Programming basics: Blocks in the user program
摘自Programming the PLC
1.1 Operating system and user program
The following figure shows the interaction of the operating system and the user program:

Operating system (OS)
The tasks of the operating system, for example, include the following:
● Processing a warm restart
● Updating the process image of the inputs and outputs
● Calling the user program
● Detecting interrupts and calling interrupt OBs
● Detecting and handling errors
● Managing memory areas
1.2 Blocks in the user program
Organization blocks (OB)
Organization blocks (OBs) form the interface between the operating system and the user program. They are called by the operating system and control, for example, the following operations:
● Startup characteristics of the automation system
● Cyclic program processing
● Interrupt-driven program execution
● Error handling
You can program the organization blocks and at the same time determine the behavior of the CPU.
When certain organization blocks are started, the operating system provides information that can be evaluated in the user program.
Functions (FCs)
Functions (FCs) are code blocks without memory. You have no data memory in which values of block parameters can be stored. Therefore, when a function is called, all formal parameters must be assigned actual parameters.
Functions can use global data blocks to store data permanently.
A function contains a program that is executed when the function is called by another code block. Functions can be used, for example, for the following purposes:
● To return function values to the calling block, e.g. for mathematical functions
● To execute technological functions, e.g. individual controls using bit logic operations
A function can also be called several times at different points in a program. As a result, they simplify programming of frequently recurring functions.
Function blocks (FB)
Function blocks are code blocks that store their input, output and in-out parameters permanently in instance data blocks, so that they remain available even after the block has been executed. Therefore they are also referred to as blocks "with memory".
Function blocks can also operate with temporary tags. Temporary tags are will not be stored in the instance DB, but are available for one cycle only.
A call of a function block is referred to as an instance. An instance data block is required for each instance of a function block; it contains instance-specific values for the formal parameters declared in the function block.
The function block can store its instance-specific data in its own instance data block or in the instance data block of the calling block.
S7-1200 and S7-1500 offer two different access options for the instance data blocks, which can be assigned to a function block when this is called:
● Data blocks with optimized access
Data blocks with optimized access have no firmly defined memory structure. The data elements contain only a symbolic name in the declaration, no fixed address within the block.
● Data blocks with standard access (compatible with S7-300/400)
Data blocks with standard access have a fixed memory structure. The declaration elements contain both a symbolic name in the declaration and a fixed address within the block.
Global data blocks (DB)
Data blocks are used to store program data. Global data blocks store data that can be used by all other blocks.
The maximum size of data blocks varies depending on the CPU. You can define the structure of global data blocks anyway you please.
You also have the option of using PLC data types (UDT) as a template for creating global data blocks.
Every function block, function, or organization block can read the data from a global data block or can itself write data to a global data block.
The following figure shows the different accesses to data blocks:
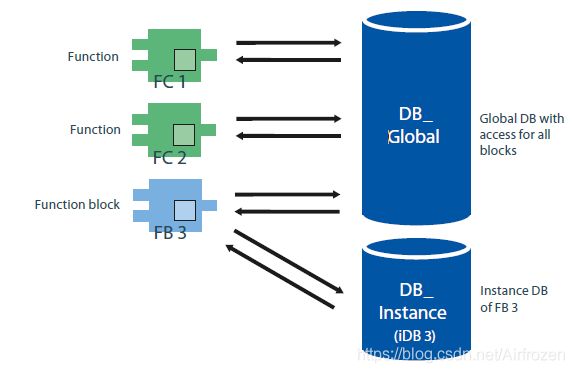
S7-1200 and S7-1500 offer two different access options for global data blocks:
● Data blocks with optimized access
● Data blocks with standard access (compatible with S7-300/400)
Global ARRAY data blocks (DB)
To be continued......
Instance data blocks
The call of a function block is referred to as an instance. The data with which the instance works is stored in an instance data block. The tags declared in the function block determine the structure of the instance data block.
S7-1200 and S7-1500 offer two different access options for the instance data blocks, which can be assigned to a function block when this is called:
● Data blocks with optimized access
● Data blocks with standard access (compatible with S7-300/400)
CPU data blocks
CPU data blocks are generated by the CPU at runtime. To this purpose, insert the "CREATE_DB" instruction into your user program. You can use the data block that is generated at runtime to save your data.
You can monitor the values of the variables of a CPU data block in online mode, similar to those of a different data block type.
You cannot create CPU data blocks in your offline project.
The CPU data block that the user program has generated by means of the "CREATE_DB" instruction is initially only available on the device in online mode. All CPU data blocks will be included with the other blocks the next time you perform a complete download from the device to the project. However, you cannot upload these CPU data blocks to your device again.
Once the CPU data blocks have been loaded into your offline project, you can run an offline/online comparison for the CPU DBs loaded. It is possible to synchronize the online and off-line version of CPU data blocks if differences are found, but not by downloading the offline version to the device.
Blocks with optimized access
STEP 7 offers data blocks with different access options:
● Data blocks with optimized access (S7-1200/S7-1500)
● Data blocks with standard access (S7-300 / S7-400 / S7-1200 / S7-1500)
Within one program you can combine the two types of blocks.
Data blocks with optimized access have no fixed defined structure. In the declaration, the data elements are assigned only a symbolic name and no fixed address within the block. The elements are saved automatically in the available memory area of the block so that there are no gaps in the memory. This makes for optimal use of the memory capacity.
Tags are identified by their symbolic names in these data blocks. To address the tag, enter its symbolic name. For example, you access the "Fill Level" tag in the "Data" DB as follows: "Data".Fill Level
Blocks with optimized access offers the following advantages:
● You can create data blocks with any structure without paying attention to the physical arrangement of the individual data elements.
● Quick access to the optimized data is always available because the data storage is optimized and managed by the system.
● Access errors, as with indirect addressing or from the HMI, for example, are not possible.
● You can define specific individual tags as retentive.
● Optimized blocks are equipped with a memory reserve by default which lets you expand the interfaces of function blocks or data blocks during operation. You can download the modified blocks without setting the CPU to STOP and without affecting the values of already loaded tags.
The "Optimized block access" attribute is always enabled for the following blocks and cannot be deselected.
● GRAPH blocks
● ARRAY data blocks
Data blocks with standard access
Data blocks with standard access have a fixed structure. In the declaration, the data elements are assigned both a symbolic name and a fixed address within the block. The address is shown in the "Offset" column.
Tags in these data blocks can be addressed in both symbolic and absolute form: "Data".Fill Level or DB1.DBW2
Setting Retentivity for Optimized Access or Standard Access
If you define data as retentive, its values are retained even after a power failure or a network off. A retentive tag is not initialized after the hot restart but retains the value it had prior to the power failure. If a DB tag is defined as retentive, it is stored in the retentive memory area of the data block.
The options for setting the retentivity depend on the access type of the block.
● In data blocks with standard access, you cannot set the retentive behavior of individual tags. The retentivity setting is valid for all tags of the data block.
● In data blocks with optimized access you can define the retentive behavior of individual tags.
For structured data type tags, the retentivity setting always applies to the entire structure. You cannot make any individual retentivity setting for separate elements within the data type.
Setting Addressing Options for Optimized Access or Standard Access
Blocks with optimized access permit only "type-safe" access. Type-safe access addresses tags by their symbolic name only. This means even changes to the block or the block interface will not result in inconsistencies in the program or access errors.
The following table shows the permitted addressing options for optimized data:

Setting up block access
Block access is set up automatically when you create a block:
● Blocks created on CPUs of the S7-1200/1500 product range provide optimized access by means of a default setting.
● New blocks created on CPUs of the S7-300/S7-400 product range provide standard access by means of a default setting.
Access to a block that you copy or migrate to a CPU of a different product range is not converted automatically. However, in certain situations it may be useful to change block access in manual mode, e.g., in order to utilize the full functional scope of the CPU.
In most cases, you will have to recompile and load the program after block access has been converted.
The following restrictions or special features apply in this context:
● Instance data blocks
The block access of instance data blocks is always determined by the assigned function block and cannot be changed in manual mode. If you change the access mode on a function block, you also need to update the assigned instance data blocks. This update procedure adapts the access mode of the instance data block.
● System blocks and know-how protected blocks
You cannot manually edit the block access for system blocks and know-how protected blocks.
● Organization blocks
The start information of an OB with standard access is always stored in the first 20 bytes of the "Temp" section in the block interface. By contrast, the start information of an OB with optimized access is always written to the "Input" section. For this reason, the block interface of OBs will also change whenever you convert block access.
Converting block access from "standard" to "optimized"
A block copied from the CPU of the S7-300/400 product range to a CPU of the S7-1200/1500 product range will initially retain the "standard" access mode. However, you can significantly increase the performance of program execution by using blocks with optimized access.
The blocks are adapted as follows in the course of conversion:
● Function blocks
All interface parameters are assigned the "Non-retain" retentivity setting.
● Global data blocks
The retentivity setting that was assigned centrally to the entire data block is transferred to the individual interface parameters.
● Organization blocks
All interface parameters that are stored in the first 20 bytes of the "Temp" section will be deleted. New CPU-specific start information is entered in the "Input" section. Naming conflicts with user-defined interface parameters occurring in the process are resolved by renaming the user-defined interface parameters.
The conversion of the block access has the following consequences:
● Absolute addressing of the interface parameters of the block is no longer possible after conversion of block access to the optimized mode. Example: #L0.1 is no longer valid.
● Since conversion to the "optimized" block access mode of organization blocks also modifies the OB interface,
You may possibly have to adapt, recompile and load the program again due to these changes.
Converting block access from "optimized" to "standard"
The blocks are adapted as follows in the course of conversion:
● Function blocks and global data blocks.
You can no longer set a retentivity in the function block. The corresponding setting is made in the instance data block.
All interface parameters in the instance DB or global DB are assigned the same retentivity setting. The conversion is subject to the following rule:
– If all interface parameters in the original block were retentive, the entire block will be
retentive after conversion.
– If all interface parameters in the original block were non-retentive, the entire block will
be non-retentive after conversion.
– If the interface parameters in the original block had different retentivity settings, the entire
block will be non-retentive after conversion.
● Organization blocks
All interface parameters stored in the "Input" section will be deleted. New CPU-specific start information is entered in the "Temp" section. This data is written to the first 20 bytes. Naming conflicts with user-defined interface parameters occurring in the process are resolved by renaming the user-defined interface parameters.
The conversion of the block access has the following consequences:
Since a conversion to "standard" block access mode might change the retentivity settings of the interface parameters, you may possibly have to adapt, recompile and load the program again due to these changes.