机器学习笔记——朴素贝叶斯
朴素贝叶斯算法
- 贝叶斯定理
-
- 概率事件
- 条件概率
- 联合概率
- 朴素贝叶斯算法
-
- 极大似然估计
- 贝叶斯估计
- 代码实现
- 参考文献
贝叶斯定理
概率事件
事件A发生的概率记为 P ( A ) P(A) P(A),事件B发生的概率记为 P ( B ) P(B) P(B),
条件概率
在事件A发生后发生B事件的概率记为 P ( B ∣ A ) P(B|A) P(B∣A),在事件B发生后发生事件A的概率为 P ( A ∣ B ) P(A|B) P(A∣B),
联合概率
事件A和B同时发生的概率为联合概率,记为为P(A,B)(即P(A和B))那么 P ( A , B ) = P ( A ) P ( B ∣ A ) = P ( B ) P ( A ∣ B ) P(A, B) = P(A)P(B|A) = P(B)P(A|B) P(A,B)=P(A)P(B∣A)=P(B)P(A∣B)
那么我们很容易得到
P ( A ∣ B ) = P ( A ) P ( B ∣ A ) P ( B ) P(A|B) = \frac{P(A)P(B|A)}{P(B)} P(A∣B)=P(B)P(A)P(B∣A)
这就是贝叶斯公式,朴素贝叶斯算法也是基于此公式
朴素贝叶斯算法
极大似然估计
输入:有训练数据及 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , … , ( x N , y N ) } T=\{(x_1, y_1), (x_2, y_2), …, (x_N, y_N)\} T={ (x1,y1),(x2,y2),…,(xN,yN)}, 其中 x i = ( x i ( 1 ) , x i ( 2 ) , … , x i ( n ) ) T x_i = (x_i^{(1)}, x_i^{(2)}, …, x_i^{(n)})^T xi=(xi(1),xi(2),…,xi(n))T, x i ( j ) x_i^{(j)} xi(j)是第 i i i个样本的第 j j j个特征, x i ( j ) ∈ { a j 1 , a j 2 , … , a j S j } x_i^{(j)} ∈\{a_{j1}, a_{j2}, …, a_{jS_j}\} xi(j)∈{ aj1,aj2,…,ajSj}, a j l a_{jl} ajl是第 j j j个特征可能取得第 l l l个值, y y y的类标记集合为 { ( c 1 ) , ( c 2 ) , … , ( c K ) } \{(c_1), (c_2), …, (c_K)\} { (c1),(c2),…,(cK)};
实例: x x x;
输出:实例 x x x的分类。
1)计算先验概率及条件概率
P ( Y = c k ) = ∑ i = 1 N I ( y i = c k ) N , k = 1 , 2 , … , K P(Y=c_k) = \frac{\sum_{i=1}^NI(y_i = c_k)}{N}, \ \ \ \ \ \ \ k=1, 2,…, K P(Y=ck)=N∑i=1NI(yi=ck), k=1,2,…,K
P ( X ( j ) = a j l ∣ Y = c k ) = ∑ i = 1 N I ( x i ( j ) = a j l , y i = c k ) ∑ i = 1 N I ( y i = c k ) P(X^{(j)} = a_{jl}|Y = c_k) = \frac{\sum_{i=1}^N I(x_i^{(j)}=a_{jl}, y_i=c_k)}{\sum_{i=1}^NI(y_i = c_k)} P(X(j)=ajl∣Y=ck)=∑i=1NI(yi=ck)∑i=1NI(xi(j)=ajl,yi=ck)
其中 j = 1 , 2 , … , n ; l = 1 , 2 , … , S j ; k = 1 , 2 , … , K j=1, 2,…,n; \ \ l=1, 2,…,S_j; \ \ k=1, 2,…, K j=1,2,…,n; l=1,2,…,Sj; k=1,2,…,K
2)对于给定的实例 x = ( x ( 1 ) , x ( 2 ) , … , x ( n ) ) T x = (x^{(1)}, x^{(2)}, …, x^{(n)})^T x=(x(1),x(2),…,x(n))T,计算
P ( Y = c k ) = ∏ j = 1 n P ( X ( j ) = x ( j ) ∣ Y = c k ) , k = 1 , 2 , … , K P(Y=c_k) = \prod_{j=1}^nP(X^{(j)} = x^{(j)}|Y=c_k),\ \ k=1, 2, …, K P(Y=ck)=j=1∏nP(X(j)=x(j)∣Y=ck), k=1,2,…,K
3)确定实例x的类
y = a r g m a x c k P ( Y = c k ) ∏ j = 1 n P ( X ( j ) = x ( j ) ∣ Y = c k ) y = argmax_{c_k}P(Y=c_k)\prod_{j=1}^nP(X^{(j)} = x^{(j)}|Y=c_k) y=argmaxckP(Y=ck)j=1∏nP(X(j)=x(j)∣Y=ck)
贝叶斯估计
用极大似然估计可能会出现估计概率值为0的情况,解决方法是采用贝叶斯估计。条件概率的贝叶斯估计是
P λ ( X ( j ) = a j l ∣ Y = c k ) = ∑ i = 1 N I ( x i ( j ) = a j l , y i = c k ) + λ ∑ i = 1 N I ( y i = c k ) + S j λ P_{\lambda}(X^{(j)} = a_{jl}|Y = c_k) = \frac{\sum_{i=1}^N I(x_i^{(j)}=a_{jl}, y_i=c_k) +\lambda}{\sum_{i=1}^NI(y_i = c_k)+S_j\lambda} Pλ(X(j)=ajl∣Y=ck)=∑i=1NI(yi=ck)+Sjλ∑i=1NI(xi(j)=ajl,yi=ck)+λ
其中 λ > = 0 \lambda >= 0 λ>=0,通常 λ = 1 \lambda = 1 λ=1,这是成为拉普拉斯平滑,对于任何 l = 1 , 2 , … , S j , k = 1 , 2 , … , K l=1, 2, …, S_j, k=1,2, …, K l=1,2,…,Sj,k=1,2,…,K,有
P λ ( X ( j ) = a j l ∣ Y = c k ) > 0 P_{\lambda}(X^{(j)} = a_{jl}|Y = c_k) > 0 Pλ(X(j)=ajl∣Y=ck)>0
∑ l = 1 S j P λ ( X ( j ) = a j l ∣ Y = c k ) = 1 \sum_{l=1}^{S_j}P_{\lambda}(X^{(j)} = a_{jl}|Y = c_k) = 1 l=1∑SjPλ(X(j)=ajl∣Y=ck)=1
先验概率的贝叶斯估计是
P λ ( Y = c k ) = ∑ i = 1 N I ( y i = c k ) + λ N + K λ P_{\lambda}(Y=c_k) = \frac{\sum_{i=1}^NI(y_i = c_k) + \lambda}{N+K\lambda} Pλ(Y=ck)=N+Kλ∑i=1NI(yi=ck)+λ
代码实现
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
# 构造训练数据集
x_cls1 = np.concatenate((np.random.randn(300).reshape(-1, 1), np.random.randn(300).reshape(-1, 1)), axis=1)
y_cls1 = np.zeros((300))
x_cls2 = np.concatenate(((np.random.randn(300)+4).reshape(-1, 1), np.random.randn(300).reshape(-1, 1)), axis=1)
y_cls2 = np.ones((300))
x = np.round(np.concatenate((x_cls1, x_cls2), axis=0), 1)
y = np.concatenate((y_cls1, y_cls2), axis=0)
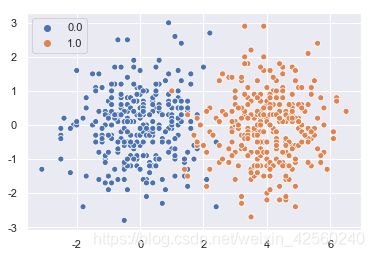
用散点图查看数据
sns.scatterplot(x[:, 0], x[:, 1], hue=y)
# 把训练集分割成训练集和测试集
x_train, x_test, y_train, y_test = \
train_test_split(x, y, test_size=0.3)
# 训练模型
clf = GaussianNB()
clf.fit(x_train, y_train)
print("test score: %.2f" % clf.score(x_test, y_test))
test score: 0.98
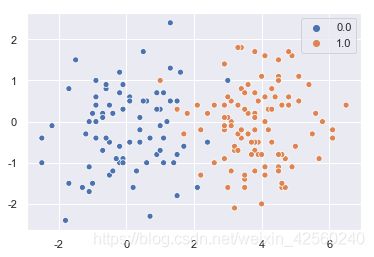
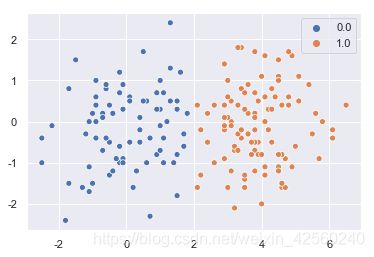
测试集散点图和预测散点图分别为
参考文献
李航 《统计学习方法 第二版》