spark架构与原理
spark的优势:
1、spark提供了一个全面、统一的框架用于管理各种有着不同性质(文本数据、图表数据等)的数据集和数据源(批量数据或实时的流数据)的大数据处理需求。
2、spark可以将hadoop集群中应用在内存中的运行速度提升10倍,甚至能将应用在磁盘上的运行速度提升10倍。
Spark core:包含Spark的基本功能;尤其是定义RDD的API、操作以及这两者上的动作。其他spark的库都是构建在RDD和Spark Core之上的。
Spark SQL:提供通过Apache Hive的SQL变体Hive查询语言(HiveQL)与Spark进行交互的API。每个数据库表被当做一个RDD,Spark SQL查询被转换为Spark操作。
Spark Streaming:对实时数据流进行处理和控制。
Spark架构的组成图如下:
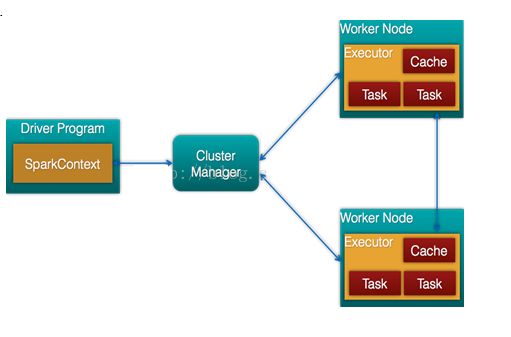
- Cluster Manager:在standalone模式中即为Master主节点,控制整个集群,监控worker。在YARN模式中为资源管理器
- Worker节点:从节点,负责控制计算节点,启动Executor或者Driver。
- Driver:运行Application的main()函数
- Executor:执行器,是为某个Application运行在worker node上的一个进程。
Spark与hadoop:
Hadoop有两个核心模块,分布式存储模块HDFS和分布式计算模块Mapreduce。
Spark本身没有提供分布式文件系统,因此spark的分析大多依赖于Hadoop的分布式文件系统HDFS。
运行流程及特点:
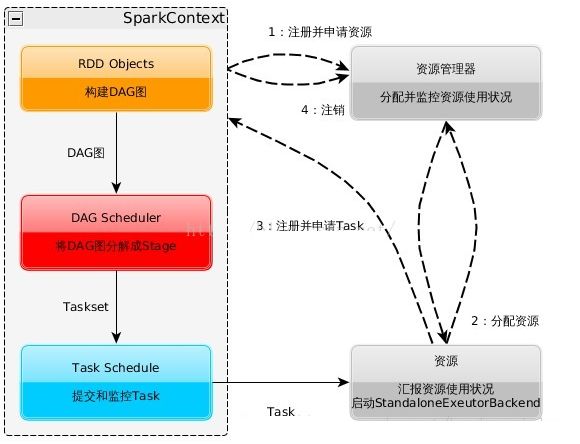
1、构建Spark Application的运行环境,启动SparkContext
2、sparkContext向资源管理器申请运行Executor资源,并启动StandaloneExecutorbackend,
3、Executor向SparkContext申请Task;
4、SparkContext将应用程序分发给Executor;
5、SparkContext构建成DAG图,将DAG图分解成stage、将Taskset发送给Task Scheduler,最后由Task Scheduler将Task发送给Executor运行;
6、Task在Executor运行,运行完释放所有资源。
Application:Application指用户编写的spark应用程序,包含Driver功能代码和Executor代码。
Driver:运行Application的main函数并创建SparkContext,在Spark环境中有SparkContext负责与ClusterMannager通信。
Executor:某个Application运行在worker节点上的一个进程。
Cluter Manager:在集群上获取资源的外部服务。
Worker:集群中任何可以运行Application代码的节点。
Task:被送到某个Executor上的工作单元。
Job:包含多个Task组成的并行计算
Stage:每个Job会被分拆成多组Task。
DAGScheduler:根据Job构建基于Stage的DAG,并提交Stage给TASKScheduler。
TASKSedulter:将TaskSET提交给worker运行,每个Executor运行什么Task就是在此处分配。
Spark运行模式:
Spark运行模式多种多样,部署在单机上时,即可以用本地模式运行,1也可以用伪分布式模型运行。

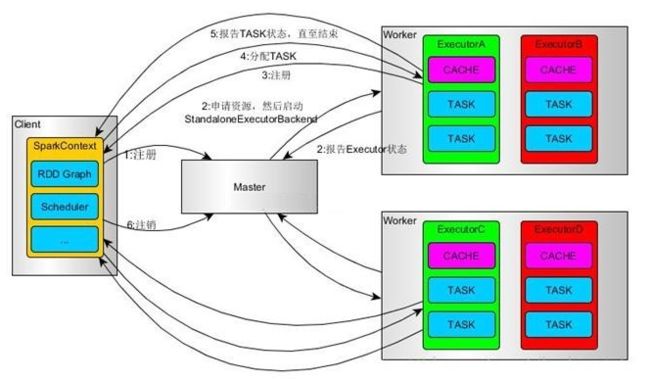
1、SparkContext连接到Master,向Master注册并申请资源。
2、Master根据SparkContext的资源申请要求和Worker心跳周期内报告的信息确定在哪个Worker上分配资源,然后在该Worker上获取资源,然后启动standaloneExecutorBackend。
3、StandaloneExecutorBackend向SparkContext注册。
4、SparkContext将Application代码发送给StandaloneExecutorBackend;构建DAG图,并提交给DAG Scheduler分解成stage,然后以Stage提交给Task Scheduler,Task Scheduler负责将Task分配到相应的Worker,提交给StandaloneExecutorBackend执行;
5、StandaloneExecutorBackend会建立Executor线程池,开始执行Task,并向Sparkcontext报告,直至Task完成
6、所有Task完成后,SparkContext向Master注销,释放资源。
RDD运行流程:
1、创建RDD对象
2、DAGScheduler模块介入运算,计算RDD之间的依赖关系,RDD之间的依赖关系就形成了DAG
3、每一个Job被分为多个Stage,划分Stage的一个主要依据是当前计算因子的输入是否是确定的,如果是则将其分为在同一个Stage,避免多个Stage之间的消息传递开销。