Internal_Covariate_Shift现象以及Batch Normalization的可视化
文章目录
- 序
- Internal Covariate Shift
- 不加BN与加BN可视化对比
-
- 第一层网络和最后一层的对比
- 底中顶三层的变化对比
- 最后三层的变化对比
- 全部对比
- 结论
- 代码
序
本文注重对Internal_Covariate_Shift和Batch_Normalization的可视化。什么是Internal_Covariate_Shift和Batch_Normalization请参考Internal Covariate Shift与Normalization。
Internal Covariate Shift
参考网上的博文,个人理解如下:
- Covariate Shift指源空间和目标空间的输入分布不一致问题,因为是在神经网络的内部所以是Internal。
- 它容易造成造成网络每层输入数据不再遵循**“独立同分布”原则**,也就是神经网络各层输入分布不一致。具体有以下现象:
- 网络顶层Hidden Layers(靠近输出端)的输入剧烈变化,顶层需要不停地适应新的输入数据,收敛速度慢或者收敛。
- 调参时需要小心控制学习率。
- 对于初始化参数敏感。
说了这么多,还是可视化一下吧(整个Ipython的代码见最后或者附件)。我建立了一个环状二分类数据集,如下:
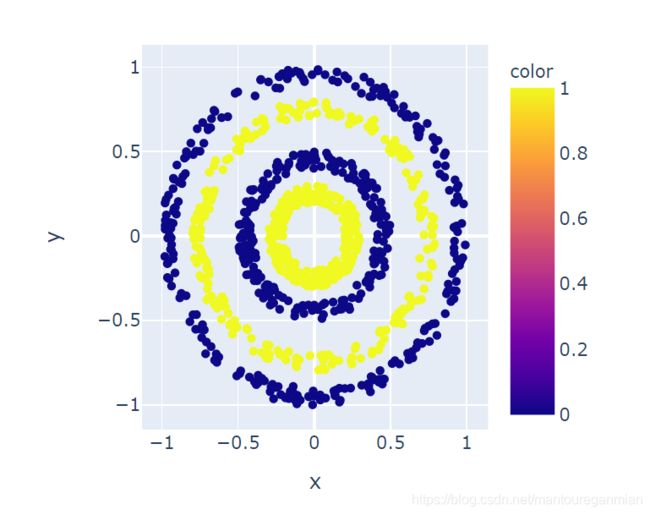
输入只有两维度,模型是11层的神经网络,网络调的比较窄为,学习率为Adam的默认学习率。在不加BN的情况下,模型有很多次,loss停在0.6932就不动了,也就是是难收敛。(当然用较宽的网络,还是很容易就收敛了)
不加BN与加BN可视化对比
在训练时,每个batch调整后的权重都保存了下来。然后计算每个batch间每层网络权重的差值的绝对值差的均值和标准差,并可视化出来。
以下可视化的截图是两个模型均收敛了。
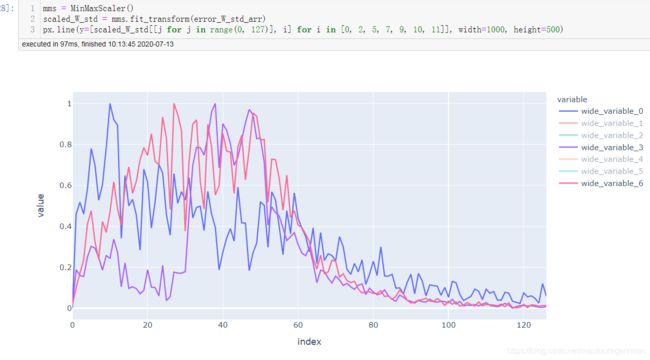
第一层网络和最后一层的对比
不加BN
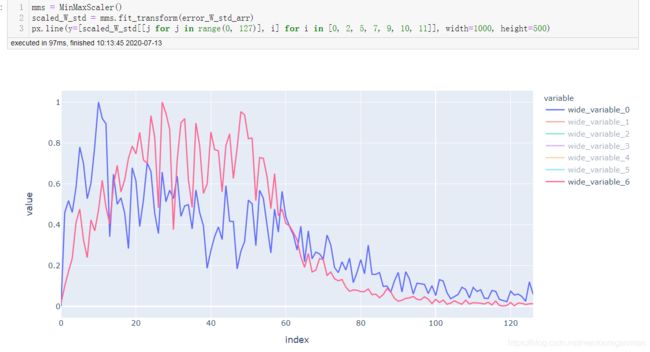

加入BN后:

底中顶三层的变化对比
不加BN

加入BN


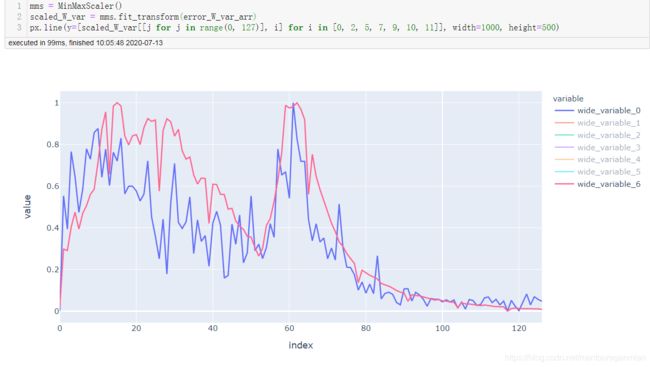
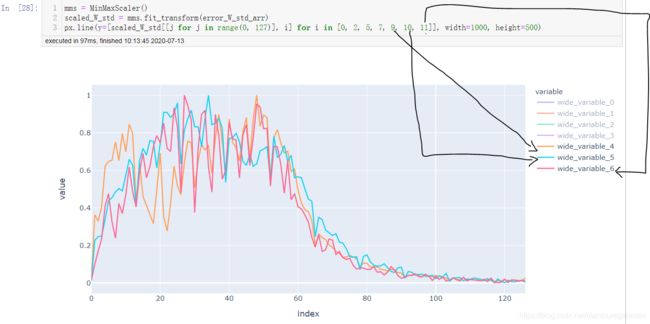
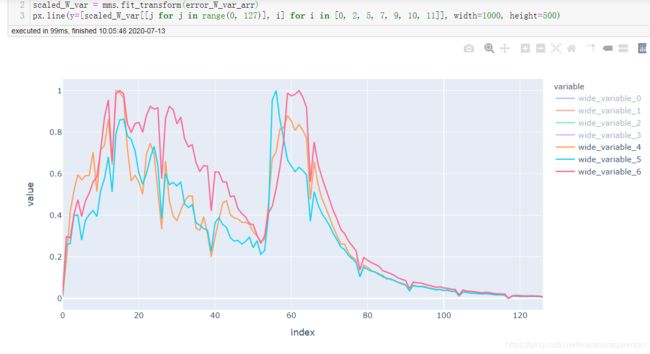
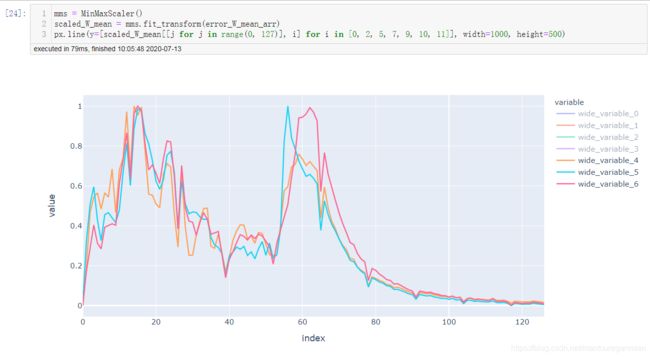
最后三层的变化对比
不加BN,标准差和均值,如下:
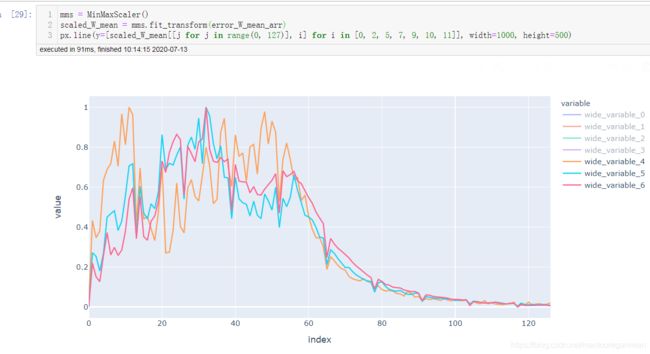
加入BN后:
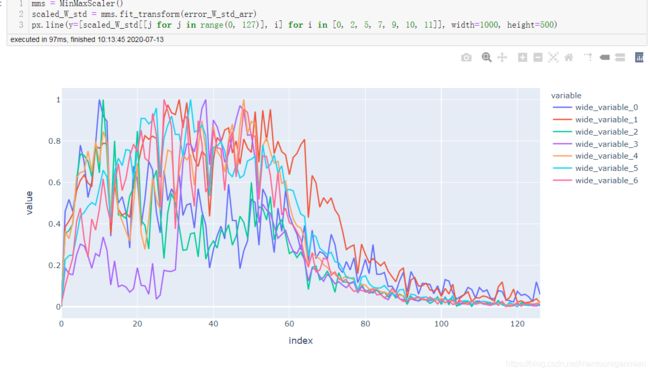
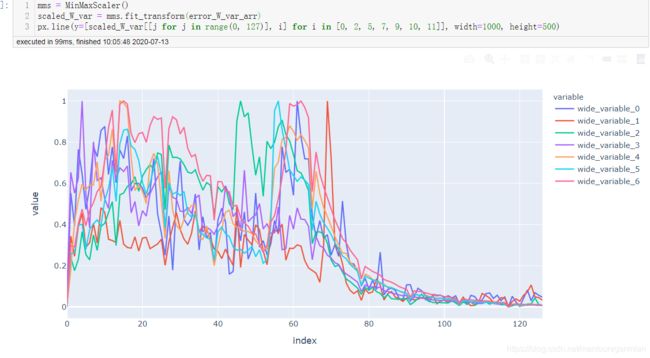
全部对比
不加入BN

加入BN

结论
由以上几幅图可见,与不加BN的变化图相比,加入BN后:每层间权重更新变化程度趋于一致,应该是BN起到了作用,使得每层输入分布比较趋向于服从**“独立同分布”**。BN确实起到了减缓ICS的作用。
代码
代码,不知道如何上传ipython,所以凑活看吧!:
# 目标观察 internal_covariate_shift现象
- 制造一个同心圆环的二分类数据集
- 试试多层神经网络,然后保存每层的数据,并save下来
- 查看save数据的权重,然后看看每次调整后的效果
# importer
import plotly.express as px
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow.keras as keras
from sklearn.model_selection import train_test_split
from sklearn.utils import shuffle
from sklearn.metrics import f1_score, precision_score, recall_score
from sklearn.preprocessing import MinMaxScaler
# 设置gpu内存自增长
gpus = tf.config.experimental.list_physical_devices('GPU')
print(gpus)
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
# 制造数据
def circle(min_radius, max_radius):
pointers = np.random.random((100000, 2)) * 2. - 1.
radiuses = np.sqrt(np.sum(pointers * pointers, axis=1))
target_pointers = pointers[(min_radius <= radiuses) & (radiuses <= max_radius), :]
return target_pointers[:3600]
mtx_a = circle(0.2, 0.3)
a_y = np.ones((mtx_a.shape[0]), dtype=np.int)
mtx_b = circle(0.4, 0.5)
b_y = np.zeros((mtx_b.shape[0]), dtype=np.int)
mtx_c = circle(0.7, 0.8)
c_y = np.ones((mtx_c.shape[0]), dtype=np.int)
mtx_d = circle(0.9, 1.0)
d_y = np.zeros((mtx_d.shape[0]), dtype=np.int)
y = np.hstack((a_y, b_y, c_y, d_y))
X = np.vstack((mtx_a, mtx_b, mtx_c, mtx_d))
X, y = shuffle(X, y)
X.shape, y.shape
mtx_a.shape, mtx_b.shape, mtx_c.shape, mtx_d.shape
## show
x1 = X[:, 0]
x2 = X[:, 1]
px.scatter(x=x1[:1000], y=x2[:1000], color=y[:1000], width=400, height=400)
## train, val, test数据
train_X, val_X, tra_y, val_y = train_test_split(X, y)
train_X, test_X, tra_y, test_y = train_test_split(train_X, tra_y)
train_dataset = tf.data.Dataset.from_tensor_slices((train_X, tra_y)).shuffle(10000).batch(64)
val_dataset = tf.data.Dataset.from_tensor_slices((val_X, val_y)).shuffle(10000).batch(64)
test_dataset = tf.data.Dataset.from_tensor_slices((test_X, test_y)).shuffle(10000).batch(64)
# 训练一下
def get_model_layer_weight_mtx(model):
def W_b(layer):
W = layer.weights[0].numpy()
b = layer.weights[1].numpy()
return W, b
W = [W_b(lay)[0] for lay in model.layers if lay.weights]
b = [W_b(lay)[1] for lay in model.layers if lay.weights]
return np.array(W), np.array(b)
def generate_model():
dense_units = 7
inputs = keras.layers.Input((2,))
dense1 = keras.layers.Dense(dense_units, activation="relu")(inputs)
dense2 = keras.layers.Dense(dense_units, activation="relu")(dense1)
dense3 = keras.layers.Dense(dense_units, activation="relu")(dense2)
dense4 = keras.layers.Dense(dense_units, activation="relu")(dense3)
dense5 = keras.layers.Dense(dense_units, activation="relu")(dense4)
dense6 = keras.layers.Dense(dense_units, activation="relu")(dense5)
dense7 = keras.layers.Dense(dense_units, activation="relu")(dense6)
dense8 = keras.layers.Dense(dense_units, activation="relu")(dense7)
dense9 = keras.layers.Dense(dense_units, activation="relu")(dense8)
dense10 = keras.layers.Dense(dense_units, activation="relu")(dense9)
dense11 = keras.layers.Dense(dense_units, activation="relu")(dense10)
outputs = keras.layers.Dense(1, activation="sigmoid")(dense11)
return keras.Model(inputs, outputs)
del model
import gc
gc.collect()
model = generate_model()
model.compile(optimizer=keras.optimizers.Adam(0.001), loss=keras.losses.BinaryCrossentropy(), metrics=["AUC", "Recall", "Precision"])
model.build(input_shape=(2,))
init_W, init_b = get_model_layer_weight_mtx(model)
model_cpt = keras.callbacks.ModelCheckpoint("./model/circle_{epoch}_{batch}", save_weights_only=True, save_freq=3)
history = model.fit(train_dataset, epochs=10, validation_data=test_dataset, callbacks=[model_cpt])
# metrics
test_pred_y = model.predict(test_X)[:, 0] > 0.4999999
test_pred_y
f1_score(test_y, test_pred_y), precision_score(test_y, test_pred_y), recall_score(test_y, test_pred_y)
# 观察ICS现象
## 观察每层参数,每次更新间改变的大小
star_W, start_b = init_W, init_b
new_model = generate_model()
new_model.compile(optimizer="adam", loss=keras.losses.BinaryCrossentropy(), metrics=["AUC", "Recall", "Precision"])
new_model.build(input_shape=(2,))
def diff(m1, m2):
m = len(m1)
mean = [np.mean(np.absolute(m1[i] - m2[i])) for i in range(m)]
std = [np.std(np.absolute(m1[i] - m2[i])) for i in range(m)]
return mean, std
epochs = 10
batchs = 127
error_W_mean = []
error_W_std = []
error_b_mean = []
error_b_std = []
start_W, start_b = init_W, init_b
index = 0
for epc in range(epochs):
print(epc+1)
for btc in range(0, batchs, 10):
_ = new_model.load_weights(f"model/circle_{epc+1}_{btc}")
tmp_W, tmp_b = get_model_layer_weight_mtx(new_model)
diff_W_mean, diff_W_std = diff(start_W, tmp_W)
error_W_mean.append(diff_W_mean)
error_W_std.append(diff_W_std)
diff_b_mean, diff_b_std = diff(start_b, tmp_b)
error_b_mean.append(diff_b_mean)
error_b_std.append(diff_b_std)
index += 1
start_W, start_b = tmp_W, tmp_b
error_W_mean_arr = np.array(error_W_mean)
np.save("./data/non_BN_error_W_mean.npy", error_W_mean_arr)
error_W_var_arr = np.array(error_W_std)
np.save("./data/non_BN_error_W_var.npy", error_W_var_arr)
error_b_mean_arr = np.array(error_b_mean)
np.save("./data/non_BN_error_W_mean.npy", error_W_mean_arr)
error_b_var_arr = np.array(error_b_std)
np.save("./data/non_BN_error_b_var.npy", error_b_var_arr)
mms = MinMaxScaler()
scaled_W_var = mms.fit_transform(error_W_var_arr)
px.line(y=[scaled_W_std[[j for j in range(0, 127)], i] for i in [0, 5, 14, 18]], width=1000, height=500)
mms = MinMaxScaler()
scaled_W_mean = mms.fit_transform(error_W_mean_arr)
px.line(y=[scaled_W_mean[[j for j in range(0, 127)], i] for i in [0, 5, 14, 15, 16, 17, 18]], width=1000, height=500)