innodb是一个多线程并发的存储引擎,内部的读写都是用多线程来实现的,所以innodb内部实现了一个比較高效的并发同步机制。
innodb并没有直接使用系统提供的锁(latch)同步结构,而是对其进行自己的封装和实现优化。可是也兼容系统的锁。我们先看一段innodb内部的凝视(MySQL-3.23):
Semaphore operations in operating systems are slow: Solaris on a 1993 Sparc takes 3 microseconds (us) for a lock-unlock pair and Windows NT on a 1995 Pentium takes 20 microseconds for a lock-unlock pair. Therefore, we have toimplement our own efficient spin lock mutex. Future operating systems mayprovide efficient spin locks, but we cannot count on that.
大概意思是说1995年的时候。一个Windows NT的 lock-unlock所须要耗费20us,即使是在Solaris 下也须要3us,这也就是他为什么要实现自己定义latch的目的,在innodb中作者实现了系统latch的封装、自己定义mutex和自己定义rw_lock。以下我们来一一做分析。
1 系统的mutex和event
定义例如以下:
typedef pthread_mutex os_fast_mutex_t;typedef struct os_event_struct
{
os_fast_mutex_t os_mutex;
ibool is_set;
pthread_cond_t cond_var;
}os_event_t;
2 CPU原子操作
在
asm volatile("movl $1, %%eax; xchgl (%%ecx), %%eax" :
"=eax" (res), "=m" (*lw) :
"ecx" (lw));事实上就是将lw的值设置成1,而且返回设置lw之前的值(res),这个过程都是CPU须要回写内存的,也就是CPU和内存是全然一致的。
除了上面设置1以外。另一个复位的实现,例如以下:
asm volatile("movl $0, %%eax; xchgl (%%ecx), %%eax" :
"=m" (*lw) : "ecx" (lw) : "eax"); #define LOCK() while(__sync_lock_test_and_set(&lock, 1)){}
#define UNLOCK() __sync_lock_release(&lock)3 mutex的实现
struct mutex_struct
{
ulint lock_word; /*mutex原子控制变量*/
os_fast_mutex_t os_fast_mutex; /*在编译器或者系统部支持原子操作的时候採用的系统os_mutex来替代mutex*/
ulint waiters; /*是否有线程在等待锁*/
UT_LIST_NODE_T(mutex_t) list; /*mutex list node*/
os_thread_id_t thread_id; /*获得mutex的线程ID*/
char* file_name; /*mutex lock操作的文件/
ulint line; /*mutex lock操作的文件的行数*/
ulint level; /*锁层ID*/
char* cfile_name; /*mute创建的文件*/
ulint cline; /*mutex创建的文件行数*/
ulint magic_n; /*魔法字*/
};mutex_enter_func 获得mutex锁,假设mutex被其它线程占用。先会自旋SYNC_SPIN_ROUNDS,然后
mutex_exit 释放mutex锁。并向等待线程发送能够抢占mutex的信号量
3.1 mutex_enter_func流程图:

3.2 mutex_exit流程图

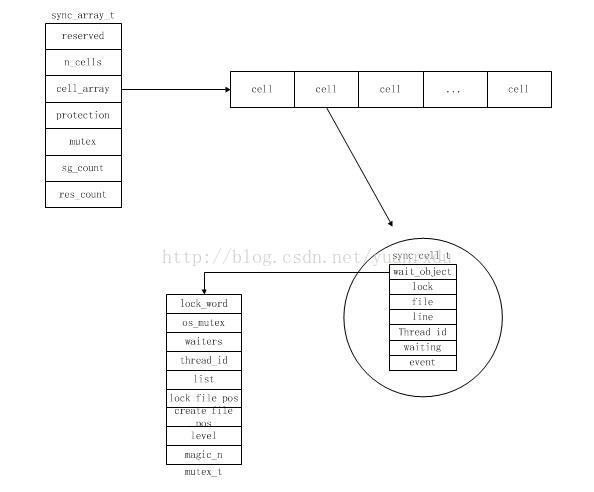
3.4 mutex_t的内存结构关系图

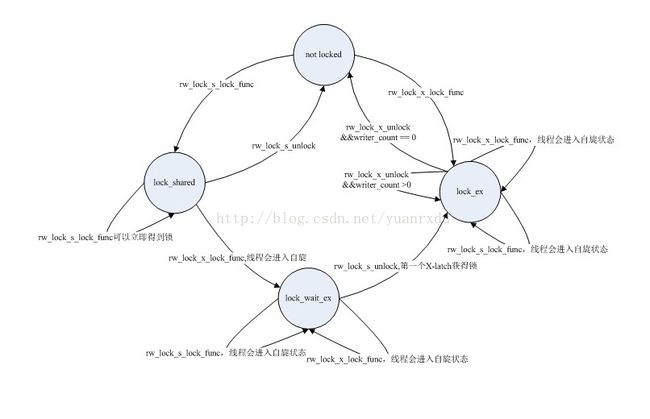
4 rw_lock的实现
1、同一时刻同意多个线程同一时候读取内存中的变量
2、同一时刻仅仅同意一个线程更改内存中的变量
3、同一时刻当有线程在读取变量时不同意不论什么线程写存在
4、同一时刻当有线程在更改变量时不同意不论什么线程读,也不同意出自己以外的线程写(线程内能够递归占有锁)。
5、当有rw_lock处于线程读模式下是有线程写等待,这时候假设再有其它线程读请求锁的时。这个读请求将处于等待前面写完毕。
| S-latch | X-latch | |
| S-latch | 兼容 | 不兼容 |
| X-latch | 不兼容 | 不兼容 |
struct rw_lock_struct
{
ulint reader_count; /*获得S-LATCH的读者个数,一旦不为0,表示是S-LATCH锁*/
ulint writer; /*获得X-LATCH的状态。主要有RW_LOCK_EX、RW_LOCK_WAIT_EX、
RW_LOCK_NOT_LOCKED, 处于RW_LOCK_EX表示是一个x-latch
锁,RW_LOCK_WAIT_EX的状态表示是一个S-LATCH锁*/
os_thread_id_t writer_thread; /*获得X-LATCH的线程ID或者第一个等待成为x-latch的线程ID*/
ulint writer_count; /*同一线程中X-latch lock次数*/
mutex_t mutex; /*保护rw_lock结构中数据的相互排斥量*/
ulint pass; /*默觉得0,假设是非0,表示线程能够将latch控制权转移给其它线程,
在insert buffer有相关的调用*/
ulint waiters; /*有读或者写在等待获得latch*/
ibool writer_is_wait_ex;
UT_LIST_NODE_T(rw_lock_t) list;
UT_LIST_BASE_NODE_T(rw_lock_debug_t) debug_list;
ulint level; /*level标示。用于检測死锁*/
/*用于调试的信息*/
char* cfile_name; /*rw_lock创建时的文件*/
ulint cline; /*rw_lock创建是的文件行位置*/
char* last_s_file_name; /*最后获得S-latch时的文件*/
char* last_x_file_name; /*最后获得X-latch时的文件*/
ulint last_s_line; /*最后获得S-latch时的文件行位置*/
ulint last_x_line; /*最后获得X-latch时的文件行位置*/
ulint magic_n; /*魔法字*/
};RW_LOCK_NOT_LOCKED 空暇状态
RW_LOCK_SHARED 处于多线程并发都状态
RW_LOCK_WAIT_EX 等待从S-latch成为X-latch状态
RW_LOCK_EX 处于单线程写状态
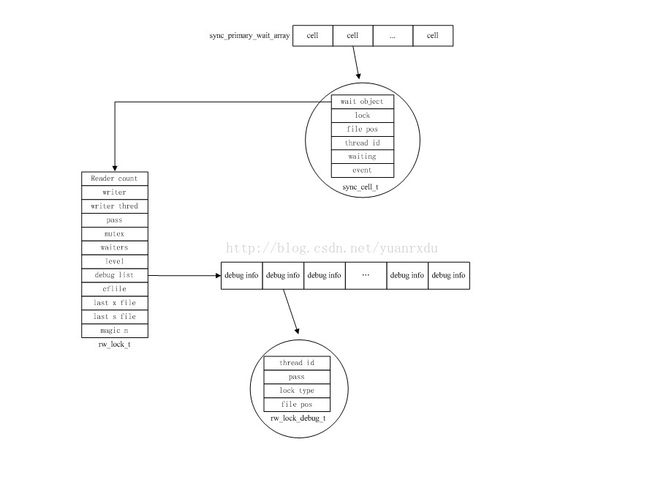
5 死锁检測与调试
与死锁检測相关的模块主要是mutex level、rw_lock level和sync_cell。latch level相关的定义:
/*sync_thread_t*/
struct sync_thread_struct
{
os_thread_id_t id; /*占用latch的thread的id*/
sync_level_t* levels; /*latch的信息,sync_level_t结构内容*/
};
/*sync_level_t*/
struct sync_level_struct
{
void* latch; /*latch句柄,是mute_t或者rw_lock_t的结构指针*/
ulint level; /*latch的level标识ID*/
};在latch获得的时候,innodb会调用mutex_set_debug_info函数向sync_thread_t中增加一个latch被获得的状态信息。事实上就是包含获得latch的线程id、获得latch的文件位置和latch的层标识(详细的细节能够查看mutex_enter_func和mutex_spin_wait)。仅仅有占用了latch才会体如今sync_thread_t中,假设仅仅是在等待获得latch是不会增加到sync_thread_t其中的。innodb能够通过sync_thread_levels_empty_gen函数来输出全部latch等待依赖的cell_t序列。追踪线程等待的位置。
5.1sync_thread_t与sync_level_t的内存结构关系:

levels的长度是SYNC_THREAD_N_LEVELS(10000)。
5.2死锁与死锁检測
线程A 线程B
mutex1 enter mutex2 enter
mutex2 enter mutex1 enter
运行任务 运行任务
mutex2 release mutex1 release
mutex1 release mutex2 release
上面两个线程同一时候执行的时候。可能产生死锁的情况。就是A线程获得了mutex1正在等待mutex2的锁。同一时候线程2获得了mutex2正在等待mutex1的锁。在这样的情况下,线程1在等线程2,线程2在等线程就造成了死锁。
1、将进入等待的latch相应的cell作为參数传入到sync_array_detect_deadlock其中,其中start的參数和依赖的cell參
2、进入sync_array_detect_deadlock先推断依赖的cell是否正在等待latch,假设没有,表示没有死锁。直接返回.
假设没有。继续将查询到的cell作为參数递归调用
这是个两函数交叉递归推断的过程。
由于关系数据库的latch使用很频繁和复杂。检查死锁对于锁的调试是很有效的,尤其是配合thread_levels状态信息输出来做调试,对死锁排查是很有意义的。

6.总结
我个人理解主要是降低操作系统上下文的切换,提高并发的效率。innodb中实现的自己定义latch仅仅适合短时间的锁等待(最好不超过50us),假设是长时间锁等待,不妨使用操作系统提供的。尽管自己定义锁在等待一个自旋周期会进入操作系统的event_wait,但这无疑比系统的mutex lock耗费的资源多。最后我们还是看作者在代码中的总结: