Oracle19c 通过 OGG 同步数据到 kafka
小小博客
ogg 安装
参考:
利用ogg实现oracle到kafka的增量数据实时同步
Oracle® GoldenGate Installing and Configuring Oracle GoldenGate for Oracle Database
ogg-multitenant-2408073.pdf
经典模式升级集成模式
静默安装 Oracle19c
环境准备
| IP | 别名 | 安装软件 |
|---|---|---|
| 192.168.1.111 | node1 | jdk1.8、Oracle19c、V983658-01 |
| 192.168.1.112 | node2 | jdk1.8、Kafka-2.3.0、zookeeper-3.5.6、OGG_BigData_Linux_x64_19.1.0.0.1 |
软件下载
node1 ogg V983658-01
node2 ogg OGG_BigData_Linux_x64_19.1.0.0.1
V983658-01下载比较麻烦 ,需要有Oracle 账号
看图片上面数字操作

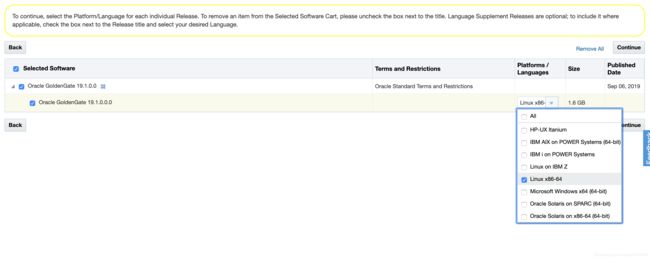


软件安装
分别在两台机器安装上述软件,jdk、Kafka、zookeeper 可自行百度,这不是重点!重点是下面的配置操作
修改 hosts
分别在两台机器执行
[root@node1 ~]# vi /etc/hosts
192.168.1.111 node1
192.168.1.112 node2
node1、node2 安装 OGG
建议 node1和 node2 安装路径一致;安装均使用 GUI 安装
node1 解压 V983658-01 安装
node2 解压OGG_BigData_Linux_x64_19.1.0.0.1安装
配置环境变量
export OGG_HOME=/u19/app/oggserver
export LD_LIBRARY_PATH=$ORACLE_HOME/lib:/usr/lib:/usr/local/java/jdk1.8.0_91/jre/lib/amd64/server
export PATH=$OGG_HOME:$PATH
node1 OGG 安装
Oracle打开归档模式
切换到Oracle用户 连接 sqlplus
[root@node1 ~]# su – oracle
[oracle@node1 ~]# sqlplus / as sysdba
查看是否开启
SQL> archive log list
Database log mode No Archive Mode
Automatic archival Disabled
Archive destination USE_DB_RECOVERY_FILE_DEST
Oldest online log sequence 12
Current log sequence 14
如果Automatic archival是Disabled 则需要修改
SQL> conn / as sysdba (以DBA身份连接数据库)
SQL> shutdown immediate (立即关闭数据库)
SQL> startup mount (启动实例并加载数据库,但不打开)
SQL> alter database archivelog; (更改数据库为归档模式)
SQL> alter database open; (打开数据库)
SQL> alter system archive log start; (启用自动归档)
再执行一下 archive log list
SQL> archive log list
Database log mode Archive Mode
Automatic archival Enabled
Archive destination USE_DB_RECOVERY_FILE_DEST
Oldest online log sequence 12
Next log sequence to archive 14
Current log sequence 14
可以看到Automatic archival为Enabled,则成功打开归档模式。
Oracle打开日志相关
- OGG基于辅助日志等进行实时传输,故需要打开相关日志确保可获取事务内容,通过下面的命令查看该状态
- 若为NO,则需要通过命令修改
- 执行完 alter 后,可以再次查看为 YES即可
SQL> select force_logging, supplemental_log_datamin from v$database;
FORCE SUPPLEMENTAL_LOG
NO NO
SQL> alter database force logging;
SQL> alter database add supplemental log data;
SQL> select force_logging, supplemental_log_datamin from v$database;
FORCE SUPPLEMENTAL_LOG
YES YES
创建同步表
[root@node1 ~]# su – oracle
[oracle@node1 ~]# sqlplus test_ogg/test_ogg@localhost/pdb1
DROP TABLE tcustmer;
CREATE TABLE tcustmer
(
cust_code VARCHAR2(4),
name VARCHAR2(30),
city VARCHAR2(20),
state CHAR(2),
PRIMARY KEY (cust_code)
USING INDEX
);
OGG配置
创建新的PDB,并且指定用户test_ogg
[root@node1 ~]# su – oracle
[oracle@node1 ~]# sqlplus / as sysdba
SQL> create pluggable database pdb1 admin user test_ogg identified by test_ogg file_name_convert=('pdbseed','pdb1');
# 打开pdb1
SQL> alter session set container=pdb1;
SQL> alter database pdb1 open;
设置用户权限
SQL> alert session set container=pdb1;
SQL> grant dba to test_ogg;
SQL> exec dbms_goldengate_auth.grant_admin_privilege('test_ogg',container=>'pdb1');
Create OGG Extract User 用于同步任务
[root@node1 ~]# su – oracle
[oracle@node1 ~]# sqlplus / as sysdba
SQL> ALTER SYSTEM SET ENABLE_GOLDENGATE_REPLICATION = TRUE;
SQL> create user c##ggadmin identified by ggadmin;
SQL> exec dbms_goldengate_auth.grant_admin_privilege('c##ggadmin',container=>'ALL');
SQL> grant dba to c##ggadmin container=all;
# 测试用户
SQL> connect c##ggadmin/ggadmin
初始化OGG
[root@node1 ~]# su – oracle
[oracle@node1 ~]# cd $OGG_HOME
[oracle@node1 ggserver]# ggsci
GGSCI (node1) 1 > create subdirs
登陆pdb1
GGSCI (node1) 2 > dblogin userid test_ogg@localhost/pdb1,password test_ogg
配置mgr
此命令等价于 vim
GGSCI (node1) > edit param mgr
以下是 mgr 内容
PORT 7809
DYNAMICPORTLIST 7810-7909
AUTORESTART EXTRACT ,RETRIES 5,WAITMINUTES 3
PURGEOLDEXTRACTS ./dirdat/,usecheckpoints, minkeepdays 3
说明:
PORT即mgr的默认监听端口;
DYNAMICPORTLIST动态端口列表,当指定的mgr端口不可用时,会在这个端口列表中选择一个,最大指定范围为256个;
AUTORESTART重启参数设置表示重启所有EXTRACT进程,最多5次,每次间隔3分钟;PURGEOLDEXTRACTS即TRAIL文件的定期清理
注册数据库
需要登陆根库注册; 注册完成后再使用 test_ogg@localhost/pdb1登陆做后续配置
修改抽取模式;需要记住 register 执行成功后的 scn
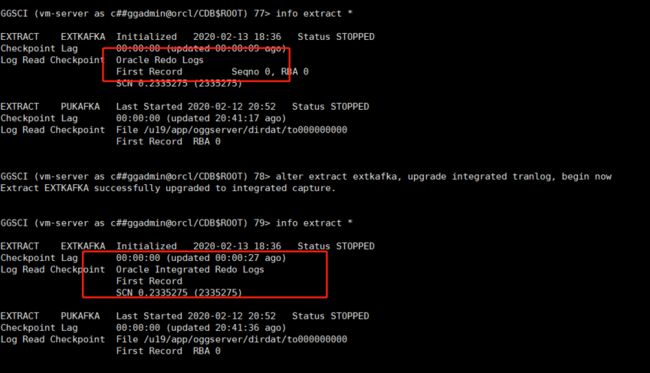
详情见下图
GGSCI (node1) > dblogin userid c##ggadmin,password ggadmin
GGSCI (node1) > register extract extkafka database container (pdb1)
GGSCI (node1) > alter extract extkafka ,scn 2335275
GGSCI (node1) > alter extract extkafka ,upgrade integrated tranlog,begin now
添加复制表
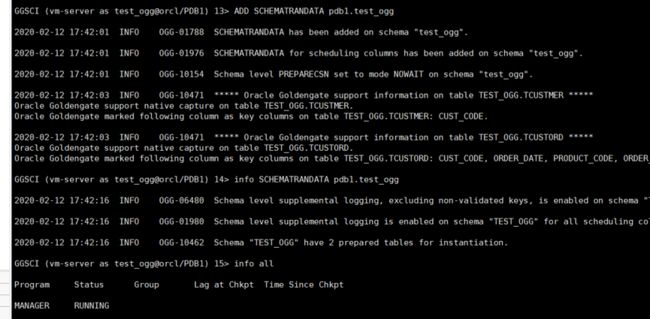
GGSCI (node1) > add trandata pdb1.test_ogg.tcustmer
GGSCI (node1) > add schematrandata pdb1.test_ogg
trandata 添加表使用;
schematrandata 添加库使用
配置extract
GGSCI (node1) > edit param extkafka
以下是 extkafka 内容
extract extkafka
dynamicresolution
userid c##ggadmin,password ggadmin
setenv(ORACLE_SID=orcl)
exttrail /u19/app/oggserver/dirdat/to
DDL INCLUDE MAPPED
DDLOPTIONS REPORT
LOGALLSUPCOLS
SOURCECATALOG pdb1
TABLE test_ogg.tcustmer;
说明:
第一行指定extract进程名称;
dynamicresolution动态解析;
SETENV设置环境变量;
userid c##ggadmin,password ggadmin 即OGG连接Oracle数据库的帐号密码;
exttrail定义trail文件的保存位置以及文件名,注意这里文件名只能是2个字母,其余部分OGG会补齐;
SOURCECATALOG 制定 pdb
table即复制表的表名,支持通配,必须以;结尾
添加extract进程
添加trail文件的定义与extract进程绑定
GGSCI (node1) > Add extract extkafka,tranlog,begin now
GGSCI (node1) > Add exttrail /u19/app/oggserver/dirdat/to,extract extkafka
配置pump进程
GGSCI (node1) > edit param pukafka
以下是 pukafka 内容
extract pukafka
passthru
userid c##ggadmin,password ggadmin
rmthost 192.168.1.112 mgrport 7809
rmttrail /u19/app/oggserver/dirdat/to
DDL INCLUDE MAPPED
DDLOPTIONS REPORT
table pdb1.test_ogg.tcustmer;
说明:
第一行指定extract进程名称;
passthru即禁止OGG与Oracle交互,我们这里使用pump逻辑传输,故禁止即可;
userid c## ggadmin,password c## ggadmin 即OGG连接Oracle数据库的帐号密码
rmthost和mgrhost即目标端(kafka)OGG的mgr服务的地址以及监听端口;
rmttrail即目标端trail文件存储位置以及名称。
Table 表 ;
分别将本地trail文件和目标端的trail文件绑定到extract进程:
GGSCI (node1) > add extract pukafka,exttrailsource /u19/app/oggserver/dirdat/to
GGSCI (node1) > add rmttrail /u19/app/oggserver/dirdat/to,extract pukafka
配置define文件
Oracle与MySQL,Hadoop集群(HDFS,Hive,kafka等)等之间数据传输可以定义为异构数据类型的传输,故需要定义表之间的关系映射,在OGG命令行执行:
GGSCI (node1) > edit param test_ogg
以下是 pukafka 内容
defsfile /u19/app/oggserver/dirdef/test_ogg.tcustmer
userid c##ggadmin,password ggadmin
table pdb1.test_ogg.tcustmer;
在OGG主目录下执行(oracle用户):
生成 / u19/app/oggserver /dirdef/test_ogg.tcustmer
并且发送到目标端oggserver目录下的dirdef里
[root@node1 ~]# su - oracle
[oracle@node1 ~]# cd $OGG_HOME
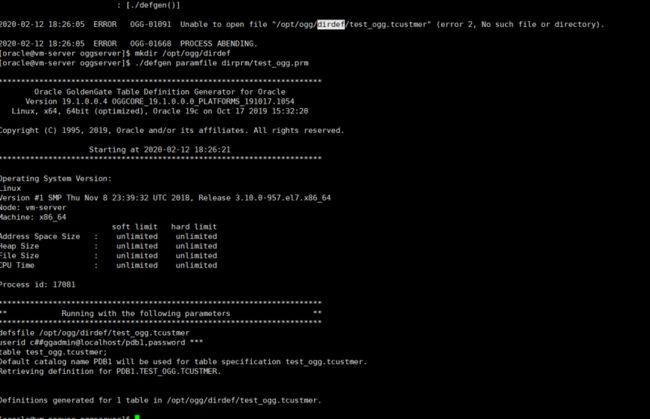
[oracle@node1 ggserver]# ./defgen paramfile dirprm/test_ogg.prm
[oracle@node1 ggserver]#scp -r /u19/app/oggserver/dirdef/test_ogg.tcustmer root@node2:/u19/app/oggserver/dirdef/
node2 OGG安装
开启zookeeper服务
[root@node2 ~] cd /home/server/zookeeper
[root@node2 zookeeper] ./bin/zkServer.sh start
开启kafka服务
[root@node2 ~] cd /home/server/kafka_2.11-2.3.0/
[root@node2 kafka_2.11-2.3.0] ./bin/kafka-server-start.sh -daemon ./config/server.properties
配置管理器mgr
GGSCI (node2) > edit param mgr
PORT 7809
DYNAMICPORTLIST 7810-7909
AUTORESTART EXTRACT ,RETRIES 5,WAITMINUTES 3
PURGEOLDEXTRACTS ./dirdat/,usecheckpoints, minkeepdays 3
配置checkpoint
checkpoint即复制可追溯的一个偏移量记录,在全局配置里添加checkpoint表即可。
GGSCI (node2) > edit param ./GLOBALS
CHECKPOINTTABLE test_ogg.checkpoint
配置replicate进程
GGSCI (node2) > edit param rekafka
REPLICAT rekafka
sourcedefs /u19/app/oggserver/dirdef/test_ogg.test_ogg
TARGETDB LIBFILE libggjava.so SET property=dirprm/kafka.props
REPORTCOUNT EVERY 1 MINUTES, RATE
GROUPTRANSOPS 10000
MAP pdb1.test_ogg.tcustmer, TARGET pdb1.test_ogg.tcustmer;
说明:
REPLICATE rekafka定义rep进程名称;
sourcedefs即在3-7中在源服务器上做的表映射文件;
TARGETDB LIBFILE即定义kafka一些适配性的库文件以及配置文件,配置文件位于OGG主目录下的dirprm/kafka.props;
REPORTCOUNT即复制任务的报告生成频率;
GROUPTRANSOPS为以事务传输时,事务合并的单位,减少IO操作;
AP即源端与目标端的映射关系
配置kafka.props
[root@node2 ~] cd / u19/app/oggserver/dirprm/
[root@node2 ggserver] vi kafka.props
gg.handlerlist=kafkahandler
gg.handler.kafkahandler.type=kafka
gg.handler.kafkahandler.KafkaProducerConfigFile=custom_kafka_producer.properties
gg.handler.kafkahandler.topicMappingTemplate=test_ogg
gg.handler.kafkahandler.format=json
gg.handler.kafkahandler.mode=op
gg.classpath=dirprm/:/home/server/kafka_2.11-2.3.0/libs/:/u19/app/oggserver/:u19/app/oggserver/lib/*
[root@node2 ggserver] vi custom_kafka_producer.properties
bootstrap.servers=192.168.1.112:9092
acks=1
compression.type=gzip
reconnect.backoff.ms=1000
value.serializer=org.apache.kafka.common.serialization.ByteArraySerializer
key.serializer=org.apache.kafka.common.serialization.ByteArraySerializer
batch.size=102400
linger.ms=10000
添加trail文件到replicate进程
GGSCI (node2) > add replicat rekafka exttrail /u19/app/oggserver/dirdat/to,checkpointtable test_ogg.checkpoint
启动所有进程
在源端和目标端的OGG命令行下使用start 进程名的形式启动所有进程。
启动顺序按照源mgr——目标mgr——源extract——源pump——目标replicate来完成。
全部需要在ogg目录下执行ggsci目录进入ogg命令行。
info all 之后所有进程为 running 才是成功
node1
GGSCI (node1) > start mgr
GGSCI (node1) > start extkafka
GGSCI (node1) > start pukafka
GGSCI (node1) > info all
Program Status Group Lag at Chkpt Time Since Chkpt
MANAGER RUNNING
EXTRACT RUNNING EXTKAFKA 04:50:21 00:00:03
EXTRACT RUNNING PUKAFKA 00:00:00 00:00:03
node2
GGSCI (node1) > start mgr
GGSCI (node1) > start rekafka
GGSCI (node1) > info all
Program Status Group Lag at Chkpt Time Since Chkpt
MANAGER RUNNING
REPLICAT RUNNING REKAFKA 00:00:00 00:00:01
测试
node1
[root@node1 ~]# su – oracle
[oracle@node1 ~]# sqlplus test_ogg/test_ogg@localhost/pdb1
SQL> INSERT INTO tcustmerVALUES('5','BG SOFTWARE CO.','SEATTLE','1');
node2
[root@node1 ~] cd /home/server/kafka_2.11-2.3.0
[root@node1 kafka_2.11-2.3.0] ./bin/kafka-console-consumer.sh --bootstrap-server node2:9092 --topic test_ogg --from-beginning
