Python 爬虫 正则抽取网页数据和Scrapy简单使用
图片不显示的话 点击这里
Python新手 前些天看了一些基本语法发现继续看下去效果甚微(枯(ji)燥(mo)了)
知乎上面的大神 都说爬虫 那我就从爬虫开始实践学习吧
先从简单的静态的一个页面开始
干什么都得按照套路来 一哥们经常这样说 干啥事都有套路 跟着我左手右手一个慢动作
如果不使用框架Scrapy
我们拿到这个网页的源文件之后
就得自己用正则表达式来抽取想要的数据
这里拿糗百做实验 为什么是糗百 因为我看的资料是糗百(无辜的糗百,宝宝不哭)

- 先要分析页面 看怎么抽取出来我们想要的数据
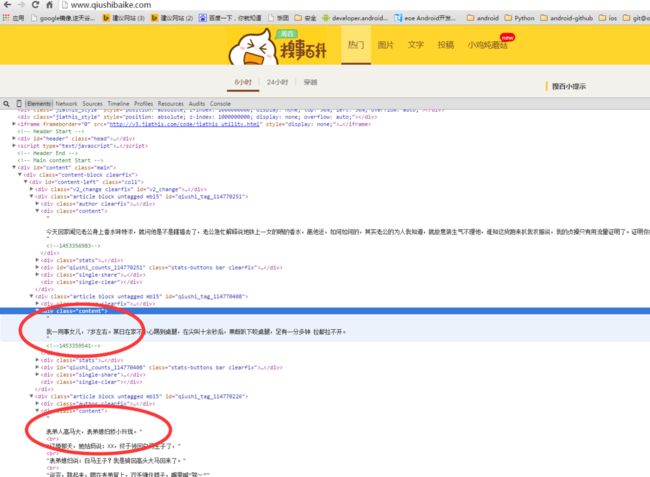
发现段子都在这个
所以代码这么实现
#coding=utf-8
__author__ = 'Daemon'
import urllib2,re,time
class CB_Spider:
def __init__(self):
self.page=1
self.enable=True
#正则获取段子内容
def getPageContent(self):
myUrl='http://www.qiushibaike.com/hot/page/'+str(self.page)
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = { 'User-Agent' : user_agent }
req = urllib2.Request(myUrl, headers = headers) #模拟浏览器
myResponse=urllib2.urlopen(req)
myPgae=myResponse.read()
unicodePage=myPgae.decode('utf-8')
#根据正则表达式拿到所有的内容
myItems=re.findall('(.*?) 到这里就是全部的代码 用正则自己抽取相关网页的内容
但是一般人不这么玩 在实际项目中 还得用框架 我开发Android的 我也不会啥都自己写 来看看Scrapy的简单使用 怎么获取和上面一样的结果
先要安装相关的环境 我是按照这个地址给出安装步骤进行 当然不会每个人都一切顺利

遇到问题去Google 基本都能解决 这里不是重点
Scrapy安装
安装好了之后 第一步
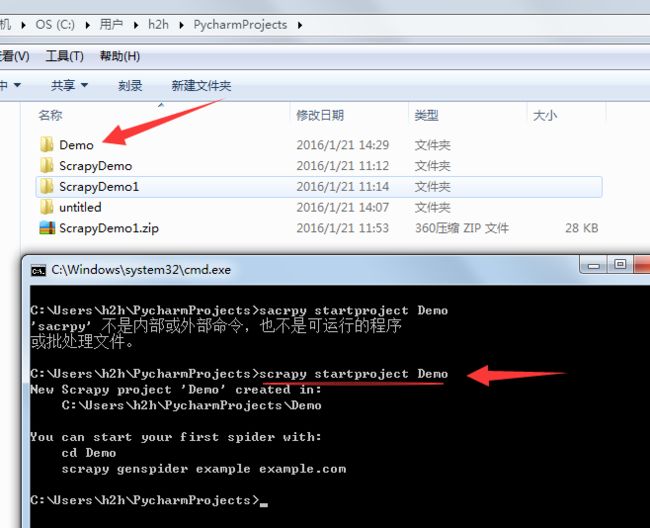
- 创建一个scrapy工程 看图上的CMD 命令行
- 我这里用的的Pycharm来打开这个工程 这里只是为了结构看起来方便和写代码方便 因为这里最后还是得靠cmd 来执行 还没将Pycharm和Scrapy配置起来 后面学习的时候跟着主流走
工程结构如下
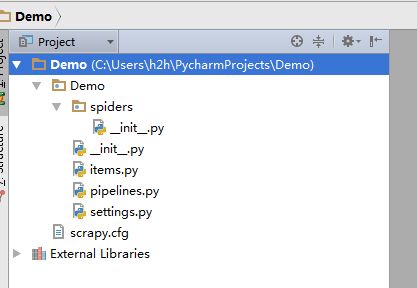
这里就是创建工程 现在来到我们的项目ScrapyDemo1 写好的
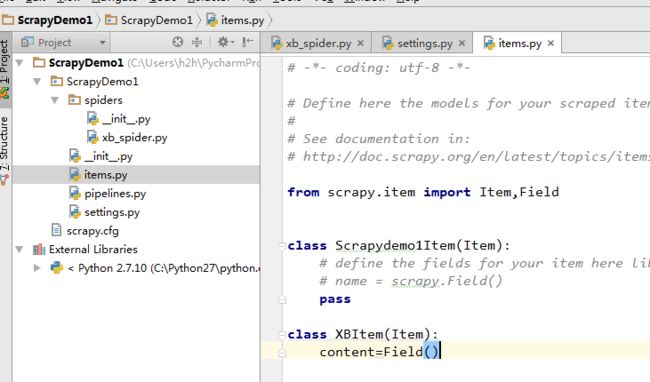
看看这几个文件能干嘛
items.py 写上自己的爬虫需要的数据的类 和相关属性 相当于在解析数据时的接收器
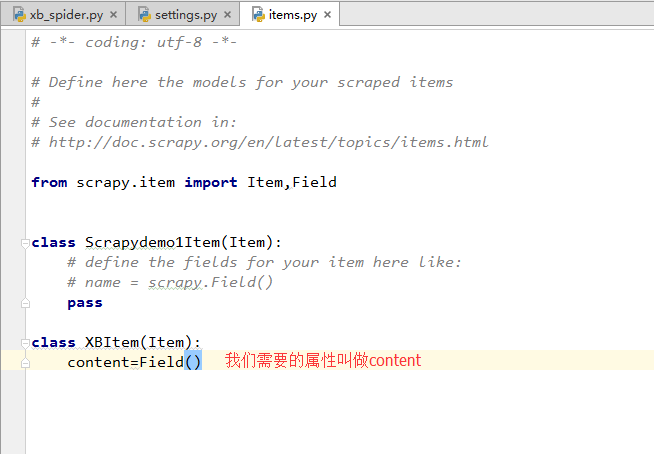
setting.py 看名字就知道是配置文件 样子长这样 这里是默认的哈
其余的几个暂时没用到 先不说
xb_spider.py 就是我们的实现文件
#coding=utf-8
from scrapy import Spider
from ScrapyDemo1.items import XBItem
from scrapy.selector import Selector
__author__ = 'Daemon'
class XBSpider(Spider):
name='xb' #必须
#allowed_domains = ["qiushibaike.com"]
#必须
start_urls=[
'http://www.qiushibaike.com/8hr/page/1'
]
#必须
def parse(self, response):
sel=Selector(response)
sites=sel.xpath('//div[@class="content"]')
#
# filename = 'xbdata'
# open(filename, 'w+').write(len(sites))
items=[]
for site in sites:
item=XBItem()
item['content']=site.xpath('text()').extract()
print items.append(item)
return items用到了Selector Xpath
Selector文档
Xpath文档
W3c的截图
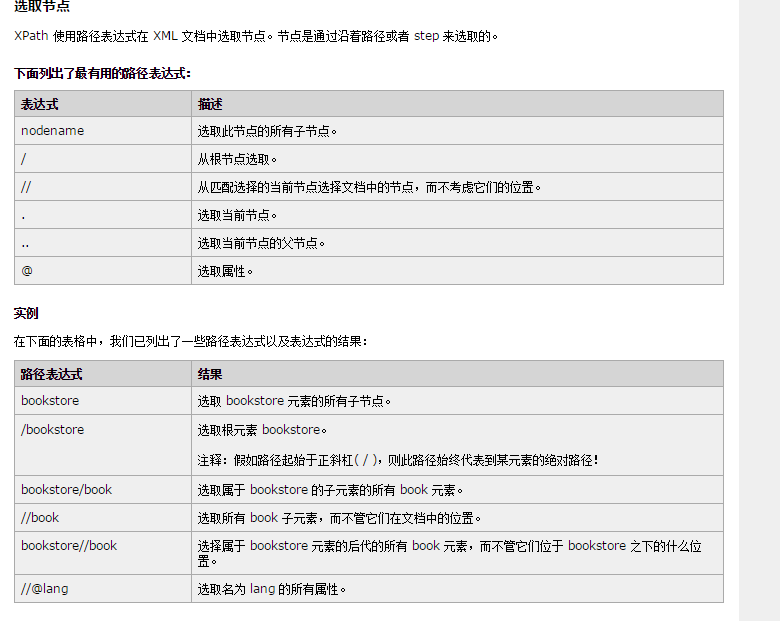
知道这些 基本能见到的实践加调试运用了 因为我也是新手

在我的代码中 是这样 sites=sel.xpath(‘//div[@class=”content”]’) 获取
然后他的text()就是内容
现在启动程序 获取数据存储本地
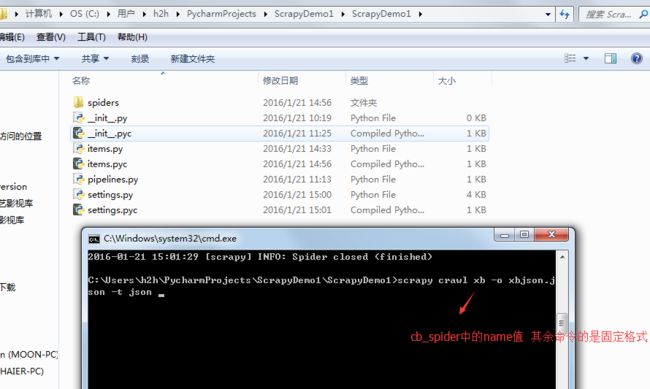
现在生产了json文件 我们打开看看
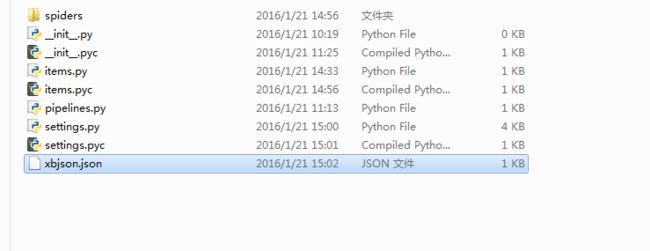
发现啥都没有 当时就懵逼是吧? 是的懵逼了 哈哈哈

那这里我们就看日志呗 找到错误日志 就好办了

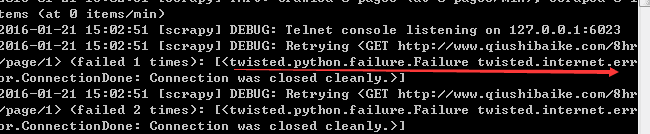
报错都给你了 你可以去google搜索 其实想想都知道 上面正则的时候我们模拟了浏览器 这里我们没有
我们进去setting.py设置就行了
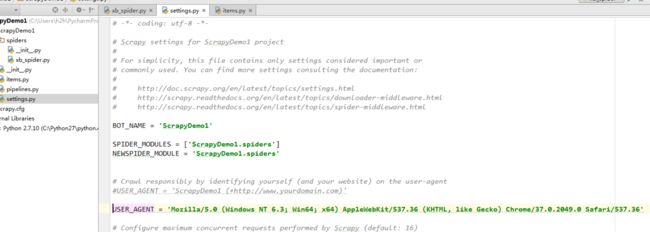
再来重新运行一遍 发现数据存在了 而已已经用json文本保存
只是一个静态的页面的数据爬取 当然写这边文章的目的就是为了实践这个Scrapy框架和对Python的熟悉 增加理解
写这边文章的时候 听的是这首歌

爱要怎么说出口