HIVE的常用操作-建库和表-插入数据
使用hive
-----------------------
启动hadoop
启动hive
创建数据库:
create database myhive;
查看数据库:
hive (default)> show databases;
OK
database_name
default
myhive
数据准备:employees.txt
1201 Gopal 45000 Technical manager
1202 Manisha 45000 Proof reader
1203 Masthanvali 40000 Technical writer
1204 Krian 40000 Hr Admin
1205 Kranthi 30000 Op Admin
在myhive库中创建表
use myhive;
hive (myhive)> create table myhive.employee (eud int,name String,salary String,destination String) COMMENT 'Employee table' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n' STORED AS TEXTFILE;
OK
Time taken: 0.109 seconds
向hive中加载数据 (local模式) 查询数据
hive (myhive)> load data local inpath '/home/hadoop/data/employees.txt' into table employee;
Loading data to table myhive.employee
OK
Time taken: 0.288 seconds
hive (myhive)> select * from employee;
OK
employee.eud employee.name employee.salary employee.destination
1201 Gopal 45000 Technical manager
1202 Manisha 45000 Proof reader
1203 Masthanvali 40000 Technical writer
1204 Krian 40000 Hr Admin
1205 Kranthi 30000 Op Admin
Time taken: 0.128 seconds, Fetched: 5 row(s)
如下图:local模式加载数据到hive ,实际加载到了hdfs
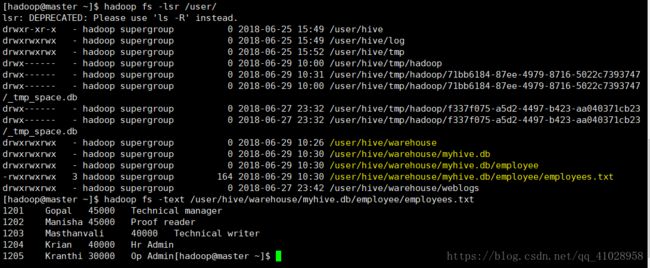
非local模式会把数据加载到hive
数据准备: data.txt
1206 tom 5000 Proof reader
1207 liming 40000 Technical writer
[hadoop@master data]$ hadoop fs -mkdir /data
[hadoop@master data]$ hadoop fs -put ./data.txt /data
hive (myhive)> load data inpath '/data/data.txt' into table employee1;
Loading data to table myhive.employee1
OK
Time taken: 0.274 seconds
hive (myhive)> select * from employee1;
OK
employee1.eud employee1.name employee1.salary employee1.destination
1206 tom 5000 Proof reader
1207 liming 40000 Technical writer
Time taken: 0.103 seconds, Fetched: 2 row(s)
在local模式的情形中进行如下操作
[hadoop@master data]$ hadoop fs -put ./data.txt /user/hive/warehouse/myhive.db/employee
[hadoop@master data]$ hadoop fs -cat /user/hive/warehouse/myhive.db/employee/data.txt
1206 tom 5000 Proof reader
1207 liming 40000
在同一路径数据文本格式相同数据加载成功(并非只能load data..............)也可以进行数据的加载
hive (myhive)> select * from employee;
OK
employee.eud employee.name employee.salary employee.destination
1206 tom 5000 Proof reader
1207 liming 40000 Technical writer
1201 Gopal 45000 Technical manager
1202 Manisha 45000 Proof reader
1203 Masthanvali 40000 Technical writer
1204 Krian 40000 Hr Admin
1205 Kranthi 30000 Op Admin
Time taken: 0.162 seconds, Fetched: 7 row(s)
向employee表中插入数据 -mapreduce-job
** (HIVE: 支持插入, 不支持删除和更新
hive (myhive)> insert into employee(eid,name) values(1208,'jack')
简单操作 (在hive中执行shell命令 本地)
hive (myhive)> !ls /home/hadoop/data;
1901
1902
data.txt
employees.txt
hive (myhive)> !cat data.txt;
cat: data.txt: 没有那个文件或目录
Command failed with exit code = 1
hive (myhive)> !cat /home/hadoop/data/data.txt;
1206 tom 5000 Proof reader
1207 liming 40000 Technical
其他的shell命令在hive中的用法与上面的相同
(在hive中执行shell命令 HDFS)
hive (default)> dfs -ls /;
Found 7 items
drwxr-xr-x - hadoop supergroup 0 2018-06-29 10:58 /data
drwxr-xr-x - hadoop supergroup 0 2018-06-26 22:27 /hbase
drwxr-xr-x - hadoop supergroup 0 2018-06-27 20:52 /home
drwxr-xr-x - hadoop supergroup 0 2018-06-24 20:54 /input
drwxr-xr-x - hadoop supergroup 0 2018-06-28 22:54 /mapreduce
drwx------ - hadoop supergroup 0 2018-06-29 10:50 /tmp
drwxr-xr-x - hadoop supergroup 0 2018-06-25 15:49 /user