Innodb是mysql数据库中目前最流行的存储引擎,innodb相对其它存储引擎一个很大的特点是支持事务,并且支持行粒度的锁。今天我重点跟大家分享下innodb行锁实现的基础知识。由于篇幅比较大,文章会按如下的目录结构展开。
{
innodb锁结构
锁机制关键流程
innodb行锁开销
innodb锁同步机制
innodb等待事件实现
}
先从一个简单的例子说起,如下表1
| 时间轴 |
A用户(T1) |
B用户(T2) |
| t1 |
select * from t where id=1 for update |
|
| t2
|
|
select * from t where id=1 for update |
| t3
|
|
挂起状态 |
| t4 |
commit |
|
| t5 |
|
执行成功 |
表1
t1时刻A用户获得表t中id为1这条记录的排它锁,那么当t2时刻B用户再请求该记录的排它锁时,则需要等待;t4时刻A用户提交事务后,则B用户立即也执行成功。这个简单例子的背后有几个问题需要我们思考,第一,innodb如何挂起B用户的执行线程的;第二,用户B又如何在A用户提交事务后,立即执行成功返回的。上面例子本质上是innodb使用锁达到了A用户和B用户有序操作id为1这条记录的目的,下文会详细介绍这个实现过程,同时会介绍锁相关的一些基础知识。
1. Innodb锁结构
Innodb锁结构通过lock_sys管理,所有的行锁lock_t对象都插入hash表中,通过维护hash表,来管理行锁对象,hash表的key值通过页号(space_id,page_no)计算得到。
1) 锁系统结构图
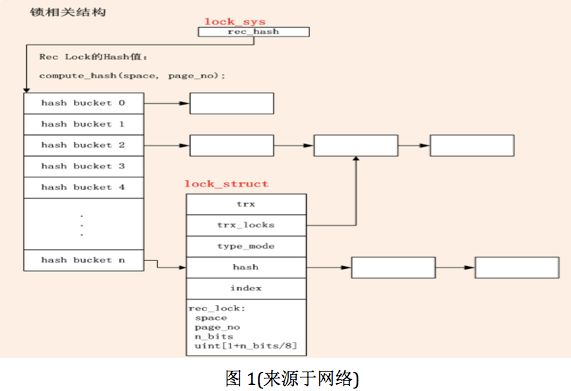
2) 重要数据结构
1 lock_sys
2 {
3 hash_table_t* rec_hash; //行锁hash表
4 srv_slot_t* waiting_threads; //等待对象数组
5 }
6
7 lock_rec_t
8 {
9 ulint space; //表空间编号
10 ulint page_no; //数据页编号
11 ulint n_bits; //数据页包含的记录
12 byte bitmap[1+n_bits/8] //bitmap数组
13 };
2.关键流程
1) 创建锁【lock_rec_create】
a)计算页面中的记录数目,
b)按每个记录一个bit存储,计算需要的存储空间
c)申请lock_t的存储空间
d)初始化bitmap,将heap_no对应的bit位置1,表示上锁
e)将锁对象指针插入hash链表
f)将锁对象插入到事务的锁链表
2) 查询某一个记录上锁情况:(是否上锁,锁类型)
a) 获取记录信息: (space_id,page_no),和heap_no
b) 根据(space_id,page_no)查找hash表,获取锁对象lock _t
c) 根据锁对象内容,判断是共享锁还是排它锁
d) 若存在,遍历锁对象的bitmap,确定heap_no对应的位是否为1。
e) 为1,表示已经加锁
3) 上行锁
a) 查找hash表,判断页面上是否有锁
b) 若不存在,则创建锁,将锁对象插入hash链表
c) 若存在,判断是否事务已有更强的锁存在 (lock_rec_has_expl)
d) 若是,跳转5,若不是,跳转6(lock_rec_lock_slow)
e) 根据页面的heap_no设置bit位,结束。
f) 判断请求锁是否有锁冲突
g)若是,创建锁(模式LOCK_WAIT),设置wait_lock (lock_rec_enqueue_waiting)
h)若不是,上锁成功,加入锁队列(lock_rec_add_to_queue)
i) 上层调用根据返回的错误码,调用锁等待逻辑(lock_wait_suspend_thread)
4) 锁等待【lock_wait_suspend_thread】
a) 根据工作线程信息获取事务信息;
b) 申请slot节点(lock_wait_table_reserve_slot),初始化等待事件;
c) 设置等待事件(linux中通过条件变量实现),将线程挂起
调用堆栈
#0 pthread_cond_wait
#1 os_cond_wait(pthread_cond_t*, os_fast_mutex_t*) ()
#2 os_event_wait_low(os_event*, long) ()
#3 lock_wait_suspend_thread(que_thr_t*) ()
#4 row_mysql_handle_errors(dberr_t*, trx_t*, que_thr_t*, trx_savept_t*) ()
5) 释放锁
innodb的行锁在事务提交或回滚后才释放。释放锁后,会检查是否有等待该锁的锁对象,若有,则将其释放,唤醒对应的线程。
a) 提取锁类型为LOCK_WAIT锁,判断是否需要继续等待。
b) 若不需要等待,则授权lock_grant
c) 根据锁对象找到找到对应的事务(lock_t->trx)信息,
d) 通过事务找到对应的工作线程(trx_lock_t->wait_thr)信息
e) 通过thr信息找到对应的slot(等待事件)
f) 调用os_event_set触发事件
调用堆栈
#0 os_event_set(thr->slot->event);
#1 lock_wait_release_thread_if_suspended
#2 lock_grant
#3 lock_rec_dequeue_from_page
#4 lock_trx_release_locks
6) slot的管理
锁等待通过slot对象上的等待事件event实现(下文会讲),每个slot对象包含一个等待事件,slot个数与运行的线程相关。因为阻塞的主体是线程,因此只需要初始化与最大线程数目相同的slot节点即可。slot信息存储在lock_sys的waiting_threads中。需要slot时,从数组中获取。
slot初始化
lock_sys = static_cast(mem_zalloc(lock_sys_sz));
lock_stack = static_cast(
mem_zalloc(sizeof(*lock_stack) * LOCK_STACK_SIZE));
void* ptr = &lock_sys[1];
lock_sys->waiting_threads = static_cast(ptr);
3. innodb行锁开销
innodb行锁采用位图存储,理论上一个记录只需要一个bit位。锁的基本单位是行,但锁是通过事务和页来进行管理和组织,创建锁的实例是lock_t,一个lock_t实例对应于一个索引页面的所有记录。
1) 行锁代价计算
内存开销主要来源于指针和存储锁信息的bitmap。bitmap中的一个bit对应page的一条记录,一个200条记录的Page,一个行锁对象大小约为 100bytes。若页面只锁一行,代价为100byte/行,而如果所有记录公用一把锁,则代价为100byte/200=4bit/行。实际情况下,只有当同一个事务锁住了页面的所有记录,并且锁模式相同,才可能保证一个页面只有一把锁。
一个lock_t对象占用的内存空间
1 /* Make lock bitmap bigger by a safety margin */
2 n_bits = page_dir_get_n_heap(page) + LOCK_PAGE_BITMAP_MARGIN;
3 n_bytes = 1 + n_bits / 8;
4 lock = static_cast(
5 mem_heap_alloc(trx->lock.lock_heap, sizeof(lock_t) + n_bytes));
2) 锁重用
innodb锁机制利用锁重用方式,保证锁的内存开销尽可能小。具体而言,同一个事务锁住同一个页面的记录,并且锁模式相同; 同一个事务,对于同一条记录,已有的锁强于请求的锁模式,这两种情况下都不需要重新创建锁对象。
4. Innodb锁同步机制(spinlock+mutex+条件变量)
innodb没有直接采用原生的同步方式比如spinlock,mutex或是条件变量实现,而是将几种方式进行融合,达到最优的目的。主要函数的实现在于mutex_enter_func和mutex_exit两个函数。
1) 数据结构
ib_mutex_t
{
os_event_t event; //等待事件
volatile lock_word_t lock_word; //锁变量
os_fast_mutex_t os_fast_mutex; //不支持原子锁系统,使用互斥量
ulint waiters; //是否有等待线程
}
2) 获取互斥量流程【mutex_enter_func(ib-mutex)】
a) 首先进行自旋,检查mutex->lock_word,判断是否可以获得该锁
b) 对于不支持spinlock的系统,采用pthread_mutex_trylock方式,利用os_fast_mutex保护mutex->lock_word,判断是否可以获得该锁
c) 若不能获得,则从全局变量 sync_wait_array分配一个cell,并将cell的wait_object设置为ib-mutex
d) 将ib-mutex的waiters设为1
e) 调用os_event_wait_low(ib-mutex->event),将线程挂起
f) 获得信号量后,线程跳转步骤a)重新开始执行。
3) 释放互斥量流程【mutex_exit_func(ib-mutex)】
a) 重置mutex->lock_word,
b) 对于自旋锁,通过os_atomic_test_and_set_byte设置
c) 对于不支持自旋锁的系统,释放os_fast_mutex,将lock_word设置为0
d) 判断ib-mutex对象waiters是否为1(是否有线程挂起)
e) 调用mutex_signal_object(ib-mutex->event)
f) 调用pthread_cond_broadcast(event->cond)唤醒所有等待的线程
5. innodb等待事件实现
1) event的结构
os_event
{
os_cond_t cond_var; //条件变量
ibool is_set; //为ture时,线程不会阻塞在事件上
os_fast_mutex_t os_mutex; //保护条件变量的互斥量
}
2) os_event_set 流程
a) 获取互斥量os_mutex
b) 若is_set为true,什么也不做,释放os_mutex
c) 若is_set为false,设置is_set为true
d) 调用pthread_cond_broadcast广播条件变量,唤醒所有等待线程
3) os_event_wait 流程
a) 获取互斥量os_mutex
b) 判断is_set为true,则什么也不做,释放os_mutex
c) 若is_set为false,调用pthread_cond_wait,将自己挂起等待
d) 被唤醒后,释放互斥量os_mutex
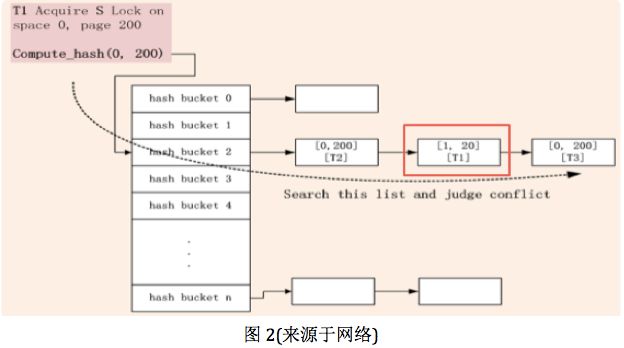
回到文章开始提到的问题,假设表t,id=1的记录所在的页面为(1,20),如图2所示,则锁节点可以红色的框表示,一个节点表示一个锁对象。另外,事务T2和T3已经在页面(0,200)上了2把锁,这里解释下,为啥同一个页面有2把锁。这是因为,锁对象的拥有者不同。不同事务即使是对同一条记录上同样模式的锁,也需要分别创建一个锁对象,所谓的锁重用是针对同一个事务锁同一个页面的多个记录而言。若T1也需要对(0,200)上锁,若上锁的记录与已有锁冲突,则创建锁,并挂起等待;否则,创建锁,返回成功。