Python 爬虫 PhantomJs 获取JS动态数据
图片不能显示
上篇文章我非常high的爬取了一个正常网页的数据
对是正常

这次研究的就是那些“不正常”的网页 当时是我太天真 后面发现水又深
介于现在JS H5的大趋势 大部分网站都是混入了JS数据加载 数据是延迟加载的
这样如果我们用原始的urllib.open(url) 加载出来的都是还没有加载js数据之前的 所以爆炸了
所以按照上篇文章那么正常的提取数据显然不可取了 那毕竟那是静态的 战场上 敌人也不会像抗日神剧剧情一样让你当靶子不是
我当时的想法就是要让让网页JS渲染数据加载完全了 我们才开始解析 这样才行 想想就行了 然而我并不会

后面查了一些资料
- 无非两种实现
1 分析JS源码 找出请求 自己模拟实现 难度比较高 麻烦
2 模拟浏览器实现 三方库多 简单 但是效率会慢一点
然后搜到了很多相关的库 这里使用的是 Selenium + PhantomJs 网上推荐比较多
- Selenium是一个用于Web应用程序测试的工具
- Phantom JS是一个服务器端的 JavaScript API 的 WebKit
看了一下Selenium的Api 发现没有PhantomJS 他也可以使用FireFox来实现如同PhantomJs的功能
介于网上都是推荐PhantomJS 所以我也这样实现
Selenium就像一个大容器 里面放着PhantomJs来实现JS的渲染 我们直接操作Selenium的Api就行
这次选取的目标是 淘宝模特的网站 为什么是这个呢 除了美女多
还有就是我学习的资料就是用的这个
Python学习的网站这个里面就是用这个作为实例
但是这个后续可能因为淘宝改版了网站结构 他的例子不能成功 所以我才研究JS的动态加载
开始套路 这里环境Windows
1 安装Selenium 用Pip 安装 如果Pip不能被找到 记得设置环境变量Python/Script
2 下载PhantomJs 然后将 解压后的执行文件放在被设置过环境变量的地方 不设置的话 后续代码就要设置 所以这里直接放进来方便

这里检查一下

能找到 说明Ok
下面是全部实现代码

#coding=utf-8
__author__ = 'Daemon'
import urllib2,re,os,datetime
from selenium import webdriver
class Spider:
def __init__(self):
self.page=1
self.dirName='MMSpider'
#这是一些配置 关闭loadimages可以加快速度 但是第二页的图片就不能获取了打开(默认)
cap = webdriver.DesiredCapabilities.PHANTOMJS
cap["phantomjs.page.settings.resourceTimeout"] = 1000
#cap["phantomjs.page.settings.loadImages"] = False
#cap["phantomjs.page.settings.localToRemoteUrlAccessEnabled"] = True
self.driver = webdriver.PhantomJS(desired_capabilities=cap)
def getContent(self,maxPage):
for index in range(1,maxPage+1):
self.LoadPageContent(index)
#获取页面内容提取
def LoadPageContent(self,page):
#记录开始时间
begin_time=datetime.datetime.now()
url="https://mm.taobao.com/json/request_top_list.htm?page="+str(page)
self.page+=1;
USER_AGENT='Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.130 Safari/537.36'
headers = {'User-Agent':USER_AGENT }
request=urllib2.Request(url,headers=headers)
response=urllib2.urlopen(request)
#正则获取
pattern_link=re.compile(r'.*?) r'
r'(.*?).*?'
r'.*?(.*?).*?'
r'(.*?)'
,re.S)
items=re.findall(pattern_link,response.read().decode('gbk'))
for item in items:
#头像,个人详情,名字,年龄,地区
print u'发现一位MM 名字叫%s 年龄%s 坐标%s'%(item[2],item[3],item[4])
print u'%s的个人主页是 %s'%(item[2],item[1])
print u'继续获取详情页面数据...'
#详情页面
detailPage=item[1]
name=item[2]
self.getDetailPage(detailPage,name,begin_time)
def getDetailPage(self,url,name,begin_time):
url='http:'+url
self.driver.get(url)
base_msg=self.driver.find_elements_by_xpath('//div[@class="mm-p-info mm-p-base-info"]/ul/li')
brief=''
for item in base_msg:
print item.text
brief+=item.text+'\n'
#保存个人信息
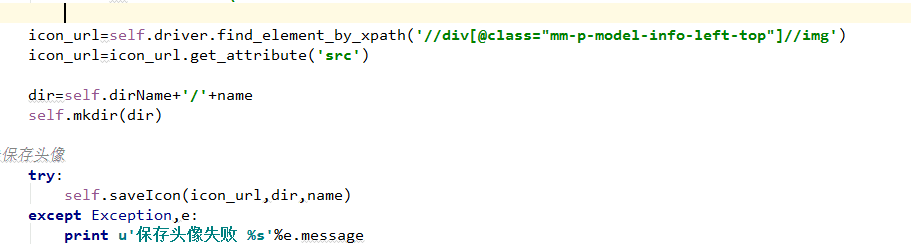
icon_url=self.driver.find_element_by_xpath('//div[@class="mm-p-model-info-left-top"]//img')
icon_url=icon_url.get_attribute('src')
dir=self.dirName+'/'+name
self.mkdir(dir)
#保存头像
try:
self.saveIcon(icon_url,dir,name)
except Exception,e:
print u'保存头像失败 %s'%e.message
#开始跳转相册列表
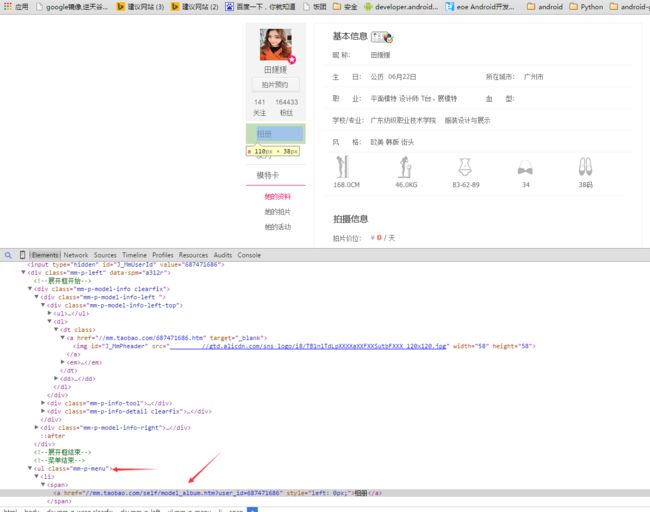
images_url=self.driver.find_element_by_xpath('//ul[@class="mm-p-menu"]//a')
images_url=images_url.get_attribute('href')
try:
self.getAllImage(images_url,name)
except Exception,e:
print u'获取所有相册异常 %s'%e.message
end_time=datetime.datetime.now()
#保存个人信息 以及耗时
try:self.saveBrief(brief,dir,name,end_time-begin_time)
except Exception,e:
print u'保存个人信息失败 %s'%e.message
#获取所有图片
def getAllImage(self,images_url,name):
self.driver.get(images_url)
#只获取第一个相册
photos=self.driver.find_element_by_xpath('//div[@class="mm-photo-cell-middle"]//h4/a')
photos_url=photos.get_attribute('href')
#进入相册页面获取相册内容
self.driver.get(photos_url)
images_all=self.driver.find_elements_by_xpath('//div[@id="mm-photoimg-area"]/a/img')
self.saveImgs(images_all,name)
def saveImgs(self,images,name):
index=1
print u'%s 的相册有%s张照片, 尝试全部下载....'%(name,len(images))
for imageUrl in images:
splitPath = imageUrl.get_attribute('src').split('.')
fTail = splitPath.pop()
if len(fTail) > 3:
fTail = "jpg"
fileName = self.dirName+'/'+name +'/'+name+ str(index) + "." + fTail
print u'下载照片地址%s '%fileName
self.saveImg(imageUrl.get_attribute('src'),fileName)
index+=1
def saveIcon(self,url,dir,name):
print u'头像地址%s %s '%(url,name)
splitPath=url.split('.')
fTail=splitPath.pop()
fileName=dir+'/'+name+'.'+fTail
print fileName
self.saveImg(url,fileName)
#写入图片
def saveImg(self,imageUrl,fileName):
print imageUrl
u=urllib2.urlopen(imageUrl)
data=u.read()
f=open(fileName,'wb')
f.write(data)
f.close()
#保存个人信息
def saveBrief(self,content,dir,name,speed_time):
speed_time=u'当前MM耗时 '+str(speed_time)
content=content+'\n'+speed_time
fileName=dir+'/'+name+'.txt'
f=open(fileName,'w+')
print u'正在获取%s的个人信息保存到%s'%(name,fileName)
f.write(content.encode('utf-8'))
#创建目录
def mkdir(self,path):
path=path.strip()
print u'创建目录%s'%path
if os.path.exists(path):
return False
else:
os.makedirs(path)
return True
spider=Spider()
#获取前5页
spider.getContent(5) 效果如下 只获取了第一个相册的第一页的 如果要全部的 还要涉及到模拟下滑加载更多这里先不作了解:
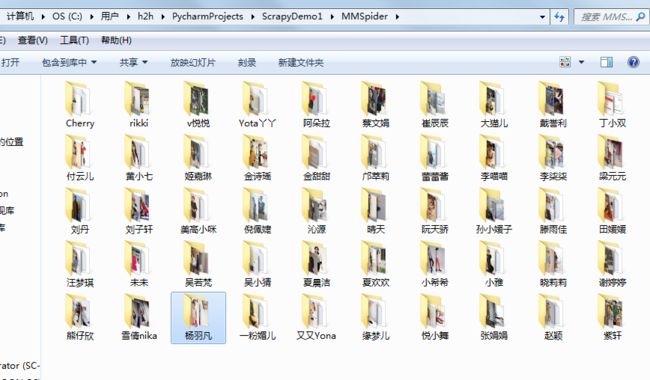
妹子不得来告我吧 
声明一遍 如果有不能展示的 联系我 我会删掉的。。。
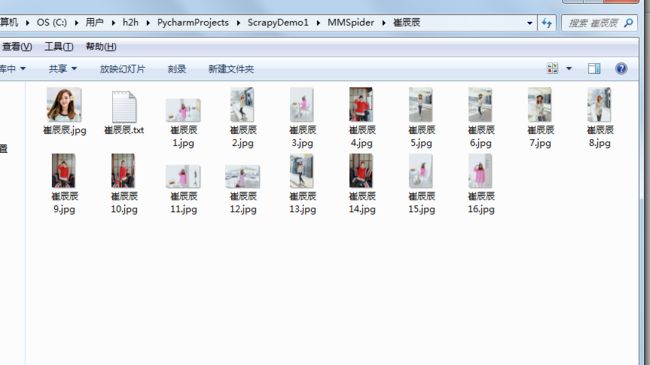
现在来分析一下 实现过程
- 第一页 任务列表 正常网页 看看结构 来用正则获取任务详情页面
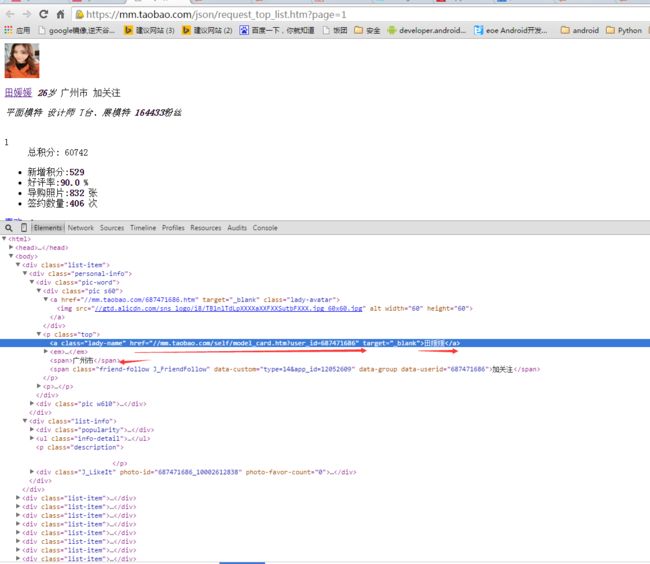

- 页面详情 使用PhantomJS 来加载 然后根据Xpath来获取 XPath是个宝贝啊 特别好用很粗暴一下子可以拿到想要的

上篇文章有相关资料 不做详细分析 这个丑丑的正则
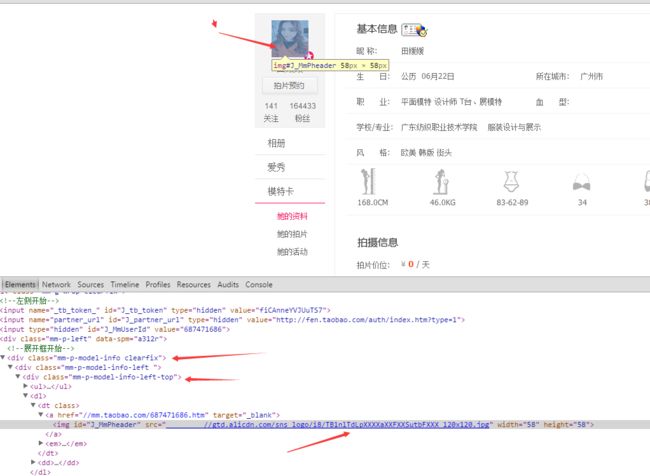
基本信息获取 观察结构

对应的代码

然后头像也是一样
获取相册地址 进入相册页面

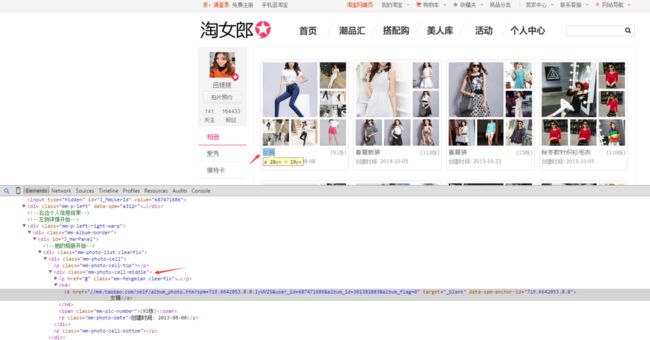
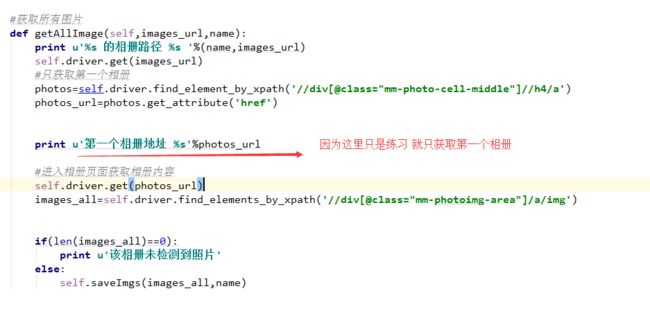
最后在相册里面获取第一页展示的
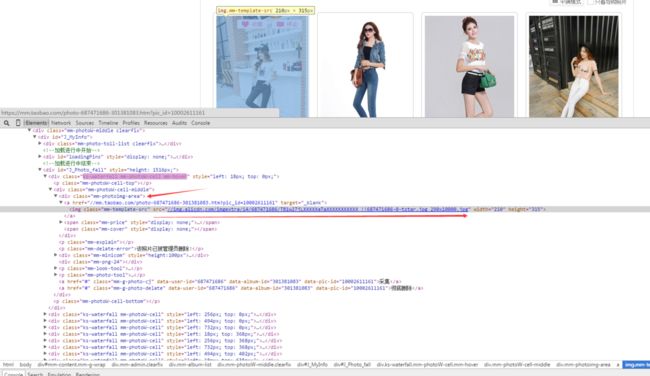
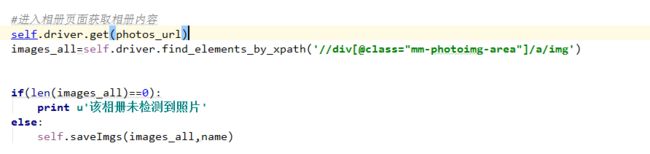

到此结束 保存相关信息的代码 上面也给出了 这里不做详细说明
基本分析 就是用google浏览器的F12 来分析结构 然后 抽取内容 感觉Python 相关资料很少啊 尤其是中文的
这个PhantomJs 之所以这里给出分享过程 因为我确实在Google 知乎(度娘更不用说了)上面搜索相关资料很少 别人也就说用这个 也没说咋用 对于新手来讲 还是希望能有一个完整的过程分析

写的时候听的歌
我等到花儿都谢了
我睡不着的时候会不会有人陪着我
我难过的时候会不会有人安慰我
我想说话的时候会不会有人了解我
我忘不了你的时候你会不会来疼我
