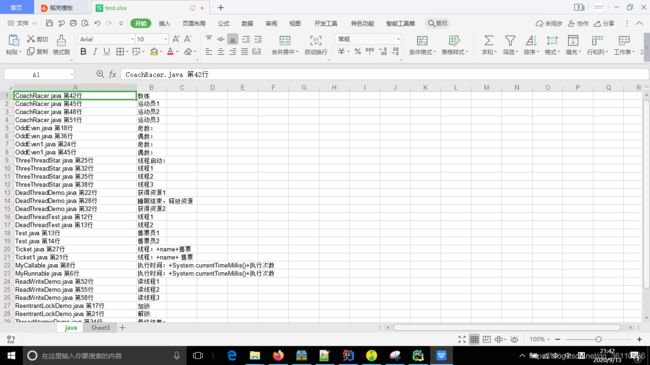
python脚本自动提取Java中的中文并写入excel表格中
中文提取
import re
import os
import xlwt
import xlrd
import xlsxwriter
import numpy as np
import xlutils.copy
def findChineseCharacter(path,file_name) :
#匹配中文
pattern = re.compile(r"^\"[\u4e00-\u9fa5]+\".+\"|\"[\u4e00-\u9fa5]+.*[\u4e00-\u9fa5]+.*\"")
#返回结果
result = []
#异常处理
try:
file = open(path, encoding="UTF-8")
except FileNotFoundError:
print("============")
strfile=file.read()
#遍历字符串,一次处理一行
i = 0
for line in strfile.splitlines():
i += 1 #记录中文行号
rel111 = pattern.findall(line)
if not len(rel111) is 0:
result_line = []
result_line.append(rel111)
result_line.append(i)
result.append(result_line)
file.close()
return result
def write(datas, java_name,path):
wb = xlrd.open_workbook(path)#打开工作簿
ws = xlutils.copy.copy(wb) #复制之前表里存在的数据
table = ws.get_sheet("java")#根据sheet_name获取工作表
nownrows = readline(path)
for i in range(len(datas)):
'''通过索引取出对应的信息'''
row_content = datas[i]
print(row_content)
row_content = str(row_content[0])
row_content = row_content.replace("[", "")#组织字符串格式
row_content = row_content.replace("]", "")
row_content = row_content.replace("\'", "")
row_content = row_content.replace("\"", "")
table.write(nownrows+i, 0, java_name+" 第"+str(datas[i][1])+"行")#写入目标xlsx
table.write(nownrows+i, 1, row_content)
ws.save(path) #保存的有旧数据和新数据
def readline(path):
wb = xlrd.open_workbook(path) #打开excel,保留文件格式
sheet1 = wb.sheet_by_name("java")
nrows = sheet1.nrows #获取总行数
return nrows
def file_name(file_dir):
for root, dirs, files in os.walk(file_dir):
for file in files:
if file.endswith(".java"):#判断是否为Java文件
result = findChineseCharacter(os.path.join(root, file), file)
result2 = []
result3 = []
for i in result:
if i[0] not in result2:
result2.append(i[0])
result3.append(i)
write(result3, str(file), xlsx_path)
print(result3, str(file))
xlsx_path = r"test.xlsx"
project_path =r"Multithread"
file_name(project_path)
运行结果: