使用tensorflow1.11.0跑通yolo代码并训练--详细过程
下载github代码:
该github代码地址为:
https://github.com/YunYang1994/tensorflow-yolov3
一般将其fork之后,然后在gitee上同步之后下载速度会更快,我已经fork过了,所以直接通过以下命令即可快速下载整个工程:
git clone https://gitee.com/wang_xiao_long_6/tensorflow-yolov3.git
下载之后需要配置Python环境,配置环境这块就不多说了,关于tf-gpu版本的问题网上的解决方案很多。
跑通代码
- 首先安装依赖包:
在docs文件夹中的requirements.txt文件里的内容如下:
tqdm
numpy==1.15.1
Pillow==5.3.0
scipy==1.1.0
tensorflow-gpu==1.11.0
wget==3.2
seaborn==0.9.0
- 下载权重文件
如果使用的是linux操作系统,依次运行以下命令即可:
cd checkpoint
wget https://github.com/YunYang1994/tensorflow-yolov3/releases/download/v1.0/yolov3_coco.tar.gz
tar -xvf yolov3_coco.tar.gz
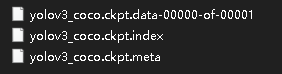
然后发现checkpoint文件夹下多了下面三个文件:
如果是win系统,直接在浏览器输入如下链接即可开始下载:
https://github.com/YunYang1994/tensorflow-yolov3/releases/download/v1.0/yolov3_coco.tar.gz
然后解压、将解压的文件夹里的三个文件copy到checkpoint文件夹下即可。
- 转换模型文件
接下来运行(注意切换路径):
python convert_weight.py
python freeze_graph.py
- 测试:
最后测试,运行demo:
python image_demo.py
或者:
python video_demo.py # if use camera, set video_path = 0
测试结果:

准备自己的数据集
将你的数据集(jpg和xml文件)放入如下的路径中(注意先清除dataset文件夹中的原有文件):
tensorflow-yolov3/data/dataset
其中的数据可以是你的jpg文件和xml文件混合的状态,也可以是分别用images和annotations文件夹来储存的状态,接下来我会介绍如何达到一个统一的状态,进而适合训练。
- 分离xml和jpg(如果你的数据集已经是分开的,可以跳过此步):
用一个脚本对其进行分离:(move_file.py,脚本文件位置见下方图示)
import shutil
import os
from tqdm import tqdm
# put your own path here, never copy blindly:
mixed_data_path = 'D:/Desktop/tensorflow-yolov3/data/dataset'
annotation_path = os.path.join(mixed_data_path, 'Annotations')
image_path = os.path.join(mixed_data_path, 'Images')
imageSet_path = os.path.join(mixed_data_path, 'ImageSets')
mixed_data_file = os.listdir(mixed_data_path)
# print(len(mixed_data_file))
if not os.path.exists(mixed_data_path):
os.mkdir(mixed_data_path)
if not os.path.exists(annotation_path):
os.mkdir(annotation_path)
if not os.path.exists(image_path):
os.mkdir(image_path)
if not os.path.exists(imageSet_path):
os.mkdir(imageSet_path)
if not os.path.exists(imageSet_path + '/Main'):
os.mkdir(imageSet_path + '/Main')
for file in tqdm(mixed_data_file):
if file.endswith('xml'):
shutil.move(os.path.join(mixed_data_path, file), annotation_path)
if file.endswith('jpg'):
shutil.move(os.path.join(mixed_data_path, file), image_path)
data文件夹中的dataset是jpg和xml文件混合的状态,move_file.py文件的位置和dataset在同一级的目录下,下面打了马赛克的地方是我自己加的,大家不用管。运行这个脚本之后,dataset文件夹下的结构如下:
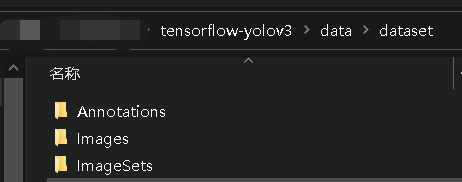
其中Annotations文件夹里的是xml文件,Images文件夹里的内容全是图片,ImageSets文件里的内容是Main文件夹。
- 划分数据集(txt文件形式)
如果你的数据集一开始的层次结构和我的是一样的,就可以按照我的步骤一步一步来;如果你一开始是已经分离的,需要在原来的文件夹基础上做一点修改,首先默认你的Images里放的是jpg,Annotations里放的是xml文件,而且二者都放在了dataset文件夹下,那么还要创建一个文件夹,名为ImageSets,并在该文件夹下创建一个名为Main的文件夹。然后运行下面的脚本(split.py,脚本文件放在dataset文件夹内):
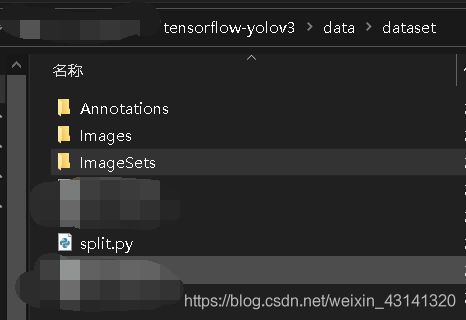
注意在运行这个脚本的时候,如果你是在命令行中运行,或者用的是vscode单独打开这个脚本运行,那么需要注意当前的路径,务必保证当前的路径为:
tensorflow-yolov3/data/dataset
import os
import random
from tqdm import tqdm
root_path = os.getcwd()
# print(root_path)
xmlfilepath = os.path.join(root_path, 'Annotations')
txtsavepath = os.path.join(root_path, 'ImageSets/Main')
trainval_percent = 0.9
train_percent = 0.8
total_xml = os.listdir(xmlfilepath)
train_and_val_size = int(len(total_xml) * trainval_percent)
train_size = int(train_and_val_size * train_percent)
trainval = random.sample(range(len(total_xml)), train_and_val_size)
train = random.sample(trainval, train_size)
print("train and val size:", train_and_val_size)
print("train size:", train_size)
ftrainval = open(txtsavepath + '/trainval.txt', 'w')
ftest = open(txtsavepath + '/test.txt', 'w')
ftrain = open(txtsavepath + '/train.txt', 'w')
fval = open(txtsavepath + '/val.txt', 'w')
for i in tqdm(range(len(total_xml))):
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
然后可以看到Main文件夹里的新增文件:
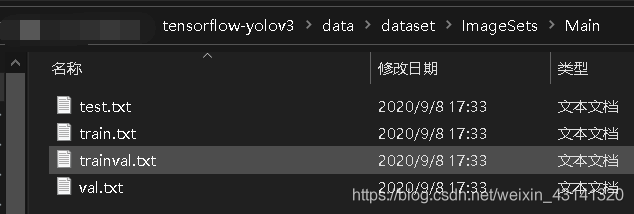
这个脚本的作用是将全部数据集按照0.9作为训练集和验证集,0.1作为测试集;其中0.9的训练集与测试集中,0.8作为训练集,0.2作为验证集。可以通过修改脚本中的比例来更改设置,生成之后可以通过检查test.txt文件中的行数是否占了总数据集的0.1;trainval.txt中的行数是否占了总数据集的0.9;train.txt和test.txt中的行数是否分别占了trainval.txt的0.8和0.2来检查是否正确分割。
-
修改core文件夹下的config.py文件
将训练数据路径改一下:

将测试数据路径改一下:

在路径:./data/classes下创建一个mine.names(名字自己定)文件,在文件中设定自己的标签名,比如我的是“sun”,然后保存,再将config.py文件做如下修改:
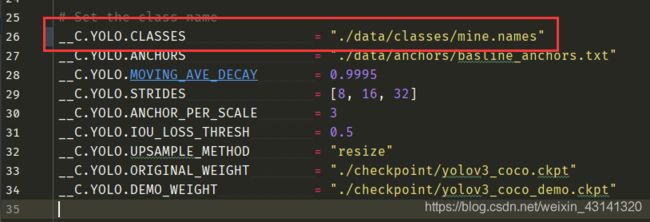
-
修改scripts/voc_annotation.py脚本(后面贴有代码)
首先修改里面的classes变量:

这里存放的是我放在mine.txt文件里的label。
然后修改JPEGImages为Images,因为我们存放图片的文件夹名字改为了Images:

添加路径参数,务必注意这里地方使用绝对路径,不然训练的时候会出错。51行添加一个参数:mine.txt的路径,并将原本的voc_train.txt和voc_test.txt文件换成my_train.txt与my_test.txt,50行是因为我将原来1131data里的dataset放入了本工程项目的data/dataset目录下,所以有两个dataset文件夹,大家根据自己的情况来:

修改之后的脚本为:
import os
import argparse
import xml.etree.ElementTree as ET
def convert_voc_annotation(data_path, data_type, anno_path, classes_path, use_difficult_bbox=True):
# classes = ['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus',
# 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse',
# 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa',
# 'train', 'tvmonitor']
with open(classes_path) as f:
classes = [data.strip() for data in f]
"""
# or:
with open() as f:
classes = f.read().splitlines()
"""
# print(classes)
img_inds_file = os.path.join(data_path, 'ImageSets', 'Main', data_type + '.txt')
with open(img_inds_file, 'r') as f:
txt = f.readlines()
image_inds = [line.strip() for line in txt]
with open(anno_path, 'a') as f:
for image_ind in image_inds:
image_path = os.path.join(data_path, 'Images', image_ind + '.jpg')
annotation = image_path
label_path = os.path.join(data_path, 'Annotations', image_ind + '.xml')
root = ET.parse(label_path).getroot()
objects = root.findall('object')
for obj in objects:
difficult = obj.find('difficult').text.strip()
if (not use_difficult_bbox) and(int(difficult) == 1):
continue
bbox = obj.find('bndbox')
class_ind = classes.index(obj.find('name').text.lower().strip())
xmin = bbox.find('xmin').text.strip()
xmax = bbox.find('xmax').text.strip()
ymin = bbox.find('ymin').text.strip()
ymax = bbox.find('ymax').text.strip()
annotation += ' ' + ','.join([xmin, ymin, xmax, ymax, str(class_ind)])
# print(annotation)
f.write(annotation + "\n")
return len(image_inds)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument("--data_path", default="D:/Desktop/tensorflow-yolov3/data/dataset/")
parser.add_argument("--classes_path", default="D:/Desktop/tensorflow-yolov3/data/classes/mine.names")
parser.add_argument("--train_annotation", default="D:/Desktop/tensorflow-yolov3/data/dataset/my_train.txt")
parser.add_argument("--test_annotation", default="D:/Desktop/tensorflow-yolov3/data/dataset/my_test.txt")
flags = parser.parse_args()
if os.path.exists(flags.train_annotation):os.remove(flags.train_annotation)
if os.path.exists(flags.test_annotation):os.remove(flags.test_annotation)
num1 = convert_voc_annotation(flags.data_path, 'trainval',
flags.train_annotation, flags.classes_path, False)
num2 = convert_voc_annotation(flags.data_path, 'test',
flags.test_annotation, flags.classes_path, False)
print('=> The number of image for train is: %d\n=> The number of image for test is:%d' % (num1, num2))
运行这个脚本,实现的功能是,将每一张图片的路径,以及boxes的信息放在txt文件中,每一行代表一张图片:

开始训练
python train.py
tensorboard --logdir ./data

评估
python evaluate.py
cd mAP
python main.py -na