128, 125, 104, 109, 134, 125, 127,105, 120, 107, 129,
116, 108, 132, 103, 136, 118, 102, 120, 114,105, 115, 132, 145, 119, 121, 112, 139, 125, 138, 109, 132, 134,156, 106, 117, 127, 144,
139, 139, 119, 140, 83, 110, 102,123,107, 143, 115, 136, 118, 139, 123, 112, 118, 125, 109, 119, 133,112, 114, 122, 109, 106, 123, 116,
131, 127, 115, 118, 112, 135,115, 146, 137, 116, 103, 144, 83, 123, 111, 110,
111, 100, 154,136, 100, 118, 119, 133, 134, 106, 129, 126, 110, 111, 109, 141,120, 117, 106, 149, 122, 122, 110, 118, 127, 121, 114, 125,
126,114, 140, 103, 130, 141, 117, 106, 114, 121,
114, 133, 137, 92,121, 112, 146, 97, 137, 105, 98, 117, 112, 81, 97, 139, 113,134, 106, 144, 110, 137, 137, 111, 104, 117, 100,
111, 101, 110,105, 129, 137, 112, 120, 113, 133, 112, 83, 94, 146, 133, 101,131, 116, 111, 84, 137, 115, 122, 106, 144, 109, 123,
116, 111,111, 133, 150]
# 2、创建画布
plt.figure(figsize=(20, 8), dpi=80)
# 3、绘制直方图
distance = 2
group_num = int((max(time) - min(time)) / distance)
plt.hist(time, bins=group_num, density=True)
# 修改x轴刻度
plt.xticks(range(min(time), max(time) + 2, distance))
# 添加网格
plt.grid(linestyle="--", alpha=0.5)
# 4、显示图像
plt.show() 
饼图
plt.pie(x, labels=, autopct=,color)
参数:x数量,自动计算百分比 labels:每部分名称 autopct:占比显示指定%1.2f%% color:每部分颜色
# 1、准备数据
movie_name = ['雷神3:诸神黄昏','正义联盟','东方快车谋杀案','寻梦环游记','全球风暴','降魔传','追捕','七十七天','密战','狂兽','其它']
place_count = [60605,54546,45819,28243,13270,9945,7679,6799,6101,4621,20105]
# 2、创建画布
plt.figure(figsize=(20, 8), dpi=80)
# 3、绘制饼图
plt.pie(place_count, labels=movie_name, colors=['b','r','g','y','c','m','y','k','c','g','y'], autopct="%1.2f%%")
# 显示图例
plt.legend()
plt.axis('equal')
# 4、显示图像
plt.show() 
plt.axis('equal') 为了让显示的饼图保持圆形,需要添加axis保证长宽一样
3、nump
numpy的array类型是ndarray,ndarray中的所有元素的类型都是相同的,而Python列表中的元素类型是任意的,所以ndarray在存储元素时内存可以连续,而python原生list就只能通过寻址方式找到下一个元素,这虽然也导致了在通用性能方面Numpy的ndarray不及Python原生list,但在科学计算中,Numpy的ndarray就可以省掉很多循环语句。
ndarray 支持并行化运算(向量化运算)
Numpy底层使用C语言编写,内部解除了GIL(全局解释器锁),其对数组的操作速度不受Python解释器的限制
>>> import numpy as np
>>> score = np.array([[80, 89, 86, 67, 79],
... [78, 97, 89, 67, 81],
... [90, 94, 78, 67, 74],
... [91, 91, 90, 67, 69],
... [76, 87, 75, 67, 86],
... [70, 79, 84, 67, 84],
... [94, 92, 93, 67, 64],
... [86, 85, 83, 67, 80]])
>>> type(score)
ndarray与Python原生list运算效率对比
>>> import random
>>> import time
>>> python_list = []
>>>
>>> for i in range(100000000):
... python_list.append(random.random())
...
>>> ndarray_list = np.array(python_list)
>>> len(ndarray_list)
100000000
>>> t1 = time.time()
>>> a = sum(python_list)
>>> t2 = time.time()
>>> d1 = t2 - t1
>>> # ndarray求和
... t3 = time.time()
>>> b = np.sum(ndarray_list)
>>> t4 = time.time()
>>> d2 = t4 - t3
>>> d1
0.3830413818359375
>>> d2
0.03506970405578613
ndarray的属性
| 属性名字 | 解释 |
| ndarray.shape | 数组维度的元组 |
| ndarray.ndim | 数组维数 |
| ndarray.size | 数组中的元素数量 |
| ndarray.itemsize | 一个数组元素的长度(字节) |
| ndarray.dtype | 数组元素的类型 |
>>> score.shape
(8, 5)
>>> score.dtype
dtype('int64')
>>> score.itemsize
8# 创建数组的时候指定类型
np.array([1.1, 2.2, 3.3], dtype="float32") #第一种
np.array([1.1, 2.2, 3.3], dtype=np.float32)#第二种如不指定,整数默认int64,小数默认float64
>>> arr = np.array(['python','tensor','scikit'],dtype=np.string_)
>>> arr
array([b'python', b'tensor', b'scikit'], dtype='|S6')生成数组的方法
1)生成0和1的数组 np.zeros和np.ones
>>> np.zeros(shape=(3, 4), dtype="float32")
array([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]], dtype=float32)
>>> np.ones(shape=[2, 3], dtype=np.int32)
array([[1, 1, 1],
[1, 1, 1]], dtype=int32)
2)从现有数组生成
np.array () np.copy()深拷贝
np.asarray()浅拷贝
>>> data1 = np.array(score)
>>> data2 = np.asarray(score)
>>> data3 = np.copy(score)
>>> score[3, 1] = 10000
>>> data1
array([[80, 89, 86, 67, 79],
[78, 97, 89, 67, 81],
[90, 94, 78, 67, 74],
[91, 91, 90, 67, 69],
[76, 87, 75, 67, 86],
[70, 79, 84, 67, 84],
[94, 92, 93, 67, 64],
[86, 85, 83, 67, 80]])
>>> data2
array([[ 80, 89, 86, 67, 79],
[ 78, 97, 89, 67, 81],
[ 90, 94, 78, 67, 74],
[ 91, 10000, 90, 67, 69],
[ 76, 87, 75, 67, 86],
[ 70, 79, 84, 67, 84],
[ 94, 92, 93, 67, 64],
[ 86, 85, 83, 67, 80]])
>>> data3
array([[80, 89, 86, 67, 79],
[78, 97, 89, 67, 81],
[90, 94, 78, 67, 74],
[91, 91, 90, 67, 69],
[76, 87, 75, 67, 86],
[70, 79, 84, 67, 84],
[94, 92, 93, 67, 64],
[86, 85, 83, 67, 80]])
data2是由asarray函数拷贝得到,它是浅拷贝,所以当改变原数组score时只有data2发生改变
3)生成固定范围数组 linspace arange
np.linspace(start, stop, num, endpoint,restep,dtype)
num:生成等间隔样例的数量,默认是50 ,endpoint:为true则包含stop的值
>>> np.linspace(0, 10, 5)
array([ 0. , 2.5, 5. , 7.5, 10. ])
>>> np.arange(0, 11, 5)
array([ 0, 5, 10])4)生成随机数组 np.random模块
均匀分布
np.random.rand(d0,d1,...dn) 返回[0.0, 1.0)内的一组均匀分布的数
np.random.uniform(low=0.0, high=1.0,size=None) 从一个均为分布[low,high)中随机采样,定义域是左闭右开
参数:low默认值为0,high默认值为1,size输出样本个数类型为int或者元组,默认为1
返回值:ndarray类型,其形状和参数size中描述一致
np.random.randint(low,high=None,size=None,dtype='I') 从一个均匀分布中随机采样生成一个整数或N维整数数组,取数范围:若high不为None时,取[low,high)之间随机整数,否则取值[0,low)之间随机整数。
data1 = np.random.uniform(low=-1, high=1, size=1000000)正态分布
np.random.randn(d0,d1,...dn) 从标准正态分布中返回一个或多个样本值
np.random.normal(loc=0.0,scale=1.0,size=None)
参数:loc类型float表示概率分布的均值,scale类型float表示概率分布的标准差,size类型int或元组,表示输出的shape,默认为None且只输出一个值
np.random.standard_normal(size=None) 返回指定形状的标准正态分布的数组
data2 = np.random.normal(loc=1.75, scale=0.1, size=1000000)
# 1、创建画布
plt.figure(figsize=(20, 8), dpi=80)
# 2、绘制直方图
plt.hist(data2, 1000)
# 3、显示图像
plt.show()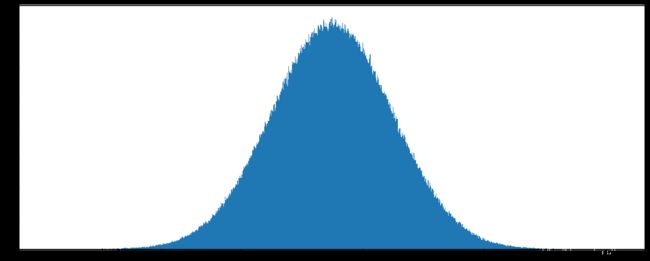
5)数组的索引、切片
#随机生成8只股票2周的交易日涨幅数据
stock_change = np.random.normal(loc=0, scale=1, size=(8, 10))
# 获取第一个股票的前3个交易日的涨跌幅数据
stock_change[0, :3]>>> a1 = np.array([ [[1,2,3],[4,5,6]], [[12,3,34],[5,6,7]]])
>>> a1
array([[[ 1, 2, 3],
[ 4, 5, 6]],
[[12, 3, 34],
[ 5, 6, 7]]])
>>> a1.shape
(2, 2, 3)>>> a1[1, 0, 2] = 100000
>>> a1
array([[[ 1, 2, 3],
[ 4, 5, 6]],
[[ 12, 3, 100000],
[ 5, 6, 7]]])形状修改
行变成列,列变成行
ndarray.reshape()
# 需求:让刚才的股票行、日期列反过来,变成日期行,股票列
stock_change.reshape((10, 8)) #只是形状改变,并没有将行列转换
stock_change.reshape([-1,20]) #数组的形状被修改为:(4,20), -1:表示通过待计算ndarray.resize()
resize()与reshape的区别在于,resize()没有返回值,对原始的ndarray进行了修改。而reshape() 返回新的ndarray,原始数据没有改变。
ndarray.T 数组转置
类型修改
ndarray.astype(type)
ndarray.tostring([order]) 序列化到本地
ndarray.tobytes([order])
数组去重
ndarray.unique
>>> temp = np.array([[1, 2, 3, 4],[3, 4, 5, 6]])
>>> np.unique(temp)
array([1, 2, 3, 4, 5, 6])
>>> set(temp.flatten())
{1, 2, 3, 4, 5, 6}逻辑运算
布尔索引
>>> stock_change = np.random.normal(loc=0, scale=1, size=(8, 10))
# 逻辑判断, 如果涨跌幅大于0.5就标记为True 否则为False
>>> stock_change > 0.5
array([[False, False, False, True, False, True, True, False, True,
False],
[False, False, False, True, True, False, True, True, False,
True],
[ True, False, False, False, False, True, False, False, False,
True],
[ True, True, False, False, False, False, False, False, True,
False],
[ True, False, False, False, False, False, False, True, False,
True],
[False, False, False, False, True, False, False, False, True,
False],
[False, False, True, True, True, True, False, False, False,
False],
[False, True, True, False, False, False, False, True, False,
True]])
>>> stock_change[stock_change > 0.5] = 1.1
>>> stock_change
array([[-0.01387818, 0.27120087, -0.1862971 , 1.1 , -0.58392957,
1.1 , 1.1 , -1.73164974, 1.1 , 0.02775165],
[-0.80623239, -1.31706205, -0.10204322, 1.1 , 1.1 ,
-0.640727 , 1.1 , 1.1 , -0.1625105 , 1.1 ],
[ 1.1 , 0.21420813, -0.58877815, -0.60933658, -0.44249993,
1.1 , 0.31974508, 0.16488008, -0.16702772, 1.1 ],
[ 1.1 , 1.1 , -0.84312132, -0.06335122, -1.61259734,
-0.33147976, -2.0695024 , -0.23299053, 1.1 , -0.19205454],
[ 1.1 , -0.28397673, -2.15291922, -0.02238511, 0.01837233,
-2.16932483, -0.37276037, 1.1 , -1.0064093 , 1.1 ],
[-0.19698235, -1.04438635, -1.627429 , -0.62379489, 1.1 ,
-0.32763191, -0.03878634, -1.20425515, 1.1 , -0.37655964],
[-0.00277414, 0.31954587, 1.1 , 1.1 , 1.1 ,
1.1 , -0.45117565, -0.499581 , -1.12060505, -0.27064282],
[-1.05976712, 1.1 , 1.1 , -0.16950335, 0.49222575,
-0.19702656, -0.98556976, 1.1 , -0.46226706, 1.1 ]])
# 判断stock_change[0:2, 0:5]是否全是上涨的
>>> stock_change[0:2, 0:5] > 0
array([[False, True, False, True, False],
[False, False, False, True, True]])
通用判断函数
np.all() 只要有一个False就返回False,只有全是True才返回True
np.any() 只要只有一个True就返回True,只有全是False才返回False
>>> np.all(stock_change[0:2, 0:5] > 0)
False
>>> np.any(stock_change[:5, :] > 0)
True
np.where(三元运算符)
# 判断前四个股票前四天的涨跌幅 大于0的置为1,否则为0
>>> temp = stock_change[:4, :4]
>>> temp
array([[-0.01387818, 0.27120087, -0.1862971 , 1.1 ],
[-0.80623239, -1.31706205, -0.10204322, 1.1 ],
[ 1.1 , 0.21420813, -0.58877815, -0.60933658],
[ 1.1 , 1.1 , -0.84312132, -0.06335122]])
>>> np.where(temp > 0, 1, 0)
array([[0, 1, 0, 1],
[0, 0, 0, 1],
[1, 1, 0, 0],
[1, 1, 0, 0]])
>>> temp > 0
array([[False, True, False, True],
[False, False, False, True],
[ True, True, False, False],
[ True, True, False, False]])
>>> np.where([[ True, False, True, True],
... [ True, True, True, True],
... [False, False, True, False],
... [ True, False, True, False]], 1, 0)
array([[1, 0, 1, 1],
[1, 1, 1, 1],
[0, 0, 1, 0],
[1, 0, 1, 0]])复合逻辑需要结合np.logical_and和np.logical_or
# 判断前四个股票前四天的涨跌幅 大于0.5并且小于1的,换为1,否则为0
# 判断前四个股票前四天的涨跌幅 大于0.5或者小于-0.5的,换为1,否则为0
>>> np.logical_and(temp > 0.5, temp < 1)
array([[False, False, False, False],
[False, False, False, False],
[False, False, False, False],
[False, False, False, False]])
>>> np.where([[False, False, False, False],
... [False, False, False, False],
... [False, False, False, False],
... [False, False, False, False]], 1, 0)
array([[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0]])
>>> np.where(np.logical_and(temp > 0.5, temp < 1), 1, 0)
array([[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0]])
>>> np.logical_or(temp > 0.5, temp < -0.5)
array([[False, False, False, True],
[ True, True, False, True],
[ True, False, True, True],
[ True, True, True, False]])
>>> np.where(np.logical_or(temp > 0.5, temp < -0.5), 11, 3)
array([[ 3, 3, 3, 11],
[11, 11, 3, 11],
[11, 3, 11, 11],
[11, 11, 11, 3]])
统计计算
min, max, mean, median, var, std
>>> temp
array([[ 1.1 , 0.24525587, 1.1 , 1.1 ],
[-0.22294568, 1.1 , -0.3059287 , 1.1 ],
[-0.56743559, -0.29969952, 1.1 , 1.1 ],
[-0.76954087, -0.00399729, -0.70574717, -0.27136093]])
>>> temp.max(axis=0)
array([1.1, 1.1, 1.1, 1.1])
>>> np.max(temp, axis=-1)
array([ 1.1 , 1.1 , 1.1 , -0.00399729])
>>> np.max(temp, axis=1)
array([ 1.1 , 1.1 , 1.1 , -0.00399729])
>>> np.argmax(temp, axis=-1)
array([0, 1, 2, 1])axis=0代表列,axis =1代表行
>>> np.min(temp,axis=1)
array([ 0.24525587, -0.3059287 , -0.56743559, -0.76954087])
>>> np.std(temp,axis=1)
array([0.37011506, 0.68284917, 0.77260448, 0.31533092])
>>> np.mean(temp,axis=1)
array([ 0.88631397, 0.4177814 , 0.33321622, -0.43766156])数组与数的运算
>>> arr = np.array([[1,2,3,2,1,4],[5,6,1,2,3,1]])
>>> arr/10
array([[0.1, 0.2, 0.3, 0.2, 0.1, 0.4],
[0.5, 0.6, 0.1, 0.2, 0.3, 0.1]])
#列表和一个数t相乘会复制t倍
>>> a = [1,2,3,4,5]
>>> a*10
[1, 2, 3, 4, 5, 1, 2, 3, 4, 5, 1, 2, 3, 4, 5, 1, 2, 3, 4, 5, 1, 2, 3, 4, 5, 1, 2, 3, 4, 5, 1, 2, 3, 4, 5, 1, 2, 3, 4, 5, 1, 2, 3, 4, 5, 1, 2, 3, 4, 5]
数组与数组的运算
广播机制 当操作两个数组时,numpy会逐个比较它们的shape(构成的元组tuple),只有在下述情况下,两个数组才能够进行数组与数组的运算
1、维度相等
2、shape(其中相对应的一个地方为1)
例如:
Image(3d array): 256*256*3 Scale(1d array): 3 Result(3d array):256*256*3
A (4d array):9*1*7*1 B (3d array): 8*1*5 Result (4d array):9*8*7*5
A (2d array): 5*4 B (1d array): 1 Result (2d array): 5*4
A (4d array): 15*3*5 B (3d array): 15*1*1 Result (4d array): 15*3*5
>>> arr1 = np.array([[1, 2, 3, 2, 1, 4], [5, 6, 1, 2, 3, 1]])
>>> arr2 = np.array([[1], [3]])
>>> arr1 + arr2
array([[2, 3, 4, 3, 2, 5],
[8, 9, 4, 5, 6, 4]])
>>> arr1 * arr2
array([[ 1, 2, 3, 2, 1, 4],
[15, 18, 3, 6, 9, 3]])
>>> arr1 / arr2
array([[1. , 2. , 3. , 2. , 1. ,
4. ],
[1.66666667, 2. , 0.33333333, 0.66666667, 1. ,
0.33333333]])矩阵
矩阵mat 必须是二维的
np.mat()将数组转换成矩阵类型
>>> data = np.array([[80, 86],
... [82, 80],
... [85, 78],
... [90, 90],
... [86, 82],
... [82, 90],
... [78, 80],
... [92, 94]])
>>> data_mat = np.mat([[80, 86],
... [82, 80],
... [85, 78],
... [90, 90],
... [86, 82],
... [82, 90],
... [78, 80],
... [92, 94]])
>>> type(data_mat)
矩阵乘法
np.matmul np.dot
>>> weights = np.array([[0.3], [0.7]])
>>> weights_mat = np.mat([[0.3], [0.7]])
>>> data = np.array([[80, 86], [82, 80], [85, 78],[90, 90], [86, 82],[82, 90],
[78, 80],[92, 94]])
>>> data_mat = np.mat([[80, 86],[82, 80],[85, 78],[90, 90],[86, 82],[82, 90],
[78, 80],[92, 94]])
>>> np.matmul(data, weights)
array([[84.2],
[80.6],
[80.1],
[90. ],
[83.2],
[87.6],
[79.4],
[93.4]])
>>> np.dot(data, weights)
array([[84.2],
[80.6],
[80.1],
[90. ],
[83.2],
[87.6],
[79.4],
[93.4]])
>>> data_mat * weights_mat
matrix([[84.2],
[80.6],
[80.1],
[90. ],
[83.2],
[87.6],
[79.4],
[93.4]])
>>> data @ weights
array([[84.2],
[80.6],
[80.1],
[90. ],
[83.2],
[87.6],
[79.4],
[93.4]])
合并与分割
1)合并
numpy.hstack(tup) 水平拼接,列合并,行数不变
numpy.vstack(tup) 垂直拼接,行合并,列数不变
numpy.concatenate((a1,a2,...), axis=0) axis =1列合并 axis=0行合并
>>> a = np.array([1,2,3])
>>> b = np.array([2,3,4])
>>> np.hstack((a,b))
array([1, 2, 3, 2, 3, 4])
>>> a = np.array([[1],[2],[3]])
>>> b = np.array([[2],[3],[4]])
>>> np.hstack((a,b))
array([[1, 2],
[2, 3],
[3, 4]])hstack按照b的行数,b是1行的最后按顺序拼接出来一维数组;b是2行的,按顺序拼接出来2行2列的数组。
>>> a = np.array([1,2,3])
>>> b = np.array([2,3,4])
>>> np.vstack((a,b))
array([[1, 2, 3],
[2, 3, 4]])
>>> a = np.array([[1],[2],[3]])
>>> b = np.array([[2],[3],[4]])
>>> np.vstack((a,b))
array([[1],
[2],
[3],
[2],
[3],
[4]])vstack按照b的列数,进行行拼接,b是三列的拼接结果是2行三列的数组,b是3行1列的拼接结果就是6行1列的数组
>>> a = np.array([[1,2],[3,4]])
>>> b = np.array([[5,6]])
>>> np.concatenate((a,b),axis=0)
array([[1, 2],
[3, 4],
[5, 6]])
>>> np.concatenate((a,b.T),axis=1)
array([[1, 2, 5],
[3, 4, 6]])concatenate根据axis的取值拼接方式不同,axis=0,同vstack;axis=1,同hstack
>>> a = stock_change[:2, 0:4]
>>> b = stock_change[4:6, 0:4]
>>> a
array([[ 1.1 , 0.24525587, 1.1 , 1.1 ],
[-0.22294568, 1.1 , -0.3059287 , 1.1 ]])
>>> b
array([[-0.47253499, 1.1 , -0.84584895, 1.1 ],
[-1.60643683, 0.25277852, -0.42706272, 0.14009384]])
>>> a.reshape((-1, 2))
array([[ 1.1 , 0.24525587],
[ 1.1 , 1.1 ],
[-0.22294568, 1.1 ],
[-0.3059287 , 1.1 ]])
>>> np.hstack((a, b))
array([[ 1.1 , 0.24525587, 1.1 , 1.1 , -0.47253499,
1.1 , -0.84584895, 1.1 ],
[-0.22294568, 1.1 , -0.3059287 , 1.1 , -1.60643683,
0.25277852, -0.42706272, 0.14009384]])
>>> np.concatenate((a, b), axis=1)
array([[ 1.1 , 0.24525587, 1.1 , 1.1 , -0.47253499,
1.1 , -0.84584895, 1.1 ],
[-0.22294568, 1.1 , -0.3059287 , 1.1 , -1.60643683,
0.25277852, -0.42706272, 0.14009384]])
>>> np.vstack((a, b))
array([[ 1.1 , 0.24525587, 1.1 , 1.1 ],
[-0.22294568, 1.1 , -0.3059287 , 1.1 ],
[-0.47253499, 1.1 , -0.84584895, 1.1 ],
[-1.60643683, 0.25277852, -0.42706272, 0.14009384]])
>>> np.concatenate((a, b), axis=0)
array([[ 1.1 , 0.24525587, 1.1 , 1.1 ],
[-0.22294568, 1.1 , -0.3059287 , 1.1 ],
[-0.47253499, 1.1 , -0.84584895, 1.1 ],
[-1.60643683, 0.25277852, -0.42706272, 0.14009384]])
2)分割
numpy.split(ary,indices_or_sections,axis=0)
>>> x = np.arange(9.0)
>>> x
array([0., 1., 2., 3., 4., 5., 6., 7., 8.])
>>> np.split(x,3)
[array([0., 1., 2.]), array([3., 4., 5.]), array([6., 7., 8.])]
>>> x=np.arange(8.0)
>>> x
array([0., 1., 2., 3., 4., 5., 6., 7.])
>>> np.split(x,[3,5,6,10])
[array([0., 1., 2.]), array([3., 4.]), array([5.]), array([6., 7.]), array([], dtype=float64)]numpy读取
读取文件
genfromtx(name,[dtype,comments])
| id | value1 | value2 | value3 |
| 1 | 123 | 1.4 | 23 |
| 2 | 110 | 18 | |
| 3 | 2.1 | 19 |
data = np.genfromtxt("test.csv", delimiter=",")
array([[ nan, nan, nan, nan],
[ 1. , 123. , 1.4, 23. ],
[ 2. , 110. , nan, 18. ],
[ 3. , nan, 2.1, 19. ]])type(data[2, 2]) numpy.float64
处理缺失值 nan
读取本地文件为float的时候,如果由缺失(或者为None),就会出现nan,课题替换为均值或者中指,也可以直接删除
def fill_nan_by_column_mean(t):
for i in range(t.shape[1]):
# 计算nan的个数
nan_num = np.count_nonzero(t[:, i][t[:, i] != t[:, i]])
if nan_num > 0:
now_col = t[:, i]
# 求和
now_col_not_nan = now_col[np.isnan(now_col) == False].sum()
# 和/个数
now_col_mean = now_col_not_nan / (t.shape[0] - nan_num)
# 赋值给now_col
now_col[np.isnan(now_col)] = now_col_mean
# 赋值给t,即更新t的当前列
t[:, i] = now_col
return t
fill_nan_by_column_mean(data)
#结果
array([[ 2. , 116.5 , 1.75, 20. ],
[ 1. , 123. , 1.4 , 23. ],
[ 2. , 110. , 1.75, 18. ],
[ 3. , 116.5 , 2.1 , 19. ]])
pandas
pandas是专用于数据挖掘的开源python库,以numpy位基础,借力numpy模块在计算方面性能高的优势,基于matplotlib能够简便画图,并且有独特的数据结构,处理数据便捷,读取文件方便。
核心数据结构:DataFrame 、Panel、 Series
DataFrame 既有行索引又有列索引的二维数组
>>> import pandas as pd
>>> import numpy as np
>>> stock_change = np.random.normal(0, 1, (10, 5))
>>> stock_change
array([[ 1.35840604, 0.27789006, -0.30482702, 0.90812678, 1.1425173 ],
[ 0.73080977, -0.39444093, 0.66884689, 1.04025647, 1.13530876],
[ 0.17205492, 2.41449821, -1.22396258, 2.05483666, 1.17917289],
[ 0.00725994, 0.31754389, -0.34829121, -1.8746324 , -0.37256308],
[-0.46480991, -0.01772143, -0.2360607 , -0.53309056, -0.26258666],
[-1.59303919, 1.6697301 , -0.96950195, 0.72228622, 0.20094031],
[ 0.78198024, -0.24024468, 0.26182951, 0.52273482, 0.700006 ],
[ 0.13555158, 1.76693575, 0.31272262, 1.77118924, 1.713967 ],
[-1.24166174, -0.61934163, 0.29293032, 0.66320501, -0.06955791],
[-0.68043017, 1.2872314 , -1.64667051, 0.72407127, 2.83003405]])
>>> pd.DataFrame(stock_change)
0 1 2 3 4
0 1.358406 0.277890 -0.304827 0.908127 1.142517
1 0.730810 -0.394441 0.668847 1.040256 1.135309
2 0.172055 2.414498 -1.223963 2.054837 1.179173
3 0.007260 0.317544 -0.348291 -1.874632 -0.372563
4 -0.464810 -0.017721 -0.236061 -0.533091 -0.262587
5 -1.593039 1.669730 -0.969502 0.722286 0.200940
6 0.781980 -0.240245 0.261830 0.522735 0.700006
7 0.135552 1.766936 0.312723 1.771189 1.713967
8 -1.241662 -0.619342 0.292930 0.663205 -0.069558
9 -0.680430 1.287231 -1.646671 0.724071 2.830034增加行索引
# 添加行索引
>>> stock = ["股票{}".format(i) for i in range(10)]
>>> pd.DataFrame(stock_change, index=stock)
0 1 2 3 4
股票0 -0.477969 0.021318 0.703158 -0.111374 0.135436
股票1 -0.675086 -0.533490 -0.746490 -1.118842 -0.607720
股票2 -0.003302 1.256507 0.084343 1.023596 0.601153
股票3 -0.797104 -0.117850 -0.134211 -0.519038 -2.058995
股票4 -2.142438 0.624052 -1.367046 0.280257 0.980362
股票5 0.776495 1.468952 -1.826556 1.065503 1.062864
股票6 0.434640 -0.411476 0.483058 1.682337 -0.725043
股票7 1.338271 -0.364083 2.947543 -0.639943 0.030552
股票8 0.211280 -0.263985 -0.026465 1.296534 0.217590
股票9 1.073487 2.078937 0.067059 0.617420 1.411101添加列索引
使用pd.date_range():用于生成一组连续的时间序列
date_range(start=None,end=None,periods=None,freq='B')
参数 : start:开始时间 end:结束时间 periods:时间天数 freq:递进单位,默认1天 ,‘B’默认略过周末
>>> date = pd.date_range(start="20180101", periods=5, freq="B")
>>> date
DatetimeIndex(['2018-01-01', '2018-01-02', '2018-01-03', '2018-01-04',
'2018-01-05'],
dtype='datetime64[ns]', freq='B')
>>> data = pd.DataFrame(stock_change, index=stock, columns=date)
>>> data
2018-01-01 2018-01-02 2018-01-03 2018-01-04 2018-01-05
股票0 -0.477969 0.021318 0.703158 -0.111374 0.135436
股票1 -0.675086 -0.533490 -0.746490 -1.118842 -0.607720
股票2 -0.003302 1.256507 0.084343 1.023596 0.601153
股票3 -0.797104 -0.117850 -0.134211 -0.519038 -2.058995
股票4 -2.142438 0.624052 -1.367046 0.280257 0.980362
股票5 0.776495 1.468952 -1.826556 1.065503 1.062864
股票6 0.434640 -0.411476 0.483058 1.682337 -0.725043
股票7 1.338271 -0.364083 2.947543 -0.639943 0.030552
股票8 0.211280 -0.263985 -0.026465 1.296534 0.217590
股票9 1.073487 2.078937 0.067059 0.617420 1.411101values:直接获取data其中array的值
>>> data.values
array([[-0.47796886, 0.02131753, 0.70315835, -0.11137394, 0.13543559],
[-0.67508601, -0.53349009, -0.74649048, -1.11884226, -0.60771963],
[-0.00330154, 1.25650724, 0.08434262, 1.02359564, 0.6011529 ],
[-0.79710378, -0.11785045, -0.134211 , -0.51903755, -2.05899535],
[-2.14243829, 0.62405225, -1.36704598, 0.28025671, 0.98036153],
[ 0.7764954 , 1.46895214, -1.82655611, 1.0655035 , 1.06286425],
[ 0.43464022, -0.41147574, 0.48305821, 1.68233673, -0.72504321],
[ 1.33827141, -0.36408344, 2.94754309, -0.6399431 , 0.03055175],
[ 0.21127964, -0.26398452, -0.02646468, 1.29653383, 0.21759008],
[ 1.07348737, 2.07893716, 0.06705887, 0.61741983, 1.4111011 ]])DataFrame属性
shape、index、columns、values、T
方法: head() tail()
代码段 小部件
修改行列索引值
不能单独修改某一行列的索引,例如data.index[3] = '股票_3' ,会报错
必须整体修改
>>> stock_ = ["股票_{}".format(i) for i in range(10)]
>>> data.index = stock_
>>> data.index
Index(['股票_0', '股票_1', '股票_2', '股票_3', '股票_4', '股票_5', '股票_6', '股票_7', '股票_8',
'股票_9'],
dtype='object')
>>> data
2018-01-01 2018-01-02 2018-01-03 2018-01-04 2018-01-05
股票_0 -0.477969 0.021318 0.703158 -0.111374 0.135436
股票_1 -0.675086 -0.533490 -0.746490 -1.118842 -0.607720
股票_2 -0.003302 1.256507 0.084343 1.023596 0.601153
股票_3 -0.797104 -0.117850 -0.134211 -0.519038 -2.058995
股票_4 -2.142438 0.624052 -1.367046 0.280257 0.980362
股票_5 0.776495 1.468952 -1.826556 1.065503 1.062864
股票_6 0.434640 -0.411476 0.483058 1.682337 -0.725043
股票_7 1.338271 -0.364083 2.947543 -0.639943 0.030552
股票_8 0.211280 -0.263985 -0.026465 1.296534 0.217590
股票_9 1.073487 2.078937 0.067059 0.617420 1.411101重设索引
reset_index(drop=False) 设置新的下标索引,drop默认为False,不删除原来索引,为True删除原来的索引
>>> data.reset_index(drop=False)
index 2018-01-01 00:00:00 ... 2018-01-04 00:00:00 2018-01-05 00:00:00
0 股票_0 -0.477969 ... -0.111374 0.135436
1 股票_1 -0.675086 ... -1.118842 -0.607720
2 股票_2 -0.003302 ... 1.023596 0.601153
3 股票_3 -0.797104 ... -0.519038 -2.058995
4 股票_4 -2.142438 ... 0.280257 0.980362
5 股票_5 0.776495 ... 1.065503 1.062864
6 股票_6 0.434640 ... 1.682337 -0.725043
7 股票_7 1.338271 ... -0.639943 0.030552
8 股票_8 0.211280 ... 1.296534 0.217590
9 股票_9 1.073487 ... 0.617420 1.411101
[10 rows x 6 columns]以某列值设置为新的索引
set_index(keys,drop=True)
参数:keys:列索引名或者列索引名称的列表
drop:boolean,default True当做新的索引,删除原来的列
>>> df = pd.DataFrame({'month': [1, 4, 7, 10],
'year': [2012, 2014, 2013, 2014],
'sale':[55, 40, 84, 31]})
>>> df
month sale year
0 1 55 2012
1 4 40 2014
2 7 84 2013
3 10 31 2014
# 以月份设置新的索引
>>> df.set_index("month", drop=True)
sale year
month
1 55 2012
4 40 2014
7 84 2013
10 31 2014
>>> new_df = df.set_index(["year", "month"])
# 设置多个索引,以年和月份
>>> new_df.index
MultiIndex(levels=[[2012, 2013, 2014], [1, 4, 7, 10]],
labels=[[0, 2, 1, 2], [0, 1, 2, 3]],
names=['year', 'month'])
>>> new_df.index.names
FrozenList(['year', 'month'])
>>> new_df.index.levels
FrozenList([[2012, 2013, 2014], [1, 4, 7, 10]])
>>> new_df
sale
year month
2012 1 55
2014 4 40
2013 7 84
2014 10 31MultiIndex 多级或分层索引对象 names:levels的名称 levels:每个level的元组值
Panel
class pandas.Panel(data=None,items = None,major_axis=None,minor_axis=None,copy=False,dtype=None)
存储3维数组的Panel结构
FutureWarning:
Panel is deprecated and will be removed in a future version.
The recommended way to represent these types of 3-dimensional data are with a MultiIndex on a DataFrame, via the Panel.to_frame() method
Alternatively, you can use the xarray package http://xarray.pydata.org/en/stable/.
Pandas provides a `.to_xarray()` method to help automate this conversion.
现在使用panel会有一个警告,这个模块将会被移除,不推荐使用。但简单记录一下,别看到了不知道是啥。
>>> p = pd.Panel(np.arange(24).reshape(4,3,2),
items=list('ABCD'),
major_axis=pd.date_range('20130101', periods=3),
minor_axis=['first', 'second'])
Warning (from warnings module):
File "D:\install\anaconda3\lib\idlelib\run.py", line 357
exec(code, self.locals)
FutureWarning:
Panel is deprecated and will be removed in a future version.
The recommended way to represent these types of 3-dimensional data are with a MultiIndex on a DataFrame, via the Panel.to_frame() method
Alternatively, you can use the xarray package http://xarray.pydata.org/en/stable/.
Pandas provides a `.to_xarray()` method to help automate this conversion.
>>> p
Dimensions: 4 (items) x 3 (major_axis) x 2 (minor_axis)
Items axis: A to D
Major_axis axis: 2013-01-01 00:00:00 to 2013-01-03 00:00:00
Minor_axis axis: first to second
>>> p['A']
first second
2013-01-01 0 1
2013-01-02 2 3
2013-01-03 4 5
>>> p['D']
first second
2013-01-01 18 19
2013-01-02 20 21
2013-01-03 22 23
>>> p.major_xs("2013-01-01")
A B C D
first 0 6 12 18
second 1 7 13 19
>>> p.minor_xs("first")
A B C D
2013-01-01 0 6 12 18
2013-01-02 2 8 14 20
2013-01-03 4 10 16 22 items- axis 0,每个项目对应于内部包含的数据帧(DataFrame)。
major_ axis- axis 1,它是每个数据帧(DataFrame)的索引(行)。
minor_ axis- axis 2,它是每个数据帧(DataFrame)的列。
Series
series结构只有行索引
创建Series
通过已有数据创建
pd.Series(np.arange(10))
pd.Series([6.7,5.6,3,10,2], index=[1,2,3,4,5])
通过字典数据创建
pd.Series({'red':100,'blue':200,'green':500,'yellow':1000})
获取索引和值 index values
>>> data
2018-01-01 2018-01-02 2018-01-03 2018-01-04 2018-01-05
股票_0 -0.477969 0.021318 0.703158 -0.111374 0.135436
股票_1 -0.675086 -0.533490 -0.746490 -1.118842 -0.607720
股票_2 -0.003302 1.256507 0.084343 1.023596 0.601153
股票_3 -0.797104 -0.117850 -0.134211 -0.519038 -2.058995
股票_4 -2.142438 0.624052 -1.367046 0.280257 0.980362
股票_5 0.776495 1.468952 -1.826556 1.065503 1.062864
股票_6 0.434640 -0.411476 0.483058 1.682337 -0.725043
股票_7 1.338271 -0.364083 2.947543 -0.639943 0.030552
股票_8 0.211280 -0.263985 -0.026465 1.296534 0.217590
股票_9 1.073487 2.078937 0.067059 0.617420 1.411101
>>> sr = data.iloc[1, :]
>>> sr
2018-01-01 -0.675086
2018-01-02 -0.533490
2018-01-03 -0.746490
2018-01-04 -1.118842
2018-01-05 -0.607720
Freq: B, Name: 股票_1, dtype: float64
>>> sr.index
DatetimeIndex(['2018-01-01', '2018-01-02', '2018-01-03', '2018-01-04',
'2018-01-05'],
dtype='datetime64[ns]', freq='B')
>>> sr.values
array([-0.67508601, -0.53349009, -0.74649048, -1.11884226, -0.60771963])
>>> type(sr.values)
>>> pd.Series(np.arange(3, 9, 2), index=["a", "b", "c"])
a 3
b 5
c 7
dtype: int32
>>> pd.Series({'red':100, 'blue':200, 'green': 500, 'yellow':1000})
blue 200
green 500
red 100
yellow 1000
dtype: int64 基本数据操作
索引操作
1)直接索引 先列后行 直接使用行列索引名字的方式(先列后行)data['open']['2018-02-27']。不支持切片索引
#读取文件
>>> data = pd.read_csv("data = pd.read_csv("./stock_day/stock_day.csv")
#删除一些列
>>> data = data.drop(["ma5","ma10","ma20","v_ma5","v_ma10","v_ma20"], axis=1)
>>> data.head()
open high close low volume price_change p_change turnover
2018-02-27 23.53 25.88 24.16 23.53 95578.03 0.63 2.68 2.39
2018-02-26 22.80 23.78 23.53 22.80 60985.11 0.69 3.02 1.53
2018-02-23 22.88 23.37 22.82 22.71 52914.01 0.54 2.42 1.32
2018-02-22 22.25 22.76 22.28 22.02 36105.01 0.36 1.64 0.90
2018-02-14 21.49 21.99 21.92 21.48 23331.04 0.44 2.05 0.58
>>> data["open"]["2018-02-26"]
22.8
2)结合loc或者iloc使用索引
使用loc只能指定行列索引的名字
>>> data.loc["2018-02-26", "open"]
22.8使用iloc可以通过索引的下标去获取
>>> data.iloc[1, 0]
22.83)使用ix组合索引
# 获取行第1天到第4天,['open', 'close', 'high', 'low']这个四个指标的结果
>>> data.ix[:4, ['open', 'close', 'high', 'low']]
open close high low
2018-02-27 23.53 24.16 25.88 23.53
2018-02-26 22.80 23.53 23.78 22.80
2018-02-23 22.88 22.82 23.37 22.71
2018-02-22 22.25 22.28 22.76 22.02也可以使用loc和iloc来获取
>>> data.loc[data.index[0:4],['open','close','high','low']]
open close high low
2018-02-27 23.53 24.16 25.88 23.53
2018-02-26 22.80 23.53 23.78 22.80
2018-02-23 22.88 22.82 23.37 22.71
2018-02-22 22.25 22.28 22.76 22.02
>>> data.iloc[0:4,data.columns.get_indexer(['open','close','high','low'])]
open close high low
2018-02-27 23.53 24.16 25.88 23.53
2018-02-26 22.80 23.53 23.78 22.80
2018-02-23 22.88 22.82 23.37 22.71
2018-02-22 22.25 22.28 22.76 22.02赋值操作
>>> data.open = 100 #open列赋值为100
>>> data.iloc[1, 0] = 222
>>> data.head()
open high close low volume price_change p_change turnover
2018-02-27 100 25.88 24.16 23.53 95578.03 0.63 2.68 2.39
2018-02-26 222 23.78 23.53 22.80 60985.11 0.69 3.02 1.53
2018-02-23 100 23.37 22.82 22.71 52914.01 0.54 2.42 1.32
2018-02-22 100 22.76 22.28 22.02 36105.01 0.36 1.64 0.90
2018-02-14 100 21.99 21.92 21.48 23331.04 0.44 2.05 0.58排序
排序有两种形式:一种是对内容进行排序,一种对索引进行排序
df.sort_values(key=,ascending=) 对内容进行排序 ascending=False降序 ascending=True 升序
data.sort_values(by=["high", "p_change"], ascending=False).head()
open high close low volume price_change p_change turnover
2015-06-10 100 36.35 33.85 32.23 269033.12 0.51 1.53 9.21
2015-06-12 100 35.98 35.21 34.01 159825.88 0.82 2.38 5.47
2017-10-31 100 35.22 34.44 32.20 361660.88 2.38 7.42 9.05
2015-06-15 100 34.99 31.69 31.69 199369.53 -3.52 -10.00 6.82
2015-06-11 100 34.98 34.39 32.51 173075.73 0.54 1.59 5.92使用df.sort_index对索引进行排序
>>> data.sort_index().head()
open high close low volume price_change p_change turnover
2015-03-02 100 12.67 12.52 12.20 96291.73 0.32 2.62 3.30
2015-03-03 100 13.06 12.70 12.52 139071.61 0.18 1.44 4.76
2015-03-04 100 12.92 12.90 12.61 67075.44 0.20 1.57 2.30
2015-03-05 100 13.45 13.16 12.87 93180.39 0.26 2.02 3.19
2015-03-06 100 14.48 14.28 13.13 179831.72 1.12 8.51 6.16>>> sr = data["price_change"]
>>> sr.sort_values(ascending=False).head()
2015-06-09 3.03
2017-10-26 2.68
2015-05-21 2.57
2017-10-31 2.38
2017-06-22 2.36
Name: price_change, dtype: float64
>>> sr.sort_index().head()
2015-03-02 0.32
2015-03-03 0.18
2015-03-04 0.20
2015-03-05 0.26
2015-03-06 1.12
Name: price_change, dtype: float64
