Coursera | Andrew Ng (02-week-3-3.5)—将 Batch Norm 拟合进神经网络
该系列仅在原课程基础上部分知识点添加个人学习笔记,或相关推导补充等。如有错误,还请批评指教。在学习了 Andrew Ng 课程的基础上,为了更方便的查阅复习,将其整理成文字。因本人一直在学习英语,所以该系列以英文为主,同时也建议读者以英文为主,中文辅助,以便后期进阶时,为学习相关领域的学术论文做铺垫。- ZJ
Coursera 课程 |deeplearning.ai |网易云课堂
转载请注明作者和出处:ZJ 微信公众号-「SelfImprovementLab」
知乎:https://zhuanlan.zhihu.com/c_147249273
CSDN:http://blog.csdn.net/junjun_zhao/article/details/79122303
3.5 Fitting Batch Norm into a neural network 将 Batch Norm 拟合进神经网络
(字幕来源:网易云课堂)

So you have seen the equations for how to implement Batch Norm for maybe a single hidden layer.Let’s see how it fits into the training of a deep network.So, let’s say you have a neural network like this,you’ve seen me say before that you can view each of the unit as computing two things.First, it computes z z and then it applies the activation function to compute a a .And so we can think of each of these circles as representing a two step computation.And similarly for the next layer,that is z2 1, and a2 1, and so on.
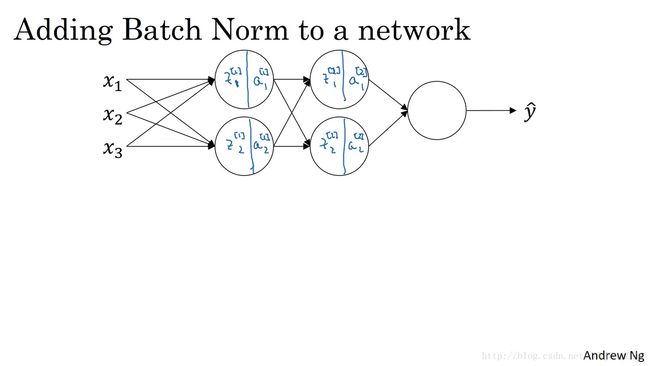
你已经看到那些等式,它可以在单一隐藏层上进行 Batch 归一化,接下来 让我们看看它是怎样在深度网络训练中拟合的吧,假设你有一个这样的神经网络,我之前说过,你可以认为每个单元负责计算两件事,第一 它先计算 z z ,然后应用其到激活函数中在计算 a a ,所以我们可以认为,每个圆圈代表着两步的计算过程,同样的对于下一层而言,那就是 z[2]1 z 1 [ 2 ] 和 a[2]1 a 1 [ 2 ] 等。
So, if you were not applying Batch Norm,you would have an input X fit into the first hidden layer,and then first compute z1,and this is governed by the parameters z1 and b1.And then ordinarily, you would fit z1 into the activation function to compute a1.But what would do in Batch Norm is take this value z1,and apply Batch Norm,sometimes abbreviated BN to it,and that’s going to be governed by parameters,Beta 1 and Gamma 1,and this will give you this new normalized value z1.And then you fit that to the activation function to get a1,which is G1 applied to z tilde 1.Now, you’ve done the computation for the first layer,where this Batch Norms that really occurs in between the computation from z and a.Next, you take this value a1 and use it to compute z2,and so this is now governed by w2, b2.And similar to what you did for the first layer,you would take z2 and apply it through Batch Norm, and we abbreviate it to BN now.This is governed by Batch Norm parameters specific to the next layer.So Beta 2, Gamma 2,and now this gives you z tilde 2,and you use that to compute a2 by applying the activation function, and so on.So once again, the Batch Norms that happens between computing z and computing a.And the intuition is that,instead of using the un-normalized value z,you can use the normalized value z tilde, that’s the first layer.The second layer as well,instead of using the un-normalized value z2,you can use the mean and variance normalized values Z tilde 2.
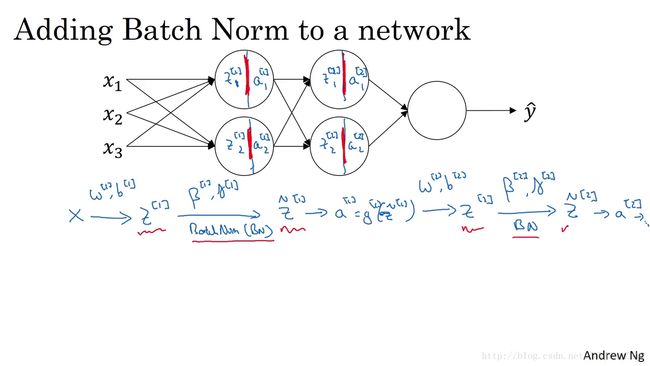
所以 如果你没有应用 Batch 归一化,你会把拟合到第一隐藏层,然后首先计算 z[1] z [ 1 ] ,这是由 w[1] w [ 1 ] 和 b[1] b [ 1 ] 两个参数控制得,接着 通常而言 你会把 z[1] z [ 1 ] 拟合到激活函数以计算 a[1] a [ 1 ] ,但 Batch 归一化的做法是将 z[1] z [ 1 ] 值,进行 Batch 归一化,简称 BN,此过程将由, β[1] β [ 1 ] 和 γ[1] γ [ 1 ] 两参数控制,这一步操作会给你一个新的规范化的 z[1] z [ 1 ] 值,然后将其输入激活函数中 得到 a[1] a [ 1 ] ,即 g[1](z̃ [1]) g [ 1 ] ( z ̃ [ 1 ] ) ,现在 你已在第一层进行了计算,此时 这项 Batch 归一化发生在 z z 的计算和 a a 之间,接下来 你需要应用 a[1] a [ 1 ] 值来计算 z[2] z [ 2 ] ,此过程是由 w[1] w [ 1 ] 和 b[1] b [ 1 ] 控制的,与你在第一层所做的类似,你会将 z[2] z [ 2 ] 进行 Batch 归一化 我们现在简称 BN,这是由下一层的 Batch 归一化参数所管控的的,即 β[2] β [ 2 ] 和 γ[2] γ [ 2 ] ,现在 你得到 z̃ [2] z ̃ [ 2 ] ,再通过激活函数计算出 a[2] a [ 2 ] 等等,所以 需强调的是 Batch 归一化是发生在计算 z z 和 a a 之间的,直觉就是,与其应用没有归一化的 z z 值,不如用归一过的 z̃ z ̃ 这是第一层,第二层同理,与其应用没有规范过的 z[2] z [ 2 ] 值,不如用经方差和均值归一后的 z̃ [2] z ̃ [ 2 ] 。
So the parameters of your network are going to be w1, b1.It turns out we’ll get rid of the parameters But for now, imagine the parameters are the usual w1,b1……wl, bl,and we have added to this new network,additional parameters,Beta 1, Gamma 1, Beta 2, Gamma 2,and so on,for each layer in which you are applying Batch Norm.For clarity, note that these Betas here,these have nothing to do with the hyperparameter betabut we’ll see why in the next slide.that we had for momentum or for the computing the various exponentially weighted averages.You know,the authors of the Adam paper had used Beta in their paper to denote that hyperparameter,the authors of the Batch Norm paper had used Beta to denote this parameter,but these are two completely different Betas.I decided to stick with Beta on in both cases,in case you read the original papers.But the Beta 1,Beta 2, and so on,that Batch Norm tries to learn is a different Beta thanthe hyperparameter Beta used in momentum and the Adam and RMSprop algorithms.So now that these are the new parameters of your algorithm,you would then use whether optimization you want,such as creating descent in order to implement it.
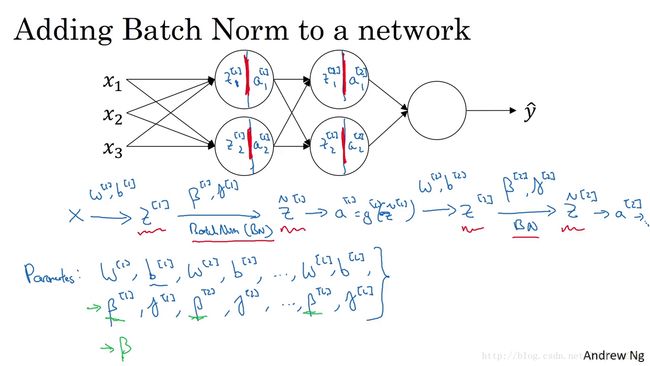
所以 你网络的参数就会是 w[1] w [ 1 ] b[1] b [ 1 ] ,我们将要去掉这些参数,但现在 想像参数是 w[1] w [ 1 ] b[l] b [ l ] 到 w[l] w [ l ] b[l] b [ l ] ,我们将另一些参数,加入到此新网络中, β[1] β [ 1 ] \beta^{[2]} γ[1] γ [ 1 ] γ[2] γ [ 2 ] 等等,对于应用 Batch 归一化的每一层而言,需要澄清的是 请注意 这里的这些 β β ,和超参数 β β 没有任何关系,下一张幻灯片中会解释原因,后者是用于 momentum ,或计算各个指数的加权平均值, Adam 论文的作者,在论文里用 β β 代表超参数, Batch 归一化论文的作者,则使用 β β 代表此参数,但这是两个完全不同的 β β ,我在两种情况下都决定使用 β β ,以便你阅读那些原创的论文,但 β[1] β [ 1 ] β[2] β [ 2 ] 等等, Batch 归一化试图去学习 β β 和,用于 momentum 、the Adam 、RMS prop 算法中的 β β 不同,所以现在 这是你算法的新参数,接下来你可以使用想用的任一种优化法。
So for example, you might compute d Beta l for a given layer,and then update the parameters Beta,gets updated as Beta minus learning rate times D Beta L.And you can also use Adam or RMS prop or momentum in order to update the parameters Beta and Gamma,not just creating descent.And even though in the previous video,I had explained what the Batch Norm operation does,computes mean and variances and subtracts and divides by them.If they are using a Deep Learning Programming Framework,usually you won’t have to implement the Batch Norm step on Batch Norm layer yourself.So the probing frameworks,can be sub one line of code.So for example, in the TensorFlow framework,you can implement Batch Normalization, you know, with this function.We’ll talk more about probing frameworks later,but in practice you might not end up needing to implement all these details yourself,but self-aware of knowing how it worksso that you can get a better understanding of what your code is doing.But implementing Batch Norm is often,you know,something like one line of code in the deep learning frameworks.Now, so far, we’ve talked about Batch Normas if you were training on your entire training site at the other timeas if you are using Batch gradient descent.
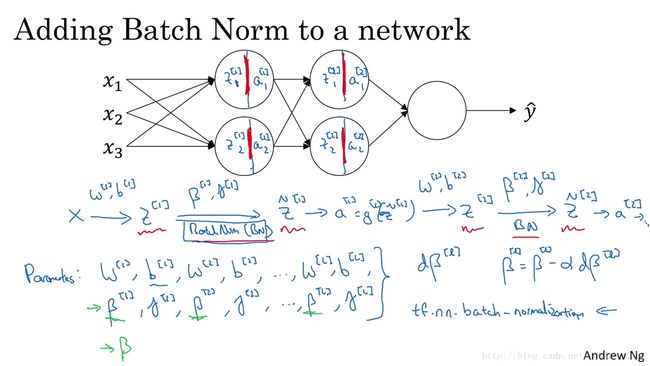
比如 创造下降来应用它,举个例子 对于给定层 你会计算 dβ[l] d β [ l ] ,接着 更新参数 β β 为 β[l] β [ l ] ,即为 β[l]−αdβ[l] β [ l ] − α d β [ l ] ,你也可以使用 Adam 或 RMS prop或 momentum ,以更新参数 β β 和 γ γ ,并不只用创造下降法,即使在之前的视频中,我已经解释过 Batch 归一化是怎么操作的,计算均值和方差 减去 再被它们除,如果它们使用的是深度学习编程框架,通常 你不必自己,把 Batch 归一化步骤应用于 Batch 归一化层,因此 探究框架,可写成一行代码,比如说 在 TensorFlow 框架中,你可以用这个函数来实现 Batch 归一化,我们会稍后讲解,但实践中 你不必自己操作所有这些具体的细节,但知道它是如何作用的,这样 你会更好的理解代码的作用,但在深度学习框架中 Batch 归一化的过程,经常是类似一行代码的东西,所以 到目前为止 我们已经讲了 Batch 归一化,就像你在整个训练站点上训练一样,或就像你正在使用 Batch 梯度下降。
In practice, Batch Norm is usually applied with mini-batch es of your training set.So the way you actually apply Batch Norm isyou take your first mini-batch and compute z1.Same as we did on the previous slide using the parameters w1,b1and then you take just this mini-batch andcompute mean and variance of the Z1 on just this mini batchand then goes to the second mini-batch x2,and then Batch Norm would subtract by the mean and divide by the standard deviation and then re-scale by Beta 1, Gamma 1, to give you z1,and all this is on the first mini-batch ,then you apply the activation function to get A1,and then you compute z2 using w2,b2, and so on.So you do all this in order to compute one step gradient descent on the first mini-batch and you do something similar where you will now compute z1 on the second mini-batch and then use Batch Norm to compute z1 tilde.And so here in this Batch Norm step,You would be normalizing z tilde using just the data in your second mini-batch ,so does Batch Norm step here.Let’s look at the examples in your second mini-batch ,computing the mean and variances of the z1’s on just that mini-batch andre-scaling by Beta and Gamma to get z tilde, and so on.And you do this with a third mini-batch , and keep training.

实践中, Batch 归一化通常和训练集的 mini-batch 一起使用,你应用 Batch 归一化的方式就是,你用第一个 mini-batch 然后计算 z[1] z [ 1 ] ,这和上张幻灯片上我们所做的一样 应用参数 w[1] w [ 1 ] b[1] b [ 1 ] ,使用这个 mini-batch ,在其上计算 z[1] z [ 1 ] 的均值和方差,接着 继续第二个 mini-batch x{2} x { 2 } ,接着 Batch 归一化会减去均值 除以标准差,由 β[1] β [ 1 ] γ[1] γ [ 1 ] 重新缩放 这样就得到了 z[1] z [ 1 ] ,而所有的这些都是在第一个 mini-batch 的基础上,你再应用激活函数得到 a[1] a [ 1 ] ,然后用 w[2] w [ 2 ] b[2] b [ 2 ] 计算 z[2] z [ 2 ] 等等,所以你做的这一切都是为了,在第一个 mini-batch 上进行一步梯度下降法,做类似的工作,你会在第二个 mini-batch 上计算 z[1] z [ 1 ] ,然后用 Batch 归一化来计算 z˜[1] z ~ [ 1 ] ,所以在 Batch 归一化的此步中,你用第二个 mini-batch 中的数据使z̃归一化,这里的 Batch 归一化步骤也是如此,让我们来看看在第二个 mini-batch 中的例子,在 mini-batch 上计算 z[1] z [ 1 ] 的均值和方差,重新缩放的 β β 和 γ γ 得到z̃等等,然后在第三个 mini-batch 上同样这样做 继续训练。
Now, there’s one detail to the parameterization that I want to clean up,which is previously, I said that the parameters was wl, bl,for each layer as well as Beta l, and Gamma l.Now notice that the way Z was computed is as follows,zl= wl x a of l - 1 + b of l. But what Batch Norm does,is it is going to look at the mini-batch and normalize zl to first of mean 0 and standard variance,and then a rescale by Beta and Gamma.But what that means is that,whatever is the value of bl is actually going to just get subtracted out,because during that Batch Normalization step,you are going to compute the means of the zl’s and subtract the mean.And so adding any constant to all of the examples in the mini-batch ,it doesn’t change anything.Because any constant you add will get cancelled out by the mean subtractions step.So, if you’re using Batch Norm,you can actually that parameter,or if you want, think of it as setting it permanently to 0.So then the parameterization becomes zl is just wl x al - 1,And then you compute zl normalized,and we compute z tilde = Gamma zl+ Beta,you end up using this parameter Beta Lin order to decide what’s the mean of z tilde l.Which is why guess post in this layer.So just to recap,because Batch Norm zeroes out the mean of these zl values in the layer,there’s no point having this parameter bl,and so you must get rid of it,and instead is sort of replaced by Beta l,which is a parameter that controls that ends up affecting the shift or the biased terms.

现在 我想澄清此参数化的一个细节,先前 我说过每层的参数是 w[l] w [ l ] b[1] b [ 1 ] ,还有 β[l] β [ l ] 和 γ[l] γ [ l ] ,请注意计算 z z 的方式如下, z[l]=w[l]a[l−1]+b[l] z [ l ] = w [ l ] a [ l − 1 ] + b [ l ] 但 Batch 归一化做的是,它要看这个 mini-batch ,先将 z[l] z [ l ] 归一化 结果为均值 0 和标准方差,再由 β β 和 γ γ 重缩放,但这意味着,无论 b[l] b [ l ] 的值是多少 都是要被减去的,因为在 Batch 归一化的过程中,你要计算 z[l] z [ l ] 的均值 再减去平均值,在此例的 mini-batch 中增加任何常数,数值都不会改变,因为加上的任何常数都将会被均值减法所抵消,所以 如果你在使用 Batch 归一化,其实你可以消除这个参数,或者你也可以暂时把它设置为 0,那么参数化变成 z[l]=w[l]a[l−1] z [ l ] = w [ l ] a [ l − 1 ] ,然后你计算归一化的 z[l] z [ l ] , z̃ =γ[l]z[l]+β[l] z ̃ = γ [ l ] z [ l ] + β [ l ] ,你最后会用参数 β[l] β [ l ] ,以便决定 z̃ [l] z ̃ [ l ] 的取值,这就是原因,所以 总结一下,因为 Batch 归一化 0 超过了此层 z[l] z [ l ] 的均值, b[l] b [ l ] 这个参数没有意义,所以你必须去掉它,由 β[l] β [ l ] 替代,这是个控制参数会影响转移或偏置条件。
Finally, remember that the dimension of zl,because if you’re doing this on one example,it’s going to be nl by 1,and so bl had a dimension, nl by one,if nl was the number of hidden units in layer l.And so the dimension of Beta l and Gamma l is also going to be nl by 1 because that’s the number of hidden units you have.You have nl hidden units, and so Beta l and Gamma l are used to scale the mean and variance of each of the hidden units to whatever the network wants to set them to.

最后 请记住 z[l] z [ l ] 的维数,因为在这个例子中,维数会是 (n[l]1) ( n [ l ] 1 ) , b[l] b [ l ] 的尺寸 (n[l]1) ( n [ l ] 1 ) ,如果 是 l l 层隐藏单元的数量,那 β[l] β [ l ] 和 γ[l] γ [ l ] 的维度,也是 (n[l]1) ( n [ l ] 1 ) 因为这是你有的隐藏层的数量,你有 n[l] n [ l ] 隐藏单元 所以 β[l] β [ l ] 和 γ[l] γ [ l ] 用来,将每个隐藏层的均值和方差缩放为网络想要的值。
So, let’s pull all together and describe how you can implement gradient descent using Batch Norm.Assuming you’re using mini-batch gradient descent,it runs for t = 1 to the number of many batches.You would implement forward prop on mini-batch x t and doing forward prop in each hidden layer,use Batch Norm to replace zl with z tilde l.And so then it ensures that within that mini-batch ,the value z end up with some normalized mean and variance and the values and the version of the normalized mean and variance is this z tilde l.And then, you use back prop to compute dw,db,for all the values of l,d Beta, d Gamma.Although, technically, since you have got to get rid of b,this actually now goes away.And then finally, you update the parameters.So, w gets updated as w minus the learning rate times dw, as usual,Beta gets updated as Beta minus learning rate times d\beta,and similarly for Gamma.And if you have computed the gradient as follows,you could use gradient descent.That’s what I’ve written down here,but this also works with gradient descent with momentum ,or RMSprop, or Adam .Where instead of taking this gradient descent update mini-batch you could use the updates given by these other algorithmsas we discussed in the previous week’s videos.Some of these other optimization algorithms as well can be usedto update the parameters Beta and Gamma that Batch Norm added to algorithm.

让我们总结一下,关于如何用 Batch 归一化来应用梯度下降法,假设你在使用 mini-batch 梯度下降法,你运行同 t t 等于 1 到 batch 数量的 for 循环,你会应用正向 prop 于 mini-batch x{num} x { n u m } ,每个隐藏层都应用正向 prop,用 Batch 归一化替代 z[l] z [ l ] 为 z̃ [l] z ̃ [ l ] ,接下来 它确保在这个 mini-batch 中, z z 值有归一化的均值和方差,归一化均值和方差是 z̃ [l] z ̃ [ l ] ,然后 你用反向 prop 计算 dw[l] d w [ l ] db[l] d b [ l ] ,及 l l 的所有值 dβ[l] d β [ l ] dγ[l] d γ [ l ] ,尽管 严格来说 因为你要去掉 b ,这部分其实已经去掉了,最后 你更新这些参数, w[l]=w[l]−αdw[l] w [ l ] = w [ l ] − α d w [ l ] 和以前一样, β[l]=β[l]−αdβ[l] β [ l ] = β [ l ] − α d β [ l ] ,对于 γ γ 也是如此,如果你已将梯度计算如下,你就可以使用梯度下降法了,这就是我写到这里的,但这也适用于有 momentum 、 RMSprop 、 Adam 的梯度下降法,与其使用梯度下降法更新 mini-batch ,你可以用这些其它的算法来更新,我们在之前几星期视频中讨论过的,也可以应用其它的一些优化算法,来更新由 Batch 归一化添加到算法中的 β β 和 γ γ 参数。
So, I hope that gives you a sense ofhow you could implement Batch Norm from scratch if you wanted to.If you’re using one of the Deep Learning Programming frameworkswhich we will talk more about later,hopefully you can just call someone else’s implementation inthe Programming framework which will make using Batch Norm much easier.Now, in case Batch Norm still seems a little bit mysteriousif you’re still not quite sure why it speeds up training so dramatically,let’s go to the next video and talk more aboutwhy Batch Norm really works and what it is really doing.
我希望 你能学会如何从头开始应用 Batch 归一化 。如果你想的话,如果你使用深度学习编程框架之一,我们之后会谈到,希望 你可以直接叫别人应用于,编程框架 这会使 Batch 归一化的使用变得很容易,现在 以防 Batch 归一化仍然看起来有些神秘,尤其是你还不清楚为什么其能如此显著的加速训练,我们下一个视频中 会谈到, Batch 归一化为何效果如此显著 它到底在做什么。
重点总结:
在神经网络中融入Batch Norm
在深度神经网络中应用 Batch Norm,这里以一个简单的神经网络为例,前向传播的计算流程如下图所示:
实现梯度下降
- for t = 1 … num (这里 num 为 Mini Batch 的数量):
- 在每一个 Xt X t 上进行前向传播(forward prop)的计算:
- 在每个隐藏层都用 Batch Norm 将 z[l] z [ l ] 替换为 z˜[l] z ~ [ l ]
使用反向传播(Back prop)计算各个参数的梯度: dw[l]、dγ[l]、dβ[l] d w [ l ] 、 d γ [ l ] 、 d β [ l ]
- 更新参数:
- w[l]:=w[l]−αdw[l] w [ l ] := w [ l ] − α d w [ l ]
- γ[l]:=γ[l]−αdγ[l] γ [ l ] := γ [ l ] − α d γ [ l ]
- β[l]:=β[l]−αdβ[l] β [ l ] := β [ l ] − α d β [ l ]
- 更新参数:
同样与 Mini-batch 梯度下降法相同,Batch Norm 同样适用于 momentum、RMSprop、Adam 的梯度下降法来进行参数更新。
这里没有写出偏置参数 b[l] b [ l ] 是因为 z[l]=w[l]a[l−1]+b[l] z [ l ] = w [ l ] a [ l − 1 ] + b [ l ] ,而 Batch Norm 要做的就是将 z[l] z [ l ] 归一化,结果成为均值为 0,标准差为 1 的分布,再由 β β 和 γ γ 进行重新的分布缩放,那就是意味着,无论 b[l] b [ l ] 值为多少,在这个过程中都会被减去,不会再起作用。所以如果在神经网络中应用 Batch Norm 的话,就直接将偏置参数 b[l] b [ l ] 去掉,或者将其置零。
参考文献:
[1]. 大树先生.吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(2-3)– 超参数调试 和 Batch Norm
PS: 欢迎扫码关注公众号:「SelfImprovementLab」!专注「深度学习」,「机器学习」,「人工智能」。以及 「早起」,「阅读」,「运动」,「英语 」「其他」不定期建群 打卡互助活动。
