【Hadoop环境搭建】九.分布式离线计算框架---MapReduce
Hadoop中有两个重要的组件:一个是HDFS,另一个是MapReduce,HDFS主要用来存储大批量的数据,而MapReduce则是通过计算来发现数据中有价值的内容。
本章我们主要介绍MapReduce中的以下几方面内容:
- MapReduce的应用场景、工作机制和编程模型
- MapReduce的执行原理
- WordCount本地测试实例
9.1 安装Linux版本的eclipse
9.1.1 下载安装包并解压文件
首先在eclipse官网下载Linux版本的eclipse,这里我下载的是eclipse-jee-luna-SR2-linux-gtk-x86_64.tar.gz
下载地址:https://www.eclipse.org/downloads/packages/release/luna/sr2
根据自己的电脑选择32位或者64位版本的下载
下载完成后使用MobaXterm上传到root下面的app文件夹,并使用下面的tar命令解压到该文件夹中
tar -zxvf eclipse-jee-indigo-SR2-linux-gtk-x86_64.tar.gz
9.1.2 启动eclipse
这里有几种启动eclipse的方法(这里我均以/root/workspace作为工作目录):
(1)进入到/root/app/eclipse文件夹下,双击eclipse即可启动(这里我的不可以)

(2)使用命令行进入/root/app/eclipse,输入./eclipse即可启动eclipse
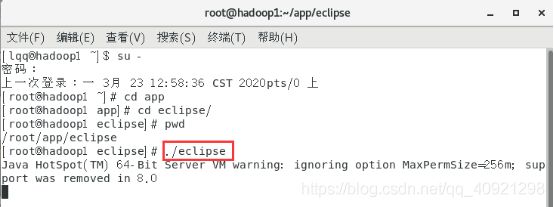
这里有一个警告,字面意思是MaxPermSize不需要我们配置了,所以我就按照它的方法把default VM arguments中MaxPermSize参数给删掉就不会出现上面的提示了。
解决方法:
点击工具栏window - Preferences,点击java - Installed jres,找到对应的jre,对其进行编辑即可。

在java7中设置参数:-Xmx512m -XX:MaxPermSize=128m
在java8中设置参数:-Xmx512m
(3)创建桌面快捷方式
方法一:
1)右击桌面,点击“Create Launcher”

2)打开“Create Launcher”界面->填写软件“名称”->选择“可执行文件的路径”->选择“图标”->“OK”

3)启动eclipse进程
双击桌面上的Eclipse图标,启动eclipse进程
方法二:
使用上面方法不行的话(比如说点击右键没有“Create Launcher”),可以使用这种方法
1)在root用户的桌面环境下,给eclipse创建桌面快捷方式:
touch /usr/share/applications/eclipse.desktop
2)vim /usr/share/applications/eclipse.desktop
添加如下内容:
[Desktop Entry]
Type=Application
Name=eclipse
Exec=/root/app/eclipse/eclipse //存放eclipse的绝对路径
GenericName=eclipse
Comment=Java development tools
Icon=/root/app/eclipse/icon.xpm //eclipse图标存放路径
Categories=Application;Development;
Terminal=false

然后保存退出。
将上面创建的eclipse.desktop 拷贝到桌面目录,这样就会在桌面看到一个eclipse的快捷图标。
点击该图标,可能会提示"未信任的应用启动器的问题",处理方法是:
右键eclipse图标,选择属性,在弹出的对话框里面选择权限,勾选 允许作为程序执行文件。
9.1.3 简单配置
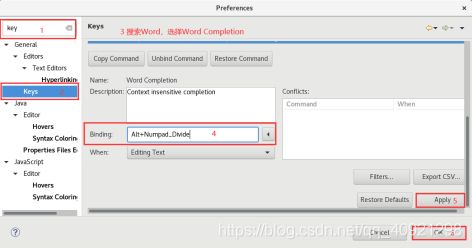
选择Window-Preferences,在搜索框中搜索key,点击Keys,然后在该搜索框中输入Word,选择Word Completion,设置快捷键为Alt+/,然后应用并保存。
9.2 MapReduce概述
Hadoop作为开源组织下最重要的项目之一,自推出后得到了全球学术界和工业界的广泛关注、推广和普及。它是开源项目Lucene(搜索索引程序库)和 Nutch(搜索引擎)的创始人Doug Cutting于2004年推出的。当时Doug Cutting发现MapReduce正是其所需要解决大规模Web数据处理的重要技术,因而模仿 Google MapReduce,基于Java设计开发了一个称为 Hadoop的开源MapReduce并行计算框架和系统。
9.2.1 MapReduce的特点
前面我们已经讲到Hadoop的HDFS用于存储数据,MapReduce用来计算数据。
接着来介绍一下MapReduce的特点。
MapReduce适合处理离线的海量数据,这里的“离线”可以理解为存在本地,非实时处理。离线计算往往需要一段时间,如几分钟或者几个小时,根据业务数据和业务复杂度有所区别。MapReduce往往处理大批量数据,比如PB级别或者ZB级别。
MapReduce有以下特点:
- 易于编程:如果要编写分布式程序,只需要实现一些简单接口,与编写普通程序类似,避免了复杂的过程。同时,编写的这个分布式程序可以部署到大批量廉价的普通机器上运行。
- 具有良好的扩展性:是指当一台机器的计算资源不能满足存储或者计算的时候,可以通过增加机器来扩展存储和计算能力。
- 具有高容错性: MapReduce设计的初衷是可以使程序部署运行在廉价的机器上,廉价的机器坏的概率相对较高,这就要求其具有良好的容错性。当一台机器“挂掉”以后,相应数据的存储和计算能力会被移植到另外一台机器上,从而实现容错性。
- 适合PB级以上海量数据的离线处理。
9.2.2 MapReduce的应用场景
MapReduce的应用场景主要表现在从大规模数据中进行计算,不要求即时返回结果的场景,比如以下典型应用:
- 单词统计。
- 简单的数据统计,比如网站PV和UV统计。
- 搜索引擎建立索引。
- 搜索引擎中,统计最流行的K个搜索词。
- 统计搜索词频率,帮助优化搜索词提示。
- 复杂数据分析算法实现。
前面提到, Hadoop的MapReduce是来自于Google的 MapReduce,其实Google公司很早就将“搜索引擎建立索引”应用到了搜索中。
前面介绍了MapReduce的优点和适用场景,下面介绍MapReduce不适用的方面:
- 实时计算,MapReduce不合适在毫秒级或者秒级内返回结果。
- 流式计算,MapReduce的输入数据集是静态的,不能动态变化,所以不适合流式计算。
- DAG计算,如果多个应用程序存在依赖关系,并且后一个应用程序的输入为前一个的输出,在这种情况下也不适合 MapReduce。
9.3 MapReduce的执行过程
前面我们了解了MapReduce的基本概念,接下来介绍MapReduce的执行过程。
MapReduce的执行过程比较复杂,我们先从一个 Wordcount实例着手,从总体上理解MapReduce的执行过程。
9.3.1 单词统计实例
单词统计是最能体现MapReduce思想的程序,结构简单,上手容易。
单词统计的大致功能是:
统计单个或者多个文本文件中每个单词出现的次数,并将每个单词及其出现频率按照“about 3”形式的列表输出,其基本如下所示:
图中主要分为Split、Map、Shuffle和Reduce阶段,每个阶段在Word Count中的作用如下:
- Split阶段,首先大文件被切分成多份,假设这里被切分成了3份,每一行代表一份。
- Map阶段,解析出每个单词,并在后边记上数字1。
- Shuffle阶段,将每一份中的单词分组到一起,并默认按照字母进行排序。
- Reduce阶段,将相同的单词进行累加。
- 输出结果。

9.3.2 MapReduce执行过程
从Word Count实例中,可以基于单词统计大概了解MapReduce的过程,接下来我们从理论层面来介绍MapReduce的执行过程,如下图所示。
具体执行过程如下:
(1)数据会被切割成数据片段。
(2)数据片段以key和value的形式被读进来,默认是以行的下标位作为key,以行的内容作为value。
(3)数据会传入Map中进行处理,处理逻辑由用户自行定义,在Map中处理完后还是以key和value的形式输出。
(4)输出的数据传给了Shuffle(洗牌),Shuffle完成对数据的排序和合并等操作,但是Shuffle不会对输入的数据进行改动,所以还是key2和value2。
(5)数据随后传给了Reduce进行处理,Reduce处理完后,生成key3和 value3。
(6)Reduce处理完的数据会被写到HDFS的某个目录中。

如果读者是第一次看到这个执行过程可能不太好理解,其实这就是MapReduce程序自己的处理流程,都是按照这个“套路”运行的。下面对split阶段、Map和 Reduce阶段以及 Shuffle阶段分别展开介绍。
9.3.3 MapReduce的文件切片—Split
split的大小默认与 block对应,也可以由用户任意控制。MapReduce的split大小计算公式如下:
max(min split, min(max split, block))
其中,max.split = totalSize/numSpilt,totalSize为文件大小,numSpilt为用户设定的map task个数,默认为1;mnin.split = InputSplit的最小值,具体可以在配置文件中配置参数 marred.min.split.size,不配置时默认为1B,block是HDFS中块的大小。
举例来说:把一个258MB的文件上传到HDFS上,假设block块大小是128MB,那么它就会被分成3个block块,与之对应产生3个Split,所以最终会产生3个map task。而第3个block块里存的文件大小只有2MB,它的block块大小是128MB,那么它实际占用多大空间呢?通过以上公式可知其占用的是实际的文件大小,而非一个块的大小。
9.3.4 Map过程和Reduce过程
Map的实现逻辑和Reduce的实现逻辑都是由程序员完成的,其中Map的个数和Split的个数对应起来,也就是说一个Split切片对应一个Map任务,关于Reduce的默认数是1,程序员可以自行设置。另外需要注意的是,一个程序可能只有一个Map任务却没有Reduce任务,也可能是多个MapReduce程序串接起来,比如把第一个MapReduce的输出结果当作第二个MapReduce的输入,第二个MapReduce的输出成为第三个MapReduce的输入,最终才可以完成一个任务,通过阅读后面的MapReduce实例,读者会对Map和Reduce有进一步的理解。
9.3.5 Shuffle过程
Shuffle又叫“洗牌”,它起到连接Map任务与Reduce务的作用,在这里需要注意的是,Shuffle不是一个单独的任务,它是MapReduce执行中的步骤,如下图所示。
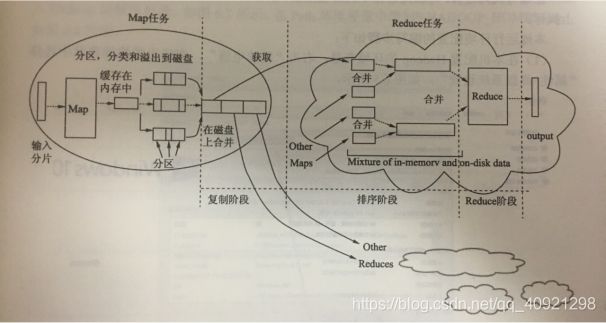
从图中可以看出,Shuffle分为两部分,一部分在Map端,另一部分在Reduce端,Map处理后的数据会以key、value的形式存在缓冲区中(buffer in memory),缓冲区大小为128MB。当该缓冲区快要溢出时(默认80%),会将数据写到磁盘中生成文件,就是溢写操作(spill to disk)。溢写磁盘的过程是由一个线程来完成,溢写之前包括Partition(分区)和Sort(排序),Partition和Sort都有默认实现,其中Partition分区默认是“hash值%reduce数量”进行分区的,分区之后的数据会进入不同的Reduce,而Sort是默认按照字母顺序进行排序的。读者可以根据业务需求进行编写,具体可以参考后面的实例。溢写之后会在磁盘上生成多个文件,多个文件会通过merge线程完成文件的合并,由多个小文件生成一个大文件。
合成之后的数据(以key和value的形式存在)会基于Partition被发送到不同的Reduce上,如图中任务之间的长箭头所示,Reduce会从不同的Map上取得“属于”自己的数据并写入磁盘,完成merge操作减少文件数量,并调用Reduce程序,最终通过Output输出。
9.4 MapReduce实例 - 单词统计
本节中,我们将从实现层面来介绍如何开发MapReduce程序,MapReduce的编程遵循一个特定流程,主要是编写Map和Reduce函数。
9.4.1 WordCount本地测试实例简介
前面我们通过一个WordCount实例介绍了MapReduce执行过程,在这里用一个WordCoun的单词统计实例来介绍如何编写MapReduce程序。
一个完整的MapReduce程序主体主要分为两部分,一个是Mapper,另一个是Reducer。
用户自定义的Mapper.java类解析key/value对值,然后产生一个中间 key/value对值的集合,把所有具有相同中间key值的中间value值集合在一起后传递给Reduce函数。
用户自定义的 Reducer.java类接受一个中间key的值和相关的一个value值的集合。Reduce函数合并这些value值,形成一个较小的value值的集合。每次Reduce函数调用时只产生0或1个value输出值。通常我们通过一个迭代器把中间的value值提供给Reduce函数,这样就可以处理无法全部放入内存中的大量的value值的集合。
9.4.2 WordCount具体实现
(1)新建项目
点击file-new-other-Java Project,下一步

输入项目名称TestHadoop,这里可以选择已安装的jdk,然后下一步,完成

(2)导入jar包
在桌面创建一个libs文件夹
1)选择/root/app/hadoop-2.5.0/share/hadoop/common下面的三个jar包以及该文件夹下的lib文件夹内的所有jar包复制到桌面libs文件夹内
2)同样,在/root/app/hadoop-2.5.0/share/hadoop/hdfs文件夹内执行相同操作

这里如果一些包产生了冲突,选择全部替换就可以了

3)同样在/root/app/hadoop-2.5.0/share/hadoop/mapreduce文件夹执行相同操作
4)同样在/root/app/hadoop-2.5.0/share/hadoop/yarn文件夹执行相同操作
至此所有jar包就拷贝完成了,然后把这些文件夹全都关闭即可
5)把桌面的libs文件夹拷贝到刚才新建的项目中去,按住Shift键选择所有的以来jar包,右击Build Path - Add to Build Path,然后所有的jar包就全部形成依赖了
(3)在worksapce中创建一个文本文件word.txt用来做测试文件
(4)创建包com.hadoop.mapreduce

(5)新建一个WordCoundMapper类,继承Mapper,这是一个Map过程,对输入文本进行词汇的分割并循环输出给Reducer。代码如下:

WordCountMapper.java
package com.hadoop.mapreduce;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordCountMapper extends Mapper{
@Override
protected void map(LongWritable key, Text value,Mapper.Context context)
throws IOException, InterruptedException {
String line = value.toString();
//用空格进行分割
String words[] = line.split(" ");
context.write(NullWritable.get(), new LongWritable(words.length));
}
}
(6)新建WordCountReduce类,继承Reducer;这是一个Reduce过程,将从Map传入的词汇进行分组合并,并通过文本和单词统计量的方式输出。代码如下:
WordCountReduce.java
package com.hadoop.mapreduce;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReduce extends Reducer{
//数组分组合并输出
@Override
protected void reduce(NullWritable key, Iterable v2s, Reducer.Context context)
throws IOException, InterruptedException {
long counter = 0;
for(LongWritable v:v2s){
counter += v.get();
}
context.write(NullWritable.get(), new LongWritable(counter));
}
}
(7)创建主方法。
上面编写了Mapper和Reducer,为了使Mapper和Reducer正常运行,还需要编写主方法WordCount。主方法中需要先设置要连接的HDFS和要读取的文件及处理后的文件在HDFS中的路径,知名我们所要进行的Map和Reduce过程的类,然后开始MapReduce的离线数据处理。代码如下:
WordCount.java
package com.hadoop.mapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(WordCount.class);
//Mapper方法名
job.setMapperClass(WordCountMapper.class);
//Reducer方法名
job.setReducerClass(WordCountReduce.class);
//Map输出的key类型
job.setMapOutputKeyClass(NullWritable.class);
//Map输出的value类型
job.setMapOutputValueClass(LongWritable.class);
//Reduce输出的key类型
job.setOutputKeyClass(NullWritable.class);
//Reduce输出的value类型
job.setOutputValueClass(LongWritable.class);
//读取的文件位置
FileInputFormat.setInputPaths(job, new Path("file:///root/workspace/word.txt"));
//处理完之后的数据存放位置,注意输出的文件夹如果已经存在会报错
FileOutputFormat.setOutputPath(job, new Path("file:///root/workspace/mapreduceOut"));
job.waitForCompletion(true);
}
}
(8)测试运行
1)开启Hadoop进程
在hadoop1虚拟机中的hadoop-2.5.0目录下输入sbin/start-dfs.sh
在hadoop2虚拟机中的hadoop-2.5.0目录下输入sbin/start-yarn.sh
此时集群模式下三台虚拟机的进程均已启动(检验方法可对照第七章最开始的表格)
2)运行项目
在eclipse项目中点击右键Run as - Java Application,然后观察控制台,出现下面信息则表示运行成功
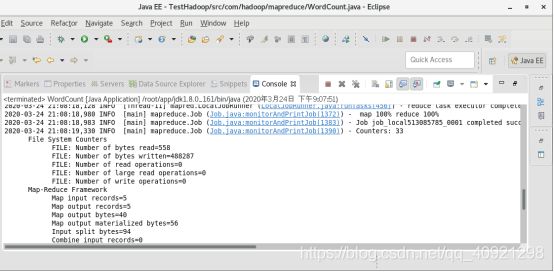
然后在hadoop1的/workspace/mapreduceOut目录下即可看到输出文件,cat一下可以看出word.txt的单词数目为10个
