每天学习一个设计模式(十五):行为型之解释器模式
一、基本概念
解释器模式(Interpreter Pattern)是一种按照规定语法进行解析的方案,在现在项目中使用较少,其定义如下:Given a language, define a representation for its grammar along with an interpreter that uses therepresentation to interpret sentences in the language.(给定一门语言,定义它的文法的一种表示,并定义一个解释器,该解释器使用该表示来解释语言中的句子。)
二、通俗解释
INTERPRETER解释器模式:俺有一个《泡MM真经》,上面有各种泡MM的攻略,比如说去吃西餐的步骤、去看电影的方法等等,跟MM约会时,只要做一个Interpreter,照着上面的脚本执行就可以了。 解释器模式:给定一个语言后,解释器模式可以定义出其文法的一种表示,并同时提供一个解释器。客户端可以使用这个解释器来解释这个语言中的句子。解释器模式将描述怎样在有了一个简单的文法后,使用模式设计解释这些语句。在解释器模式里面提到的语言是指任何解释器对象能够解释的任何组合。在解释器模式中需要定义一个代表文法的命令类的等级结构,也就是一系列的组合规则。每一个命令对象都有一个解释方法,代表对命令对象的解释。命令对象的等级结构中的对象的任何排列组合都是一个语言。
三、解释器模式详解
1.解释器模式通用模版
解释器模式的通用类图如图所示。

●AbstractExpression——抽象解释器
具体的解释任务由各个实现类完成,具体的解释器分别由TerminalExpression和Non-terminalExpression完成。
●TerminalExpression——终结符表达式
实现与文法中的元素相关联的解释操作,通常一个解释器模式中只有一个终结符表达式,但有多个实例,对应不同的终结符。具体到我们例子就是VarExpression类,表达式中的每个终结符都在栈中产生了一个VarExpression对象。
●NonterminalExpression——非终结符表达式
文法中的每条规则对应于一个非终结表达式,具体到我们的例子就是加减法规则分别对应到AddExpression和SubExpression两个类。非终结符表达式根据逻辑的复杂程度而增加,原则上每个文法规则都对应一个非终结符表达式。
●Context——环境角色
具体到我们的例子中是采用HashMap代替。
解释器是一个比较少用的模式,以下为其通用源码,可以作为参考。抽象表达式通常只有一个方法。
public abstract class Expression {
/**
* 每个表达式必须有一个解析任务
* @param c
* @return
*/
public abstract Object interpreter(Context c);
}抽象表达式是生成语法集合(也叫做语法树)的关键,每个语法集合完成指定语法解析任务,它是通过递归调用的方式,最终由最小的语法单元进行解析完成。
public class TerminalExpression extends Expression {
/**
* 通常终结符表达式只有一个,但是有多个对象
* @param c
* @return
*/
@Override
public Object interpreter(Context c) {
return null;
}
}通常,终结符表达式比较简单,主要是处理场景元素和数据的转换。
非终结符表达式代码如下:
public class NonTerminalExpression extends Expression {
/**
* 每个非终结符表达式都会对其他表达式产生依赖
* @param expressions
*/
public NonTerminalExpression(Expression...expressions){
}
@Override
public Object interpreter(Context c) {
//进行文法处理
return null;
}
}每个非终结符表达式都代表了一个文法规则,并且每个文法规则都只关心自己周边的文法规则的结果(注意是结果),因此这就产生了每个非终结符表达式调用自己周边的非终结符表达式,然后最终、最小的文法规则就是终结符表达式,终结符表达式的概念就是如此,不能够再参与比自己更小的文法运算了。客户端类如下:
public class Client {
public static void main(String[] args) {
Context c = new Context();
//通常定义一个语法容器,容纳一个具体的表达式,通常为ArrayList、LinkedList、Stack等类型
Stack stack = null;
for (;;){
//进行语法判断,并产生递归调用
}
//产生一个完整的语法树,由各个具体的语法分析进行解析
Expression e = stack.pop();
//具体元素进入场景
e.interpreter(c);
}
} 这里Client是伪代码,通常Client是一个封装类,封装的结果就是传递进来一个规范语法文件,解析器分析后产生结果并返回,避免了调用者与语法解析器的耦合关系。
2.逻辑运算符的例子
下面就以逻辑运算符的实现为例,讨论解释器模式的结构。系统的结构图如下所示:
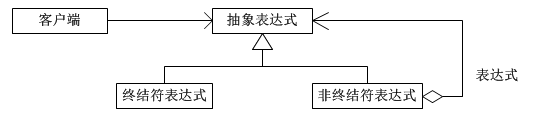
模式所涉及的角色如下所示:
(1)抽象表达式(Expression)角色:声明一个所有的具体表达式角色都需要实现的抽象接口。这个接口主要是一个interpret()方法,称做解释操作。
(2)终结符表达式(Terminal Expression)角色:实现了抽象表达式角色所要求的接口,主要是一个interpret()方法;文法中的每一个终结符都有一个具体终结表达式与之相对应。比如有一个简单的公式R=R1+R2,在里面R1和R2就是终结符,对应的解析R1和R2的解释器就是终结符表达式。
(3)非终结符表达式(Nonterminal Expression)角色:文法中的每一条规则都需要一个具体的非终结符表达式,非终结符表达式一般是文法中的运算符或者其他关键字,比如公式R=R1+R2中,“+"就是非终结符,解析“+”的解释器就是一个非终结符表达式。
(4)环境(Context)角色:这个角色的任务一般是用来存放文法中各个终结符所对应的具体值,比如R=R1+R2,我们给R1赋值100,给R2赋值200。这些信息需要存放到环境角色中,很多情况下我们使用Map来充当环境角色就足够了。
为了说明解释器模式的实现办法,这里给出一个最简单的文法和对应的解释器模式的实现,这就是模拟Java语言中对布尔表达式进行操作和求值。
在这个语言中终结符是布尔变量,也就是常量true和false。非终结符表达式包含运算符and,or和not等布尔表达式。这个简单的文法如下:
Expression ::= Constant | Variable | Or | And | Not
And ::= Expression 'AND' Expression
Or ::= Expression 'OR' Expression
Not ::= 'NOT' Expression
Variable ::= 任何标识符
Constant ::= 'true' | 'false'
解释器模式的结构图如下所示:
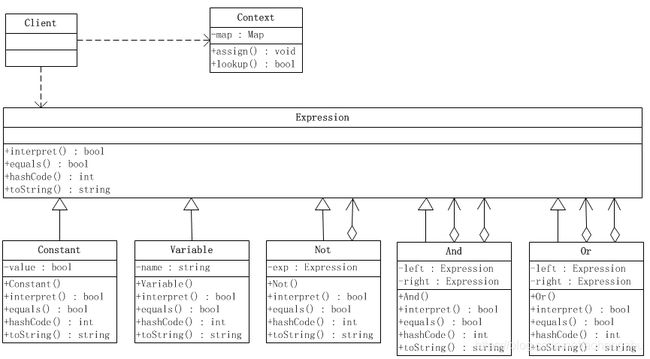
抽象表达式角色
public abstract class Expression {
/**
* 以环境为准,本方法解释给定的任何一个表达式
*/
public abstract boolean interpret(Context ctx);
/**
* 检验两个表达式在结构上是否相同
*/
public abstract boolean equals(Object obj);
/**
* 返回表达式的hash code
*/
public abstract int hashCode();
/**
* 将表达式转换成字符串
*/
public abstract String toString();
}一个Constant对象代表一个布尔常量
public class Constant extends Expression{
private boolean value;
public Constant(boolean value){
this.value = value;
}
@Override
public boolean equals(Object obj) {
if(obj != null && obj instanceof Constant){
return this.value == ((Constant)obj).value;
}
return false;
}
@Override
public int hashCode() {
return this.toString().hashCode();
}
@Override
public boolean interpret(Context ctx) {
return value;
}
@Override
public String toString() {
return new Boolean(value).toString();
}
}一个Variable对象代表一个有名变量
public class Variable extends Expression {
private String name;
public Variable(String name){
this.name = name;
}
@Override
public boolean equals(Object obj) {
if(obj != null && obj instanceof Variable)
{
return this.name.equals(
((Variable)obj).name);
}
return false;
}
@Override
public int hashCode() {
return this.toString().hashCode();
}
@Override
public String toString() {
return name;
}
@Override
public boolean interpret(Context ctx) {
return ctx.lookup(this);
}
}代表逻辑“与”操作的And类,表示由两个布尔表达式通过逻辑“与”操作给出一个新的布尔表达式的操作
public class And extends Expression {
private Expression left,right;
public And(Expression left , Expression right){
this.left = left;
this.right = right;
}
@Override
public boolean equals(Object obj) {
if(obj != null && obj instanceof And)
{
return left.equals(((And)obj).left) &&
right.equals(((And)obj).right);
}
return false;
}
@Override
public int hashCode() {
return this.toString().hashCode();
}
@Override
public boolean interpret(Context ctx) {
return left.interpret(ctx) && right.interpret(ctx);
}
@Override
public String toString() {
return "(" + left.toString() + " AND " + right.toString() + ")";
}
}代表逻辑“或”操作的Or类,代表由两个布尔表达式通过逻辑“或”操作给出一个新的布尔表达式的操作
public class Or extends Expression {
private Expression left,right;
public Or(Expression left , Expression right){
this.left = left;
this.right = right;
}
@Override
public boolean equals(Object obj) {
if(obj != null && obj instanceof Or)
{
return this.left.equals(((Or)obj).left) && this.right.equals(((Or)obj).right);
}
return false;
}
@Override
public int hashCode() {
return this.toString().hashCode();
}
@Override
public boolean interpret(Context ctx) {
return left.interpret(ctx) || right.interpret(ctx);
}
@Override
public String toString() {
return "(" + left.toString() + " OR " + right.toString() + ")";
}
}代表逻辑“非”操作的Not类,代表由一个布尔表达式通过逻辑“非”操作给出一个新的布尔表达式的操作
public class Not extends Expression {
private Expression exp;
public Not(Expression exp){
this.exp = exp;
}
@Override
public boolean equals(Object obj) {
if(obj != null && obj instanceof Not)
{
return exp.equals(
((Not)obj).exp);
}
return false;
}
@Override
public int hashCode() {
return this.toString().hashCode();
}
@Override
public boolean interpret(Context ctx) {
return !exp.interpret(ctx);
}
@Override
public String toString() {
return "(Not " + exp.toString() + ")";
}
}环境(Context)类定义出从变量到布尔值的一个映射
public class Context {
private Map map = new HashMap();
public void assign(Variable var , boolean value){
map.put(var, new Boolean(value));
}
public boolean lookup(Variable var) throws IllegalArgumentException{
Boolean value = map.get(var);
if(value == null){
throw new IllegalArgumentException();
}
return value.booleanValue();
}
} 客户端类
public class Client {
public static void main(String[] args) {
Context ctx = new Context();
Variable x = new Variable("x");
Variable y = new Variable("y");
Constant c = new Constant(true);
ctx.assign(x, false);
ctx.assign(y, true);
Expression exp = new Or(new And(c,x) , new And(y,new Not(x)));
System.out.println("x=" + x.interpret(ctx));
System.out.println("y=" + y.interpret(ctx));
System.out.println(exp.toString() + "=" + exp.interpret(ctx));
}
}运行结果如下:

3.解释器模式的优缺点
解释器模式的优点
解释器是一个简单语法分析工具,它最显著的优点就是扩展性,修改语法规则只要修改相应的非终结符表达式就可以了,若扩展语法,则只要增加非终结符类就可以了。
解释器模式的缺点
● 解释器模式会引起类膨胀
每个语法都要产生一个非终结符表达式,语法规则比较复杂时,就可能产生大量的类文件,为维护带来了非常多的麻烦。
● 解释器模式采用递归调用方法
每个非终结符表达式只关心与自己有关的表达式,每个表达式需要知道最终的结果,必须一层一层地剥茧,无论是面向过程的语言还是面向对象的语言,递归都是在必要条件下使用的,它导致调试非常复杂。想想看,如果要排查一个语法错误,我们是不是要一个断点一个断点地调试下去,直到最小的语法单元。
● 效率问题
解释器模式由于使用了大量的循环和递归,效率是一个不容忽视的问题,特别是一用于解析复杂、冗长的语法时,效率是难以忍受的。
4.解释器模式的应用场景及最佳实践
应用场景
●重复发生的问题可以使用解释器模式
例如,多个应用服务器,每天产生大量的日志,需要对日志文件进行分析处理,由于各个服务器的日志格式不同,但是数据要素是相同的,按照解释器的说法就是终结符表达式都是相同的,但是非终结符表达式就需要制定了。在这种情况下,可以通过程序来一劳永逸地解决该问题。
●一个简单语法需要解释的场景
为什么是简单?看看非终结表达式,文法规则越多,复杂度越高,而且类间还要进行递归调用(看看我们例子中的栈)。想想看,多个类之间的调用你需要什么样的耐心和信心去排查问题。因此,解释器模式一般用来解析比较标准的字符集,例如SQL语法分析,不过该部分逐渐被专用工具所取代。
在某些特用的商业环境下也会采用解释器模式,我们刚刚的例子就是一个商业环境,而且现在模型运算的例子非常多,目前很多商业机构已经能够提供出大量的数据进行分析。
注意 尽量不要在重要的模块中使用解释器模式,否则维护会是一个很大的问题。在项目中可以使用shell、JRuby、Groovy等脚本语言来代替解释器模式,弥补Java编译型语言的不足。我们在一个银行的分析型项目中就采用JRuby进行运算处理,避免使用解释器模式的四则运算,效率和性能各方面表现良好。
最佳实践
解释器模式在实际的系统开发中使用得非常少,因为它会引起效率、性能以及维护等问题,一般在大中型的框架型项目能够找到它的身影,如一些数据分析工具、报表设计工具、科学计算工具等,若你确实遇到“一种特定类型的问题发生的频率足够高”的情况,准备使用解释器模式时,可以考虑一下Expression4J、MESP(MathExpression String Parser)、Jep等开源的解析工具包(这三个开源产品都可以通过百度、Google搜索到,请读者自行查询),功能都异常强大,而且非常容易使用,效率也还不错,实现大多数的数学运算完全没有问题,自己没有必要从头开始编写解释器。有人已经建立了一条康庄大道,何必再走自己的泥泞小路呢?
参考秦小波的《设计模式之禅(第2版)》