决策树与随机森林
决策树
选择决策特征
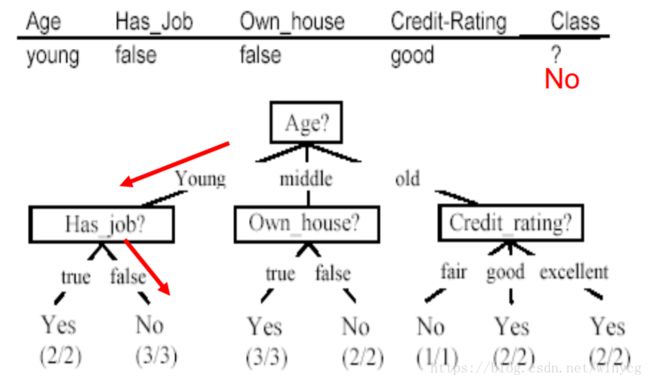
在某个结点处,选择合适(尽量减少划分数据集后的混乱度,也就是)的特征进行决策,划分数据集,生成子节点。如下如所示:

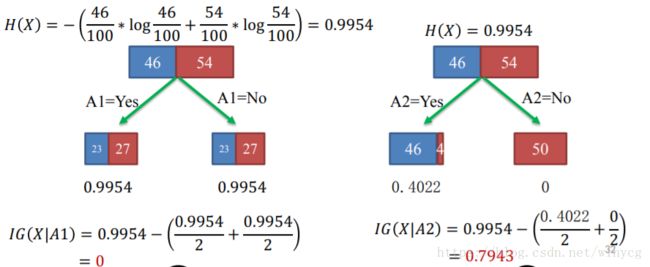
上文中提到,信息增益为选择特征 A A A后的类别变量 X X X的不确定性,因此我们要最大化信息增益,减少不确定性。
数据集合 D D D熵定义为: H ( X ) = − ∑ c = 1 C P c log P c H(X)=-\sum_{c=1}^{C}P_{c}\log{P_{c}} H(X)=−c=1∑CPclogPc
P c = 类 别 c 的 样 本 数 D 中 的 样 本 数 P_{c}=\frac{类别c的样本数}{D中的样本数} Pc=D中的样本数类别c的样本数, X X X是类别
选择特征A所带来的信息化增益为:
I G ( X ∣ A ) = H ( X ) − ( ∣ D 1 ∣ ∣ D ∣ H ( X ∣ A = Y e s ) + ∣ D 2 ∣ ∣ D ∣ H ( X ∣ A = N o ) ) IG(X|A)=H(X)-(\frac{|D_{1}|}{|D|}H(X|A=Yes)+\frac{|D_{2}|}{|D|}H(X|A=No)) IG(X∣A)=H(X)−(∣D∣∣D1∣H(X∣A=Yes)+∣D∣∣D2∣H(X∣A=No))
其中 D 1 , D 2 D_{1},D_{2} D1,D2为划分后的左右数据集
从公式可以看出,信息增益实质上为父节点的不纯度与子节点不纯度加权和的差,子节点的不纯度越低,信息增益越大。选择属性 a ∗ = arg max a ∈ A I G ( D , a ) a^{*}=\arg \max_{a\in A}{IG(D,a)} a∗=arga∈AmaxIG(D,a)
著名的ID3(Iterative Dichotomiser)决策树算法就是以信息增益为准则来划分属性的。
数值型的决策树:


决策树通过将特征空间进行矩阵划分的方式来构建复杂的决策边界。深度越大的决策树,决策边界越复杂,容易产生过拟合现象
增益率
著名的C4.5决策树算法不直接采用信息增益,而是使用增益率(gain ratio)来选择最优属性划分。增益率定义为: G a i n _ r a t i o ( D , a ) = I G ( D , a ) I V ( a ) Gain\_ratio(D,a)=\frac{IG(D,a)}{IV(a)} Gain_ratio(D,a)=IV(a)IG(D,a)
其中: I V ( a ) = − ∑ v = 1 V ∣ D v ∣ ∣ D ∣ log ∣ D v ∣ ∣ D ∣ IV(a)=-\sum_{v=1}^{V}\frac{|D^{v}|}{|D|}\log{\frac{|D^{v}|}{|D|}} IV(a)=−v=1∑V∣D∣∣Dv∣log∣D∣∣Dv∣
称为属性a的固有值(intrinsic value)。属性a的取值数目越多,则 I V ( a ) IV(a) IV(a)的值通常会越大。增益率准则对取值数目较少的属性有所偏好,需要注意的是C4,5并不是直接使用增益率来选择划分属性,而是使用了一个启发式方法:先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
基尼系数
CART决策树使用基尼系数(Gini index)来选择划分属性。数据集的纯度可用基尼值来衡量: G i n i ( D ) = ∑ k = 1 ∣ Y ∣ ∑ k ′ ≠ k p k p k ′ = 1 − ∑ k = 1 ∣ Y ∣ p k 2 Gini(D)=\sum_{k=1}^{|\mathcal Y|}\sum_{k^{'}\neq k}p_{k}p_{k^{'}}=1-\sum_{k=1}^{|\mathcal Y|}p_{k}^{2} Gini(D)=k=1∑∣Y∣k′̸=k∑pkpk′=1−k=1∑∣Y∣pk2
Gini(D)反映了从数据集D中先后随机抽取两个样本,其类别标志不一致的概率。因此Gini(D)越小,数据集D的纯度越高。
选取规则:选择哪个使得划分后基尼系数最小的属性作为最优划分属性,即 a ∗ = arg min a ∈ A G i n i i n d e x ( D , a ) a_{*}=\arg\min_{a\in A} Gini_index(D,a) a∗=argmina∈AGiniindex(D,a)
scikit-learn构建决策树
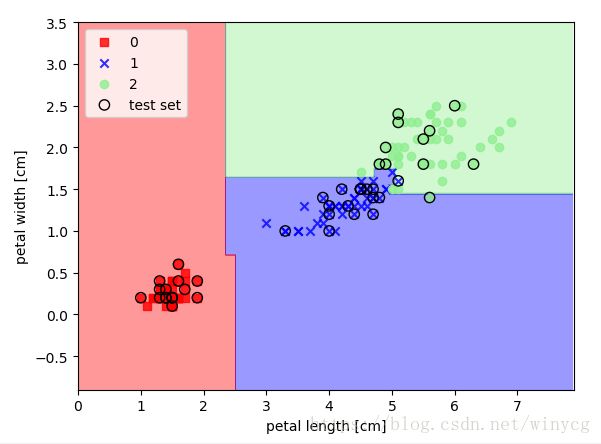
程序中使用熵作为不纯度的标准,构建一棵最大深度为3的决策树。在决策树算法中,特征缩放不是必须的,可以出于可视化的目的。
from sklearn import datasets
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from matplotlib.colors import ListedColormap
import matplotlib.pyplot as plt
def plot_decision_regions(X, y, classifier, test_idx=None, resolution=0.02):
markers = ('s', 'x', 'o', '^', 'v')
colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan')
cmap = ListedColormap(colors[:len(np.unique(y))])
x1_min, x1_max = X[:, 0].min()-1, X[:, 0].max()+1
x2_min, x2_max = X[:, 1].min()-1, X[:, 1].max()+1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution),
np.arange(x2_min, x2_max, resolution))
z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
z = z.reshape(xx1.shape)
plt.contourf(xx1, xx2, z, alpha=0.4, cmap=cmap)
plt.xlim((x1_min, x1_max))
plt.ylim((x2_min, x2_max))
for idx, cl in enumerate(np.unique(y)):
plt.scatter(X[y == cl, 0], X[y == cl, 1],
alpha=0.8, c=cmap(idx),
marker=markers[idx], label=cl)
if test_idx:
plt.scatter(X[test_idx, 0], X[test_idx, 1], c='',
alpha=1.0, linewidth=1, marker='o',
edgecolors='k', s=55, label='test set')
iris = datasets.load_iris()
X =iris.data[:, [2, 3]]
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
tree = DecisionTreeClassifier(criterion='entropy',
max_depth=3,
random_state=0)
tree.fit(X_train, y_train)
X_combined = np.vstack((X_train, X_test))
y_combined = np.hstack((y_train, y_test))
plot_decision_regions(X_combined, y_combined, tree, range(105, 150))
plt.xlabel('petal length [cm]')
plt.ylabel('petal width [cm]')
plt.legend(loc='upper left')
plt.show()

通过dot文件实现决策树的可视化
sklearn可以将决策树导出为.dot格式的文件,使用pydotplus库可以使得dot文件转换为pdf文件。前提是需要安装并配置好graphviz库。
from sklearn.externals.six import StringIO
from sklearn.tree import export_graphviz
import pydotplus
dot_data = StringIO()
export_graphviz(tree,
out_file=dot_data,
feature_names=['petal length', 'petal width'])
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_pdf('tree.pdf')

随机森林(Random Forest)
随机森林可以视为多棵决策树的集合。算法可概括为如下的步骤:
(1)使用bootstrap抽样随机选择 n n n个样本用于训练(从训练集随机重复放回抽样 n n n个样本)
(2)使用(1)选取的样本构造一棵决策树。不重复地随机选取 d d d个特征,并采用最大化信息增益的方式划分节点。
(3)重复上述过程 M M M次,便产生了 M M M棵决策树。对决策树进行多数投票(majority voting)
bootstrap的抽样数量一般与原始训练集中的样本数量相同,这样会在偏差与方差之间得到权衡。sklearn中默认 d = f e a t u r e s _ n u m d=\sqrt{features\_num} d=features_num,其中features_num是特征总量。
from sklearn.ensemble import RandomForestClassifier
forest = RandomForestClassifier(criterion='entropy',
n_estimators=10,
bootstrap=True,
random_state=1)
forest.fit(X_train, y_train)