线程封闭之ThreadLocal源码详解
本文内容将基于JDK1.7的源码进行讨论,并且在文章的结尾,笔者将会给出一些经验之谈,希望能给学习者带来些帮助。
一、线程封闭
在《Java并发编程实战》一书中提到,“当访问共享的可变数据时,通常需要使用同步。一种避免使用同步的方式就是不共享数据”。因此提出了“线程封闭”的概念,一种经常使用线程封闭的应用场景就是JDBC的Connection,通过线程封闭技术,可以把链接对象封闭在某个线程内部,从而避免出现多个线程共享同一个链接的情况。而线程封闭总共有三种类型的呈现形式:
1)Ad-hoc线程封闭。维护线程封闭性的职责由程序实现来承担,然而这种实现方式是脆弱的;
2)栈封闭。实际上通过尽量使用局部变量的方式,避免其他线程获取数据;
3)ThreadLocal类。通过JDK提供的ThreadLocal类,可以保证某个对象仅在线程内部被访问,而该类正是本篇文章将要讨论的内容。
二、误区
网上很多人会想当然的认为,ThreadLocal的实现就是一个类似Map
三、举个栗子
SimpleDateFormat是JDK提供的,一类用于处理时间格式的工具,但是因为早期的实现,导致这个类并非是一个线程安全的实现,因此,在使用的时候我们会需要使用线程封闭技术来保证使用该类过程中的线程安全,在这里,我们使用了ThreadLocal,下面的实现是使用SimpleDateFormat格式化当前时间并输出:
private static ThreadLocal localFormatter =
new ThreadLocal();
static {
localFormatter.set(new SimpleDateFormat("yyyyMMdd"));
}
public static void main(String[] args) {
Date now = new Date();
System.out.println(localFormatter.get().format(now));
}
四、系统设计
在JDK 1.7中,ThreadLocal是一个如下图所示的设计:
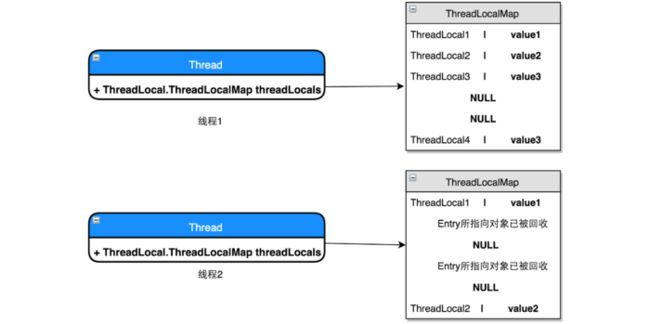
可以在图里看到,每个线程内部都持有一个ThreadLocal.ThreadLocalMap类型的对象,但是该对象只能被ThreadLocal类处理。那么读者暂时可以理解成,每个线程的内部都持有了一个类似Map
为什么这样设计?
看到这里,有的读者会产生这样的提问,为什么是这样的设计?好问题,按照很多的人的想法里,应该有两种设计方式:
1)全局ConcurrentMap
第一,全局的ConcurrentMap
第二,随着线程的销毁,原有的ConcurrentMap
2)局部HashMap
比如某个线程执行时间非常长,然而在此过程中,某个对象已经不可达(理论上可以被GC),但是由于HashMap
五、源码实现
在阐述完ThreadLocal设计以后,我们一起来看看JDK1.7 是怎么实现ThreadLocal的。
ThreadLocal类的本身实现比较简单,其代码的核心和精髓实际都在它的内部静态类ThreadLocalMap中,因此这里我们不再赘述ThreadLocal类的各种接口方法,直接进入主题,一起来研究ThreadLocalMap类相关的源码。
首先我们翻阅Thread类的源码,可以看到这么一句:
public
class Thread implements Runnable {
...
ThreadLocal.ThreadLocalMap threadLocals = null; // 注意这里
...
}
可以看到在每个Thread类的内部,都耦合了一个ThreadLocalMap类型的引用,由于ThreadLocalMap类是ThreadLocal类的私有内嵌类,因此ThreadLocalMap类型的对象只能由ThreadLocal类打理:
public class ThreadLocal<T> {
...
// 内部私有静态类
static class ThreadLocalMap {
...
}
...
}
关于ThreadLocalMap类实现,我们也可以把它理解成是一类哈希表,那么作为哈希表,就要包含:数据结构、寻址方式、哈希表扩容(Rehash),除了哈希表的部分外,ThreadLocalMap还包含了“垃圾回收”的过程。因此,我们将按以上模块分别介绍ThreadLocalMap类的实现。
1. 数据结构
那么接下来我们看看ThreadLocalMap中数据结构的定义:
static class ThreadLocalMap {
static class Entry extends WeakReference<ThreadLocal> {
Object value; // 实际保存的值
Entry(ThreadLocal k, Object v) {
super(k);
value = v;
}
}
/**
* 哈希表初始大小,但是这个值无论怎么变化都必须是2的N次方
*/
private static final int INITIAL_CAPACITY = 16;
/**
* 哈希表中实际存放对象的容器,该容器的大小也必须是2的幂数倍
*/
private Entry[] table;
/**
* 表中Entry元素的数量
*/
private int size = 0;
/**
* 哈希表的扩容阈值
*/
private int threshold; // 默认值为0
private void setThreshold(int len) {
threshold = len * 2 / 3;
}
...
/**
* 并不是Thread被创建后就一定会创建一个新的ThreadLocalMap,
* 除非当前Thread真的用了ThreadLocal
* 并且赋值到ThreadLocal后才会创建一个ThreadLocalMap
*/
ThreadLocalMap(ThreadLocal firstKey, Object firstValue) {
table = new Entry[INITIAL_CAPACITY];
int i = firstKey.threadLocalHashCode
& (INITIAL_CAPACITY - 1);
table[i] = new Entry(firstKey, firstValue);
size = 1;
setThreshold(INITIAL_CAPACITY);
}
可以从上面看到这些信息:
1)存放对象信息的表是一个数组。这类方式和HashMap有点像;
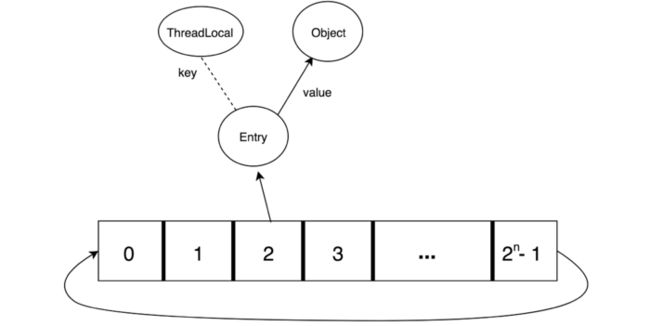
2)数组元素是一个WeakReference(弱引用)的实现。弱引用是一类比软引用更加脆弱的类型(按照强弱程度分别为 强引用>软引用 > 弱引用 > 虚引用),至于为什么使用弱引用,这是因为线程的执行时间可能很长,但是对应的ThreadLocal对象生成时间未必有线程的执行寿命那般长,在对应ThreadLocal对象由该线程作为根节点出发,逻辑上不可达时,就应该可以被GC,如果使用了强引用,该对象无法被成功GC,因此会带来内存泄露的问题;
3)哈希表的大小必须是2的N次方。至于这部分,在后面会提到,实际上这个长度的设计和位运算有关;
4)阈值threshold。这个概念同样和HashMap内部实现的阈值类似,当数组长度到了某个阈值时,为了减少散列函数的碰撞,不得不扩展容量大小;
结构如图所示,虚线部分表示的是一个弱引用:
2、寻址方式
首先我们根据getEntry()方法一起来观察一下根据哈希算法寻址某个元素的过程,可以看到,这是一类“直接寻址法”的实现:
private Entry getEntry(ThreadLocal key) {
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
if (e != null && e.get() == key)
return e;
else
// 寻址失败,需要继续探察
return getEntryAfterMiss(key, i, e);
}
在这里我们注意到一个“key.threadLocalHashCode”对象,该对象的生成方式如下:
public class ThreadLocal<T> {
private final int threadLocalHashCode =
nextHashCode();
/**
* 计算哈希值相关的魔数
*/
private static final int HASH_INCREMENT = 0x61c88647;
/**
* 返回递增后的哈希值
*/
private static int nextHashCode() {
return nextHashCode.getAndAdd(HASH_INCREMENT);
}
根据一个固定的值0x61c88647(为什么是这个数字,我们稍后再提),在每次生成新的ThreadLocal对象时递增这个哈希值
之前已经提到了,table的length必须满足2的N次方,因此按照位运算"key.threadLocalHashCode & (table.length - 1)"获得是哈希值的的末N位,根据这一哈希算法计算的结果取到哈希表中对应的元素。可是这个时候,又会遇到哈希算法的经典问题——哈希碰撞。
针对哈希碰撞,我们通常有三种手段:
1)拉链法。这类哈希碰撞的解决方法将所有关键字为同义词的记录存储在同一线性链表中。JDK1.7已经在HashMap类中实现了,感兴趣的可以去看看;
2)再哈希法。当发生冲突时,使用第二个、第三个、哈希函数计算地址,直到无冲突时。缺点:计算时间增加。比如第一次按照姓首字母进行哈希,如果产生冲突可以按照姓字母首字母第二位进行哈希,再冲突,第三位,直到不冲突为止;
3)开放地址法(ThreadLocalMap使用的正是这类方法)。所谓的开放定址法就是一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入。
那么我们一起来看看ThreadLocalMap的实现,我们通过getEntry()方法按照哈希函数取得哈希表中的值,在该方法内部,我们将用到一个getEntryAfterMiss()方法:
/**
* 如果在getEntry方法中不能马上找到对应的Entry,将调用该方法
*
* @param e table[i]对应的entry值
*/
private Entry getEntryAfterMiss(
ThreadLocal key, int i, Entry e) {
Entry[] tab = table;
int len = tab.length;
while (e != null) {
ThreadLocal k = e.get();
if (k == key)
return e;
if (k == null)
// 对从该位置开始的的对象进行清理(开发者主动GC)
expungeStaleEntry(i);
else
// 查找下一个对象
i = nextIndex(i, len);
e = tab[i];
}
return null;
}
在该方法中可以看到,当根据哈希函数直接查找对应的位置失败后,就会从当前的位置往后开始寻找,直到找到对应的key值,另外,如果发现有key值已经被GC了,那么相应的,也应该启动expungeStaleEntry()方法,清理掉无效的Entry。
类似的,ThreadLocalMap类的set方法,也是按照 “根据哈希函数查找位置→ 如果查找不成功就沿着当前位置查找 → 如果发现垃圾数据及时清理” 的路径进行着:
private void set(ThreadLocal key, Object value) {
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal k = e.get();
if (k == key) {
e.value = value;
return;
}
if (k == null) {
// 清理无效数据
replaceStaleEntry(key, value, i);
return;
}
}
tab[i] = new Entry(key, value);
int sz = ++size;
// 清理无效数据后判断是否仍需扩容
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash(); // 扩容
}
该函数在“寻址方式”上和getEntry()方法类似,因此就不展开阐述了。
为什么是0x61c88647
这个魔数的选取与斐波那契散列有关,0x61c88647对应的十进制为1640531527。斐波那契散列的乘数可以用(long) ((1L << 31) * (Math.sqrt(5) - 1))可以得到2654435769,如果把这个值给转为带符号的int,则会得到-1640531527(也就是0x61c88647)。通过理论与实践,当我们用0x61c88647作为魔数累加为每个ThreadLocal分配各自的ID也就是threadLocalHashCode再与2的幂取模,得到的结果分布很均匀。ThreadLocalMap使用的是线性探测法,均匀分布的好处在于很快就能探测到下一个临近的可用slot,从而保证效率。
3、哈希表扩容(Rehash)
我们一起来回忆一下,table对象的起始容量是可以容纳16个对象,在set()方法的尾部可以看到以下内容:
// 清理无效数据后判断是否仍需扩容
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash(); // 扩容
如果当前容量大小大于阈值(threshold)后,将会发起一次扩容(rehash)操作。
private void rehash() {
expungeStaleEntries();
if (size >= threshold - threshold / 4)
resize();
}
在该方法中,首先尝试彻底清理表中的无效元素(失效的弱引用),然后判断当前是否仍然大于threshold值的3/4。
而threshold值,在文章开始的时候就已经提起过,是当前容量大小的2/3:
/**
* 在当前容量大小超过table大小的2/3时可能会触发一次rehash操作
*/
private void setThreshold(int len) {
threshold = len * 2 / 3;
}
那么我们一起看看resize()方法:
/**
* 成倍扩容table
*/
private void resize() {
Entry[] oldTab = table;
int oldLen = oldTab.length;
int newLen = oldLen * 2; // 直接倍增
Entry[] newTab = new Entry[newLen];
int count = 0;
for (int j = 0; j < oldLen; ++j) {
Entry e = oldTab[j];
if (e != null) {
ThreadLocal k = e.get();
if (k == null) {
e.value = null; // 释放无效的对象
} else {
int h = k.threadLocalHashCode & (newLen - 1);
while (newTab[h] != null)
h = nextIndex(h, newLen);
newTab[h] = e;
count++;
}
}
}
setThreshold(newLen);
size = count;
table = newTab;
}
在该方法内部,首先创建一个新的表,表的大小是原来表大小的两倍,然后再逐个复制原表内容到新表中,如果发现有无效对象,则把Entry对象中对应的value引用置为NULL,方便后面垃圾收集器对该对象的回收。
4、垃圾回收
此时笔者再次贴出引用的图示:
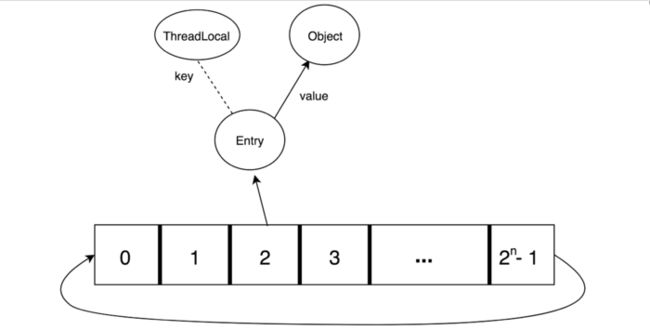
可以看到Entry对象到ThreadLocal对象是一个弱引用的关系,而指向Object对象仍然是一个强引用的关系,因此,虽然由于弱引用的ThreadLocal对象随着ROOT路径不可达而被垃圾收集器清理后,但是仍然残留有Object对象,不及时清理会存在“内存泄露”的问题。
那么我们看看和垃圾收集有关的方法:
/**
* 该方法将在set方法中被调用,在set某个值时,通过散列函数指向某个位置,然而
* 此时该位置上存在一个垃圾Entry,将会尝试使用此方法用新值覆盖旧值,不过该方
* 法还承担了“主动垃圾回收”的功能。
*
* @param key 以ThreadLocal类对象作为key
* @param value 通过ThreadLocal类对象找到对应的值
*/
private void replaceStaleEntry(
ThreadLocal key, Object value,int staleSlot) {
Entry[] tab = table;
int len = tab.length;
Entry e;
// 向前扫描,查找最前的一个无效slot
int slotToExpunge = staleSlot;
for (int i = prevIndex(staleSlot, len);
(e = tab[i]) != null;
i = prevIndex(i, len))
if (e.get() == null)
slotToExpunge = i;
// 向后遍历table,直到当前表中所指的位置是一个空值或
// 者已经找到了和ThreadLocal对象匹配的值
for (int i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal k = e.get();
// 之前设置新值时,如果当前哈希位存在冲突,
// 那么就要顺延到后面空的slot中存放。
// 既然当前哈希位原来对应的ThreadLocal对象已经
// 被回收了,那么被顺延放置的ThreadLocal对象
// 自然就要被向前调整到当前位置中去
if (k == key) {
e.value = value;
tab[i] = tab[staleSlot];
tab[staleSlot] = e; // swap操作
if (slotToExpunge == staleSlot)
slotToExpunge = i;
// 清理一波无效slot
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
return; // 找到了就直接返回
}
// 如果当前的slot已经无效,并且向前扫描过程中没有无效slot,
// 则更新slotToExpunge为当前位置
if (k == null && slotToExpunge == staleSlot)
slotToExpunge = i;
}
// key没找到就原地创建一个新的
tab[staleSlot].value = null;
tab[staleSlot] = new Entry(key, value);
// 在探测过程中如果发现任何无效slot,
// 则做一次清理(连续段清理+启发式清理)
if (slotToExpunge != staleSlot)
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
}
/**
* 这个函数做了两件事情:
* 1)清理当前无效slot(由staleSlot指定位置)
* 2)从staleSlot开始,一直到null位,清理掉中间所有的无效slot
*/
private int expungeStaleEntry(int staleSlot) {
Entry[] tab = table;
int len = tab.length;
// 清理当前无效slot(由staleSlot指定位置)
tab[staleSlot].value = null;
tab[staleSlot] = null;
size--;
// 从staleSlot开始,一直到null位,清理掉中间所有的无效slot
Entry e;
int i;
for (i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal k = e.get();
if (k == null) {
// 清理掉无效slot
e.value = null;
tab[i] = null;
size--;
} else {
int h = k.threadLocalHashCode & (len - 1);
// 当前ThreadLocal不在它计算出来的哈希位上,
// 说明之前在插入的时候被顺延到哈希位后面放置了,
// 因此此时需要向前调整位置
if (h != i) {
tab[i] = null;
// 从计算出来的哈希位开始往后查找,找到一个适合它的空位
while (tab[h] != null)
h = nextIndex(h, len);
tab[h] = e;
}
}
}
return i;
}
/**
* 启发式地清理slot,
* n是用于控制控制扫描次数的
* 正常情况下如果log2(n)次扫描没有发现无效slot,函数就结束了
* 但是如果发现了无效的slot,将n置为table的长度len,做一次连续段的清理
* 再从下一个空的slot开始继续扫描
*/
private boolean cleanSomeSlots(int i, int n) {
boolean removed = false;
Entry[] tab = table;
int len = tab.length;
do {
i = nextIndex(i, len);
Entry e = tab[i];
if (e != null && e.get() == null) {
n = len;
removed = true;
i = expungeStaleEntry(i);
}
} while ( (n >>>= 1) != 0);
return removed;
}
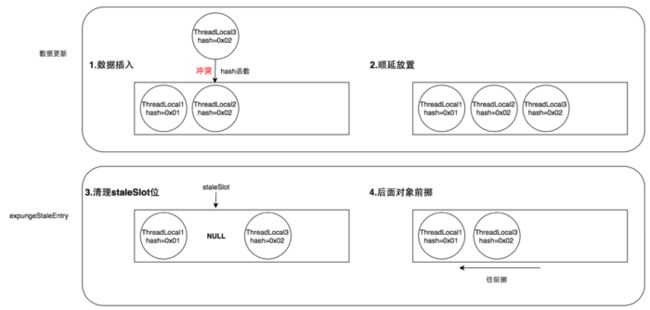
下面我来图解一下expungeStaleEntry方法的流程:
以上是ThreadLocal源码介绍的全部内容。下面笔者将补充一些在实际开发过程中遇到的问题,作为补充信息一并分享。
六、经验之谈
1、谨慎在ThreadExecutorPool中使用ThreadLocal
在ThreadExecutorPool中,Thread是复用的,因此每个Thread对应的ThreadLocal空间也是被复用的,如果开发者不希望ThreadExecutorPool中的下一个Task能读取到上一个Task在ThreadLocal中存入的信息,那就不应该使用ThreadLocal。
举个例子:
final ThreadLocal threadLocal =
new ThreadLocal();
// 线程池大小为1
ThreadPoolExecutor threadPoolExecutor =
new ThreadPoolExecutor(1, 1, 60, TimeUnit.SECONDS,
new LinkedBlockingDeque());
// 任务1
threadPoolExecutor.execute(new Runnable() {
public void run() {
threadLocal.set("first insert");
}
});
// 任务2
threadPoolExecutor.execute(new Runnable() {
public void run() {
System.out.println(threadLocal.get());
}
});
像这样,第二个任务能读取到第一个任务插入的数据。但是如果此时线程池中任务一抛出一个异常出来:
final ThreadLocal threadLocal =
new ThreadLocal();
// 线程池大小为1
ThreadPoolExecutor threadPoolExecutor =
new ThreadPoolExecutor(1, 1, 60, TimeUnit.SECONDS,
new LinkedBlockingDeque());
// 任务1
threadPoolExecutor.execute(new Runnable() {
public void run() {
threadLocal.set("first insert");
// 抛一个异常
throw new RuntimeException("throw a exception");
}
});
// 任务2
threadPoolExecutor.execute(new Runnable() {
public void run() {
System.out.println(threadLocal.get());
}
});
那么此时,第二个任务无法读取到第一个任务插入的数据(因为第一个线程因为抛异常已经死了,任务二用的是新线程执行)
2、不要滥用ThreadLocal
很多开发者为了能够在类和类直接传输数据,而不想把方法里的参数表写得过于庞大,那么可能会带来类于类直接重度耦合的问题,这样不利于后面的开发。
3、要先set才能get
继续举个例子:
public class TestMain {
public ThreadLocal intThreadLocal =
new ThreadLocal();
public int getCount() {
return intThreadLocal.get();
}
public static void main(String[] args) {
System.out.println(new TestMain().getCount());
}
}
在这里,没有先set就直接get,将会抛出一个NullPointerException,原因我们一起来回顾一下ThreadLocal的代码:
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null)
return (T)e.value;
}
return setInitialValue(); // 返回了NULL导致NPE
}
private T setInitialValue() {
T value = initialValue(); // 这里返回了NULL
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
return value;
}
以上就是“线程封闭之ThreadLocal源码详解”的全部内容了,有问题欢迎随时交流~