2018 Iterative Visual Reasoning Beyond Convolutions 论文梳理
18年是GNN开始初出茅庐也是大放异彩的一年, 这篇论文是李飞飞团队的关于GNN在CV领域中的一个开拓性的应用.甚至作者陈鑫磊称, 通过结合CNN和GNN, 本文发明了"下一代的视觉识别系统". 这个观点是不是很让人瑟瑟发抖? 好了, 下面开始分析论文结构和代码组成.
0. 论文简述
近年来, 由于卷积神经网络的大放异彩, 我们在如图像分类, 图像分割等经典的CV任务中取得了很大的进展. 但是, 我们人类的视觉推理行为中, 空间信息(spatial)和语义信息(semantic)对于识别效果非常关键. 而现有的视觉系统缺乏上下文推理(context reasoning), 即现有方案只是用卷积和大感受野来完成经典的CV任务.
本文正是为了解决这个局限, 提出了"吸收了空间信息和语义信息的下一代迭代视觉推理系统".
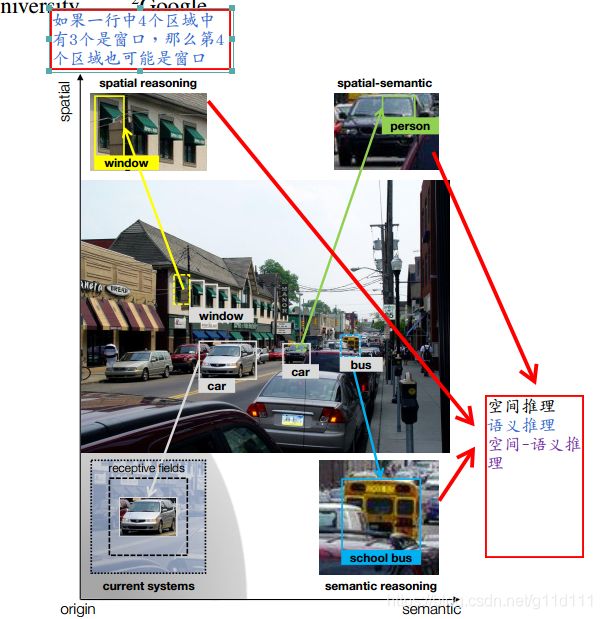
作者通过下图举例, 在实际的复杂场景情况中, 如果一个物体很小, 或者目标很模糊, 或者这个物体被遮住一部分, 那么我们在做目标检测时, 我们现在的算法会忽略这些目标. 但是人类可以通过周边的事物以及物体的大致形状推断出这个目标的类型.
左上角的窗户, 如果一排有3个都是窗户, 则第4个也有很大的概率也为窗户(spatial reasoning); 右下角的公交车, 虽然被遮挡, 但是可以通过周边的object来推断出其是一个公交车(semantic reasoning).
因为网上有很多博客对本文进行通篇翻译了, 这里简单来说说这个下一代视觉推理系统的组成模块:
- ① local module (负责像素级推理)
仍然属于卷积推理模式.
- ② global module (负责基于图结构的推理)
根据区域region和class建立图(region和class都是图中的两种node, region-region, class-class, region-class是图中的三种edge.)
- ③ 将两个模块输出的结果进行cross-feed (进行spatial 和 semantic 特征的融合)
这两个模块相互迭代, 把输出相互喂.以便优化我们的估计: estimates.
- ④ 加入timestep维度 (可以参考Keras里面的
ConvLSTM2D)
下图的 S 1 S_1 S1, M 1 M_1 M1, a 1 l a_1^l a1l, f 1 l f_1^l f1l对应第1个时间步的输出. 同样地, S n S_n Sn, M n M_n Mn, a n l a_n^l anl, f n l f_n^l fnl对应第n个时间步的输出. 可以看出在推理框架最后的attention-based prediction中, 将每个时间步的 a i l a_i^l ail都放到下面的attentions里面, 进行combined; 同理对 f i l f_i^l fil.
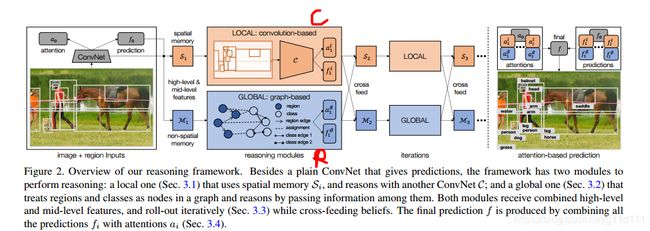
经分析代码得知, a i l a_i^l ail的shape的N x n_classes(在ADE数据集是1485个类别), f i l f_i^l fil是 a i l a_i^l ail经过softmax的结果, shape保持不变.
1. 局部模块local module
局部模块中:
-
① spatial memory( S S S)的概念是: 用 S S S将输入的obj的区域按一定的规则放置在经过多层卷积后的特征图中对应的位置.S为3维: D D D x n h nh nh x n w nw nw(抛开batchsize这个维度), D D D为设置的超参数深度(512) n h = m a t h . c e i l ( h / 16.0 ) ; n w = m a t h . c e i l ( w / 16.0 ) nh = math.ceil(h / 16.0) ; nw = math.ceil(w / 16.0) nh=math.ceil(h/16.0);nw=math.ceil(w/16.0)
其中, h h h和 w w w是输入模型的原始图像的高和宽. -
② 推理模块卷积网络 C C C, 它由三个3*3的卷积核, padding=same的卷积层和两个hidden unit=4096的全连接层组成。
给定一个未更新的图像区域 r r r,先通过特征提取,然后使用bilinear插值将其调整为大小7 x 7的区域 h h h。因为高层的特征 f f f是覆盖整个区域的向量,所以我们将这个向量附加到 h h h的所有位置,通过1 x 1的卷积核来提取特征,并且输出 f r f_r fr。记忆存储器 s i s_i si中的相同区域也提取出来,通过经过crop & resize, 变为7 x 7,标记为 s r s_r sr。这一步后,我们使用类似GRU的策略:
s r ′ = u ∘ s r + ( 1 − u ) ∘ σ ( W f f r + W s ( z ∘ s r ) + b ) s^′_r =u∘s_r+(1−u)∘σ(W_f f_r+W_s(z∘sr)+b) sr′=u∘sr+(1−u)∘σ(Wffr+Ws(z∘sr)+b)
注意, 代码的更新策略是 u ○ ( σ ( W f f r + W s ( z ○ s r ) ) − s r ) u ○ (σ(W_f f_r + W_s (z ○ s_r)) - s_r) u○(σ(Wffr+Ws(z○sr))−sr), 跟上式不同.
其中, s r ′ s^′_r sr′是 r r r更新后的记忆, u u u是更新门, z z z是重置门, W f W_f Wf, W s W_s Ws和 b b b分别是卷积的权重和偏置,∘表示entry-wise矩阵内积(hadamard积), σ σ σ表示激活函数。更新后, s ′ r s′r s′r通过提取特征和尺寸调整重新放回 S S S.
下面说一下代码里面的memory S S S更新策略(代码中的bsize都是1, ADE数据集的类别为1485):
我看的是PyTorch版本:https://github.com/coderSkyChen/Iterative-Visual-Reasoning.pytorch
在第1次迭代的时候: mem是 bsize x 512 x sh x sw(值都是0)的Tensor.
- ① 因为让原始图像通过resnet50的前4层, 得到了一个shape为bsize x 1024 x sh x sw的base_feature_map(简写叫base_feat), 对其后面接上自定义的
CropAndResize层后, 得到pool5/pool5_nb, 其shape为N(region个数) x 1024 x 7 x 7
输入到resnet50的最后1层, 最后接上一个用于分类的全连接层. 得到cls_score_conv, 其shape为N(region个数) x n_classes(1485). - ② 以第一次迭代进行说明memory 更新方式:
重要参数说明:
pool5_nb(Tensor) N x 1024 x 7 x 7.
cls_score_conv(Tensor) N x 1485,
( 是self._mem_pred中的第1个返回值. 第一次迭代memory S的时候中用的是
cls_score_conv, 以后则用cls_score_mem(关于这个值是怎么计算的,这里不详细展开。)
mem(Tensor) 1 x 512 x sh x sw(全是0).
rois(Tensor) N x 4
inv_rois(Tensor) N x 4 (跟rois一起产生, 维度一样, 不过数值都很小)
iter(int) 0, 1, ...
处理流程说明:
① 与self._mem_pred生成mem_ct_pool5之前先卷积不同, pool5_mem是直接通过对mem进行CropAndResize得到的
N x 512 x 7 x 7的Tensor.
② self._input_module是由1个bottomup module和1个卷积层+ReLU的序贯模型组成的.
其中:
2.1) self._bottomtop按作者注释的意思是: "让特征的描述能力更丰富" 也就是论文里面提到的bottomtop机制在本推理框架中的使用.
它由2个part组成: self._bottomtop_fc和self._bottomtop_conv.
具体说明在放在这个函数体内部了.
2.2) self._input就是一个卷积层+ReLU, 接收的是_bottomtop的输出.
得到N x 512 x 7 x 7的pool5_input.
③ 接着,把前面得到的pool5_input & pool5_mem传入到self._mem_update函数中.
这个函数的作用是实现论文中的公式1的逻辑.
btw, 大致计算逻辑跟公式1一样, 有差别, 差别记录在self._mem_update函数的注释中了.
通过这一步, 得到mem_update: N x 512 x 7 x 7的Tensor.
④ 最后, 通过self._inv_crops将mem_update变成 N x 512 x sh x sw的 tmp_mem, 按其depth求和,
得到mem_diff: N x sh x sw的Tensor.
一定要注意! 记忆mem(S)是要从N x 512 x 7 x 7 回到 1 x 512 x sh x sw的, 因为mem的原始状态就是 1 x 512 x sh x sw的.
因为 self._count_matrix_eps为 1 x sh x sw. 更新memory用到的 / 跟前面公式1中的 * 相似.
最终!!! 我们通过这一大堆的操作, 更新mem, 并返回!
2. 全局模块global module
global module里面有3组点–边关系
-
a) N r N_r Nr(Region的节点) ϵ r \epsilon_r ϵr(Region的边) 区域图
-
b) N r N_r Nr到 N c N_c Nc的边 ϵ r − > c \epsilon_{r->c} ϵr−>c和 ϵ c − > r \epsilon_{c->r} ϵc−>r: 在为Region分配class的时候建立. 分配图
-
c) N c N_c Nc(Class的节点) ϵ c \epsilon_c ϵc(Class的边) 知识图
类之间的关系有 “相似” “属于” “一部分”
比如:
cake属于food.
wheel is part of car.
puma与leopard相似.
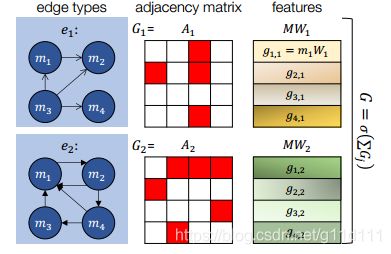
上图显示了如何在拥有不同类型的边(edge)的图中直接传递信息.容易看出:
node之间的联系是单向的. 邻近矩阵(adjacency matrix)中, 红色表示有连线的边.白色表示无连线的边. 我们有3种edge类型,2种node类型.
如图所示,四个节点之间通过不同的边连接。每个节点表示一个输入特征向量 M i M_i Mi。中间的 A j A_j Aj表示连接矩阵,用来描述各边 M i M_i Mi之间的关系,我们通过训练学习到一组权重 W W W。最后的输出为 G G G。
接着就是推理的过程。我们假设输入是 M r M_r Mr和 M c M_c Mc(类别),让它们分别走global module中两条推理路径(spatial path/ semantic path).
以region=2为例, 图像中的信息就是一个人骑车.对region node: M r M_r Mr为2x512. 人标识为region1.车标识为region2.对class node: M c M_c Mc为class(比如我们这个任务只有3个类:人,自行车, 树, 那么这个class应该为3,跟region的个数无关)x512.
这里, R = 2, C = 3, D = 512.
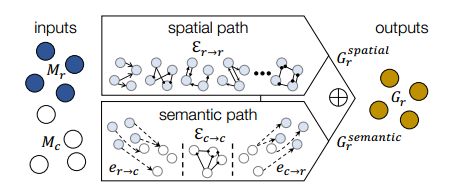
下面的r, c, d对应上面举得例子中的R, C和D.

所以, 就像我们在CNN中堆叠卷积层一样,我们同样可以堆叠组建上面所说的结构.输出 G r G_r Gr可以作为下一个图形操作的输入, 这允许本框架使用更深层次的特征执行联合空间-语义推理 (spatial-semantic reasoning).
3. 迭代推理Iterative Reasoning
推理过程中关键组成部分是迭代地(iteratively)构建估计(estimates).
但是,信息是如何从一次迭代传导到下一次的呢?我们用explicit memory来做这件事.explicit memory存放了之前所有迭代的历史信息.
在第i次迭代时, local module中, 我们将 S i S_i Si输入到卷积推理模块 C C C来生成对每个region的新的预测结果 f i l f_i^l fil. 同样地, global module, 有同样地情况,从 G r / R G_r/R Gr/R中产生新的预测结果 f i g f_i^g fig.
虽然说使用者可以独立使用local module和global module.
但是我们想发挥两个模块的合力(join force),所以提出了cross-feed connections的策略:
“在每次迭代推理后, local/global的输出将会concat, 通过类似GRU的策略来更新 S i + 1 S_{i+1} Si+1和 M i + 1 M_{i+1} Mi+1.”
通过这样, local module中的空间记忆单元 S S S可以从
全局空间信息(global knowledge of spatial) 和 语义关系(semantic relationships) 中汲取信息; global module中的图 G G G也能更加理解局部区域的布局(有助于图结构的构建更加贴合实际情况.).
4. 试验结果
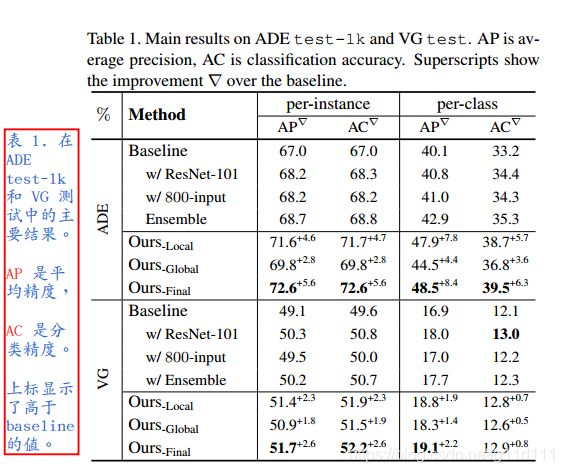
通过在ADE数据集的试验, 作者认为通过这种新式结构获得的准确率和精度的提升收益高于增加卷积网络的深度。

图中蓝色的部分的两个数字分别表示baseline的预测值和本方法的预测值.
显然, 对机身(fuselage), baseline预测的结果是0.26, 0.01,0.10 而本文方法预测的结果大大优于baseline.
5. 参考资料
[1] Iterative Visual Reasoning Beyond Convolutions
[2] Iterative Visual Reasoning Beyond Convolutions论文笔记
[3] Iterative Visual Reasoning Beyond Convolutions 卷积推理网络论文翻译和阅读