python可视化工具示例
python可视化工具示例
- 所需python第三方库
- matplotlib绘制折线图组合图示例
- seaborn绘制各维度的数据分布图
- plotly_express多维度数据可视化[^2]
- 结语
所需python第三方库
- numpy
- pandas
- sklearn(仅用于导入iris数据集)
- matplotlib
- seaborn
- plotly_express
matplotlib绘制折线图组合图示例
在这个示例中,我使用了某个地铁站台一天的出入站人流数据作为样例数据1
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rcParams["font.sans-serif"] = ['Simhei']
mpl.rcParams["axes.unicode_minus"] = False
text = ["无平滑", "平滑窗口为3", "平滑窗口为5"]
fig, axes = plt.subplots(3, 1, figsize=(15, 10)) # 得到一张3x1的大小为15x10(相对大小)的画布
for idx, window_size in enumerate((1, 3, 5)):
ax = axes[idx] # 获取子图,此处由于只有一列故为一维列表,如行列数都不为1则为二维列表
x = range(144) # 设置x轴坐标值
# 对地铁站入站人流数据进行滑动平均处理后作为y坐标值,
# 第二个参数代表可计算平均值所需包含的滑动窗口内的最少数据量,
# center为True代表滑动窗口的中心位于当前数据
y = data['inNums'].rolling(window=window_size, min_periods=1, center=True).mean()
ax.plot(x, y) # 在子图上绘制折线图
y = data['outNums'].rolling(window=window_size, min_periods=1, center=True).mean() # 出站数据
ax.plot(x, y)
ax.legend(["进站", "出站"], prop={
'size': 20}) # 设置图例及字体大小
ax.set_xlabel("累计十分钟段", size=20) # 设置x标签名并指定字体大小
ax.set_ylabel("人次", size=20) # 设置y标签名并指定字体大小
ax.set_xticks(range(0, 145, 6)) # 手动设置x坐标示数
ax.set_yticks(range(0, 2001, 500)) # 手动设置x坐标示数
ax.tick_params(axis='both', labelsize=20) # 设置x,y坐标值字体大小
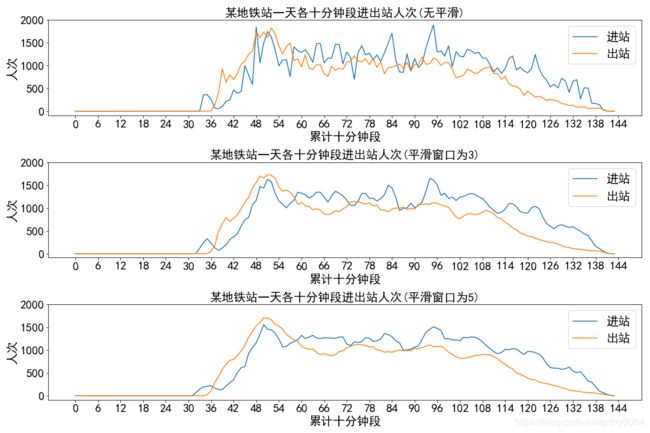
ax.set_title("某地铁站一天各十分钟段进出站人次(%s)" % (text[idx]), size=20) # 设置组合图的标题及字体大小
fig.tight_layout() # 自动调整子图间隔,避免文字重叠
plt.show() # 显示组合图
效果如下图
seaborn绘制各维度的数据分布图
这里我们使用iris数据集作为样例数据,为了方便起见,直接使用sklearn导入数据集。
from sklearn.datasets import load_iris
import seaborn as sns
import pandas as pd
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
iris_data = load_iris() # 导入iris数据
feature = pd.DataFrame(iris_data["data"], columns=iris_data["feature_names"]) # 维度为4的特征数据
target = np.array(iris_data["target"]) # 目标种类的编号
ax = [(x, y) for x in range(2) for y in range(2)] # 子图坐标
fig, axes = plt.subplots(2, 2, figsize=(20, 10)) # 得到大小为20x10,行列为2x2的画布,包含四个子图
for feature_name, (x, y) in zip(iris_data["feature_names"], ax):
for target_idx in range(len(iris_data["target_names"])):
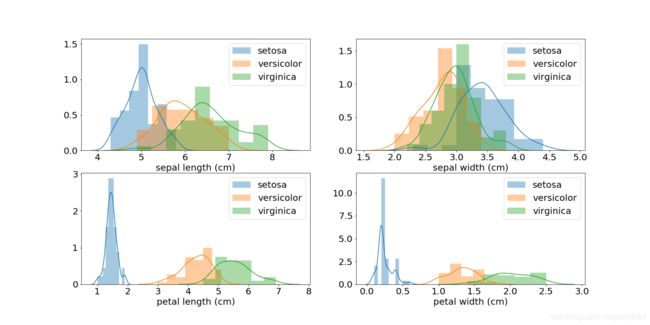
sns.distplot(feature.loc[target == target_idx, feature_name], ax=axes[x, y]) # 在子图上绘制分布图
ax = axes[x, y]
ax.legend(iris_data['target_names'], prop={
'size': 20}) # 设置图例
ax.set_xlabel(feature_name, size=20) # 设置x坐标标签
ax.tick_params(axis='both', labelsize=20) # 设置x,y两个坐标示数的字体大小
plt.show()
效果如下图
plotly_express多维度数据可视化2
同上,我们继续对iris数据集进行多维度的可视化
from sklearn.datasets import load_iris
import pandas as pd
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import plotly_express as px
iris_data = load_iris() # 导入iris数据
feature = pd.DataFrame(iris_data["data"], columns=iris_data["feature_names"]) # 维度为4的特征数据
target = np.array(iris_data["target"]) # 目标种类的编号
feature_names = iris_data['feature_names'] # 特征名列表
feature['target'] = target # 添加目标编号到特征数据中
# x,y,z,size分别设置为feature的四个列的名字,color设置为新加入的target列的名字
# 从4个维度可视化数据(3维坐标+点的大小),准确来说是5个维度(忽视target的意义的话,多了颜色深浅)
px.scatter_3d(feature, x=feature_names[0], y=feature_names[1], z=feature_names[2], size=feature_names[3], color='target')
效果如下图

上面这种方法不适用于数据维度过大的数据,这时我们可采用下面的方法进行可视化
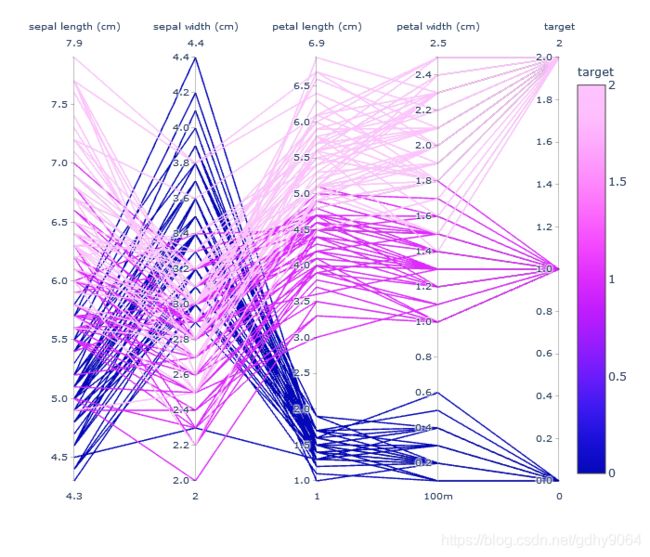
# 适用于具有多维特征的数据
px.parallel_coordinates(feature, labels=feature.columns, color='target')
效果如下图
结语
上述第三方库的功能不限于此,更多可视化形式可参考其官方文档。
样例数据可在此处下载,其中test.csv为此次所用精简后的测试数据。 ↩︎
参考自https://www.plotly.express/ ↩︎