《高性能MySQL》读书笔记--锁、事务、隔离级别
1.锁
1.1锁的分类
从对数据操作的类型(读\写)分
读锁(共享锁):针对同一块数据,多个读操作可以同时进行而不会互相影响。
写锁(排他锁):当前写操作没有完成前,它会阻断其他写锁和读锁。
大多数时候,MySQL锁的内部管理都是透明的。
1.2锁粒度(Lock granularity)
表锁:管理锁的开销最小,同时允许的并发量也最小的锁机制。MyIsam存储引擎使用的锁机制。当要写入数据时,把整个表都锁上,此时其他读、写动作一律等待。在MySql中,除了MyIsam存储引擎使用这种锁策略外,MySql本身也使用表锁来执行某些特定动作,比如alter table.
另外,写锁比读锁有更高的优先级,因此一个写锁可能会被插入到读锁队列的前面。
行锁:可以支持最大并发的锁策略(同时也带来了最大的锁开销)。InnoDB和Falcon两张存储引擎都采用这种策略。行级锁只在存储引擎层实现,而MySQL服务器层没有实现。服务器层完全不了解存储引擎中的锁实现。
MySql是一种开放的架构,你可以实现自己的存储引擎,并实现自己的锁粒度策略,不像Oracle,你没有机会改变锁策略,Oracle采用的是行锁。
1.3死锁(Dead Lock)
2.事务(Transaction)
2.1事务ACID原则
从业务角度出发,对数据库的一组操作要求保持4个特征:Atomicity(原子性):一个事务必须被视为一个不可分割的最小工作单元,整个事务中的所有操作要么全部提交成功,要么全部失败回滚,对于一个事务来说,不可能只执行其中的一部分操作,这就是事务的原子性。
Consistency(一致性):数据库总是从一个一致性状态转换到另一个一致状态。下面的银行列子会说到。
Isolation(隔离性):通常来说,一个事务所做的修改在最终提交以前,对其他事务是不可见的。注意这里的“通常来说”,后面的事务隔离级级别会说到。
Durability(持久性):一旦事务提交,则其所做的修改就会永久保存到数据库中。此时即使系统崩溃,修改的数据也不会丢失。(持久性的安全性与刷新日志级别也存在一定关系,不同的级别对应不同的数据安全级别。)
为了更好地理解ACID,以银行账户转账为例:
1 START TRANSACTION;
2 SELECT balance FROM checking WHERE customer_id = 10233276;
3 UPDATE checking SET balance = balance - 200.00 WHERE customer_id = 10233276;
4 UPDATE savings SET balance = balance + 200.00 WHERE customer_id = 10233276;
5 COMMIT;
原子性:要么完全提交(10233276的checking余额减少200,savings 的余额增加200),要么完全回滚(两个表的余额都不发生变化)
一致性:这个例子的一致性体现在 200元不会因为数据库系统运行到第3行之后,第4行之前时崩溃而不翼而飞,因为事物还没有提交。
隔离性:允许在一个事务中的操作语句会与其他事务的语句隔离开,比如事务A运行到第3行之后,第4行之前,此时事务B去查询checking余额时,它仍然能够看到在事务A中被减去的200元(账户钱不变),因为事务A和B是彼此隔离的。在事务A提交之前,事务B观察不到数据的改变。
持久性:这个很好理解。
事务跟锁一样都会需要大量工作,因此你可以根据你自己的需要来决定是否需要事务支持,从而选择不同的存储引擎。
2.2隔离级别(Isolation Level)
SQL标准定义了4类隔离级别,包括了一些具体规则,用来限定事务内外的哪些改变是可见的,哪些是不可见的。低级别的隔离级一般支持更高的并发处理,并拥有更低的系统开销。
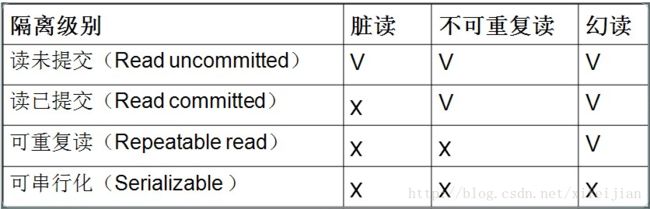
Read Uncommitted(未提交读)
在该隔离级别,所有事务都可以看到其他未提交事务的执行结果。本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少。读取未提交的数据,也被称之为脏读(Dirty Read)。
Read Committed(提交读)
这是大多数数据库系统的默认隔离级别(但不是MySQL默认的)。它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变。这种隔离级别 也支持所谓的不可重复读(Nonrepeatable Read),因为同一事务的其他实例在该实例处理其间可能会有新的commit,所以同一select可能返回不同结果。
Repeatable Read(可重复读)
这是MySQL的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。不过理论上,这会导致另一个棘手的问题:幻读 (Phantom Read)。简单的说,幻读指当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行。InnoDB和Falcon存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)机制解决了该问题。
这里有介绍MVCC策略:http://blog.csdn.net/xifeijian/article/details/45230053
Serializable(可串行化)
这是最高的隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。在这个级别,可能导致大量的超时现象和锁竞争。
这四种隔离级别采取不同的锁类型来实现,若读取的是同一个数据的话,就容易发生问题。例如:
脏读(Drity Read):某个事务已更新一份数据,另一个事务在此时读取了同一份数据,由于某些原因,前一个RollBack了操作,则后一个事务所读取的数据就会是不正确的。
不可重复读(Non-repeatable read):在一个事务的两次查询之中数据不一致,这可能是两次查询过程中间插入了一个事务更新的原有的数据。
幻读(Phantom Read):在一个事务的两次查询中数据笔数不一致,例如有一个事务查询了几列(Row)数据,而另一个事务却在此时插入了新的几列数据,先前的事务在接下来的查询中,就会发现有几列数据是它先前所没有的。
在MySQL中,实现了这四种隔离级别,分别有可能产生问题如下所示:
MySQL重点:《高性能MySQL》读书笔记--索引:http://blog.csdn.net/xifeijian/article/details/20312557