C++ Primer Plus学习笔记:第七章:函数——C++的编程模块
1.复习
1.函数原型:
就是函数头的{}去掉,加上;,参数列表只写数据类型,如果有默认参数,默认参数的变量可以写在原型里面,也可以写在函数头上,但是不能都写,然后就是说,函数原型可以写变量名,但是他只是一个占位符,你甚至可以连名字也不一样,见下,你可以把第三行int a改为int x=12试试
int ss(int, int, int, int z = 12);
int ss(int b, int c, int d, int a) {
cout << a;
return 0;
}
int main() {
ss(1, 2, 3);
return 0;
然后就是如果返回值和"接受者"的数据类型不一样会自动调用一个转换函数转为目标类型,可以加宽或者缩窄,这个编译器会包警告(谁在意"Waring",程序员除了"Error"还怕什么)告诉你这个会丢失数据
2.函数与数组
一个原始的写法
...
void ss(int t[],int size);
int main(){
int m[20]={
1};
ss(t[],20);
}
void ss(int t[],inr size){
}
注意数组的写法,和new/delete一样不写大小,但是必须注意位置和new/delete不一样
这里的t[]不是表示传输了一个数组,而是一个数组的指针,那么C++设计的时候为什么要设计这么一个语言呢,int* t他不香吗(你想这么写可以),又要为此多写多少重载,C++的设计者们不傻,他们一定会保证每个单词有有作用(我自认为qwq)
首先,不写正式的指针*我们可以像使用数组一样自然的用[]
其次就是前面说的,int* t的t地址一样但是返回的是整个数组的大小,但是int t[]返回的是一个sizeof(int)
这里我们传递的就不是数值(形参),而是地址(实参)【看看人家引入实参多自然,通过这个引入传地址,不想某些书一直用那个变量交换】
最后注意,sizeof无法获取传过去的参数的大小,所以必须加一个变量专门传递数据
- 修改内容
因为正常的传值是传副本,数组是传地址,所以造成的问题就是一旦在函数里面不小心修改了数组数据,整个数据全完蛋,所以我们要把数据保护起来,只需要在在声明的时候在类型前面加一个const就可以了,这不是说这个数据只能接受一个const型数据的数组,而是说这个数组指针是一个const,所以:数据不能通过指针修改,但是可以直接访问修改,然后就是加上const以后数据被强制存储在内存,不会被放回硬盘,速度快一点,eg:
int a[50];
int& b=a;
const int* c=a;
这样a,b可以直接修改数据,但是唯独(*c)不可以,还要注意的是可以吧非const的数组传为const指针,但是const数组不能转化为非const指针
另一种传输数组的方法:
C++还给出了一种叫做抄尾的概念来指定区间,就是说对于数组来说标识符结尾的参数是指向最后一个元素后面一个元素的地址
double ss[20];
work(ss,ss+20);
这里ss+20就是ss[20]了,就是ss[19]的后一个元素(想起来shot函数??)
注意一个优先级

原表格在这里
+的优先级比*取值优先级高,所以 ∗ i t + + < = > ∗ ( i t + + ) 而 不 是 ( ∗ i t ) + + *it++<=>*(it++)而不是(*it)++ ∗it++<=>∗(it++)而不是(∗it)++
下面说二维数组如何传值
就是一个降维的数组嘛
void work(int (*arr)[4],int l)//为什么这么写括号,见以前如何声明两个指针变量区别与普通变量
//这个相当于int 指针类,这个指针类里面有四个元素
//不是说里面有四个指针类的数的数组
//他和void work(int* arr[][4],int l)//是等价的
int main(){
int data[3][4]={
......}
work(data,3)
}
p.s.在我的计算机上,这个二维数组的地址其实是线性的
二维数组A[m][n]可以视为由m个行向量组成的向量,或者是由n个列向量组成的向量。
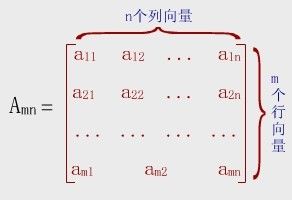
由于计算机的内存是一维的,多维数组的元素应排成线性序列后存入存储器。数组一般不做插入和删除操作,即结构中元素个数和元素间的关系不变。所以采用顺序存储方法表示数组。
1、 行优先存储
将数组元素按行向量排列,第i+1个行向量紧接在第i个行向量后面。
【例】二维数组A[m][n]按行优先存储的线性序列为:
A[0][0]、A[0][1]…A[0][n]、A[1][1]、A[1][1]…A[1][n]…A[m][n]、A[m][1]…A[m][n]
在PASCAL和C语言中数组按行优先顺序存储。
2、 列优先存储
将数组元素按列向量排列,第i+1个列向量紧接在第i个列向量后面。
【例】二维数组A[m][n]按列优先存储的线性序列为:
A[0][0]、A[1][0]…A[m][0]、A[0][1]、A[1][1]…A[m][1]…A[m][1]、A[0][n]…A[m][n]
ORTRAN语言中,数组按列优先顺序存储。
扯远了…
3.函数和C-风格字符串等Struct(Class)
- 把c-字符串作为参数传递给函数:
1.char数组:传地址/抄尾
2.用字符串的字面值(eg:"Hellow")
3.传递字符串的指针
这里的C-字符串和char数组的区别就是有结尾的’\0’
所以可以用strlen可以被使用,这样就不需要传长度了
那么他们是如何重载的呢?
#include 报错
错误 C2084 函数“void work(char *)”已有主体
消息 参见“work”的前一个定义
错误 C2065 “work”: 未声明的标识符
说明他们的本质是相同的,只不过形式不同
- 把C-字符串作为函数返回值返回
char* work(...){
...
return...
}
main(){
char* t=work();
}
-
修改数组
用数组的函数,他们虽然不明写*,但是实际上是使用了传地址,所以数据可以修改
注意不要随意修改 -
对于结构体和类
结构体和类可以像数组一样存储一定的数据,但是他可以像一个数据去传递(刘汝佳说的"一等公民"),但是有一个缺点就是,有的时候比如我的结构体数组开的太大,会导致数据复制数据和传递太占用内存
一般来说
1.当结构体比较小的时候一般使用按值传递
2.当结构体比较大的时候一般使用指针或者引用来节省时间和资源
还有就是返回值作为如果用引用或者指针的话会产生一个问题是我返回来的时候可能这个数据已经被回收了
直接复制下面这个案例:
typedef struct
{
int key;
}ElemType;
typedef struct
{
ElemType *elem;
int length;
}S_TBL;
int Binary_Search(S_TBL tbl,int kx)
{
int mid,flag=0,low,high;
low=1;
high=tbl.length;
while(low<=high)
{
mid=(low+high)/2;
if(kx<tbl.elem[mid].key)
high=mid-1;
else if(kx>tbl.elem[mid].key)
low=mid+1;
else
{
flag=mid;
break;
}
}
return flag;
}
S_TBL Binary_Creat()
{
int i,n;
S_TBL tbl;
printf("Input a number to n(数组的长度):\n");
scanf("%d",&n);
ElemType a[20];
printf("Input some number to tbl :\n");
for(i=1;i<=n;i++)
{
scanf("%d", &a[i].key);
}
tbl.length=n;
tbl.elem=a;
return tbl;
}
Creat完之后,调试Search函数里tbl.elem[mid].key的值都没有,因为:
Binary_Creat()
这个函数中创建ElemType a[20];和S_TBL tbl;都是局部变量;
返回后,栈空间就被清空了,所以会没有值!
建议:在创建的时候可以传个参数过去,比如Binary_Creat(/* S_TBL *tb1 */);可参考!
注意:是传数据过去的时候就用引用,你就算是在调用函数内部new了一个变量也会在{}结束以后自动删除
写一个小函数
atan2()在math库底下
atan 和 atan2 都是求反正切函数,如:有两个点 point(x1,y1), 和 point(x2,y2);
那么这两个点形成的斜率的角度计算方法分别是:
float angle = atan( (y2-y1)/(x2-x1) );
或
float angle = atan2( y2-y1, x2-x1 );
atan 和 atan2 区别:
1:参数的填写方式不同;
2:atan2 的优点在于 如果 x2-x1等于0 依然可以计算,但是atan函数就会导致程序出错;
3.atan无法区分180°内外的角度
结论: atan 和 atan2函数,建议用 atan2函数;
4.函数指针
可以编写将另一个函数的地址作为参数的函数,这样第一个函数就可以找到第二个函数,它允许在不同的时间传递不同的函数地址,这意味在不同时间可以使用不同的函数,那为什么不直接调用函数呢?
我的提问的回答
在C++11之前没有lambda,需要把函数作为参数传给另外一个函数,以便该函数中可以回调它。
这是函数指针的一个最直接的用法
p.s.就是说可以把想要调用的函数的数据发给其他函数
函数指针可以传递转移,保存,可以随机选择
p.s.随机选择好骚啊
因为可能不知道要调什么函数。只能动态赋值。还有一个用处就是我们可以往内存里写数据,通过函数指针把刚才的数据当作代码直接调用
函数指针指向某一函数的地址,可以通过给函数指针赋予不同的值来调用不同的函数。主要用于需要不同条件下执行不同的函数的环境,如回调函数
同样的问题:为什么不把数据写到C++里而要打开文件去读?因为我不知道需要用到的具体数据啊,当然只能放在外部传进来了。同样的,我也不知道具体要调哪个函数,那当然得从外部传进来咯。至于为什么要函数指针,因为C++里函数是不能传的,但是函数所在的地址是可以确定的,把指针传过去你就能找到这个函数,也就相当于传了函数。C++现在有lambda了,但lambda是可以等效为匿名类的,而std::function就是实名的类,既然是类,当然可以传他们的实例了。而他们实质上就是存了一个函数指针+捕获的上下文——还是离不开函数指针的。
依我拙见:函数指针也是一种数据类型,函数是操作数据对象的东东,如果一个函数要操作一类函数,那么函数指针可以胜任该任务(当然,lambda看似更加直接,本质一样)
p.s.赋予函数数据的特性
第一. 函数指针具有抽象的功能: 用惯了C++的虚函数继承(即通常意义上的面向对象技术),可能会觉得继承是实现运行时多态的唯一途径。其实C++继承实现的多态归根结底还是对实际对象所绑定的方法的调用。 通过面向对象的思想,你可以通过结构体加上函数指针来达成原本通过类继承方式实现的多态技术,不过需要额外的代码使函数指针指向你所期望的实现,比如下面代码:
struct Obj {
void (*fun)(Obj*);
void *data;
};
struct DataA {
int a;
};
struct DataB {
char a;
};
void FunA(Obj *o)
{
DataA *v = (DataA *)o->data;
std::cout << v->a;
}
void FunB(Obj *o)
{
DataB *v = (DataA *)o->data;
std::cout << v->a;
}
void test() // 演示多态
{
Obj a;
DataB d;
a.data = (void*)&d;
a.fun = FunB; //实现函数的绑定
a.fun(&a); //通过fun实现多态
}
如果去了解一下C代码的面向对象技术,上面的用法应该不会陌生。面向对象只是思想,不过通常所说的面向对象语言更容易表现出面向对象的语义(如继承、派生、多态等),另外面向对象的语言也提供了一些语法上的约束,比如要求虚函数的签名一致性(参数与返回值一致)、私有成员不能访问等等。第二, 接口与实现分离(与上面的抽象类似): 函数指针可以等价于接口,可以通过指针调用任何任何实现满足接口约束的实现。因此可以给予代码更大的灵活性。 可以类比 C++标准库的std::sort函数,std::sort函数可以指定一个比较函数作为参数,这样sort的调用者可以根据需要自行指定如何进行比较。试想如果sort强制规定了一个比较函数,对于根本无法比较的对象怎么办呢?
- 基础知识
- 获取函数的地址
就是函数名,如果是这么写
int test(int a){
...
}
void work(...){
...
}
int main(){
work(test); //available
work(test()); //not available
}
第一行可以在work内调用函数指针使用test()但是第二个是利用test的返回值作为work()的参数
2.如何声明一个指针变量呢
#include 我们使用这样的方法定义函数指针返回值类型 (*指针名)(被调用函数的参数列表)
这样就有了一个指针变量
有点复杂?感谢C++11
auto p=My_pr;
不过函数的参数列表因为不是直接初始化,所以不能用auto
不要这样过分的用auto
void My_pr(int t) {
cout << (t << 1);
return;
}
void My_pr(double zz) {
cout << zz;
return;
}
int main() {
auto p = My_pr;
return 0;
}
上面的写成这样是可以的
void (*p)(double) = My_pr;
那么如何调用呢?
上面的函数是可以使用的,尝试把(*p)(i);的*去掉,好像还是可以运行的,但是为什么呢?
这个就像是数组一样,加不加&都代表首位地址
对于同类型的三个函数可以使用函数指针数组一起打包
int a(int m){
...
}
int b(int m){
...
}
int c(int m){
...
}
int (*p[3])(int)={
a,b,c}
这里[]里面必须加上数据,
注意这里不能使用auto,从上上次的博文报错信息中有写到,auto只能用于单值变量
但是如果已经有了一个数组,那么就可以通过auto达到复制数组指针到数组指针,因为只有第一位的的指针复制,所以auto可以识别
但是谨防auto写错
auto p=*work;