MySQL入门级教程
MySQL基础(先有数据库,再有表,最后是数据)
1.1 操作数据库
-- 增加数据库
CREATE DATABASE day01;
-- 增加数据库并设置默认字符集
CREATE DATABASE day011 DEFAULT CHARACTER SET gbk;
-- 删除数据库
DROP DATABASE day011;
-- 修改数据库(一般都是修改字符集)
ALTER DATABASE day011 DEFAULT CHARACTER SET utf8;
-- 查询数据库
SHOW DATABASES;
-- 查询数据库的默认字符集
SHOW CREATE DATABASE day01;
1.2 操作数据库的表
增加: create table 表(字段名1 字段类型,字段名2 字段类型......);
删除: drop table 表;
修改:
添加字段: alter table 表 add [column] 字段名 字段类型;
删除字段: alter table 表 drop [column] 字段名;
修改字段类型: alter table 表 modify 字段名 新的字段类型;
修改字段名称 : alter table 表 change 旧字段名 新字段名 字段类型;
修改表名称: alter table 表 rename [to] 新表名;
查询:
show tables / desc student;
-- 一定要先指定使用的数据库
USE day01;
-- 创建数据库的表
CREATE TABLE student(
sid INT,
sname VARCHAR(20),
sage INT
);
-- 删除数据库的表
DROP TABLE student;
-- 修改数据库的表(column都可不加)
-- 1)添加字段
ALTER TABLE student ADD COLUMN sgender VARCHAR(11);
-- 2)删除字段
ALTER TABLE student DROP COLUMN sgender;
-- 3)修改字段类型
ALTER TABLE student MODIFY COLUMN sgender VARCHAR(10);
-- 4)修改字段名称
ALTER TABLE student CHANGE COLUMN sgender newGender VARCHAR(10);
-- 5)修改表名称(to可以省略)
ALTER TABLE student RENAME TO newStudent;
-- 查询数据库的所有表
SHOW TABLES;
-- 查询数据库的单个表结构
DESC student;
1.3 操作数据库表中的数据
-- 增加表中的数据
INSERT INTO student VALUES (1,'张三',18);
-- 带条件的添加表中的数据
INSERT INTO student(sid,sname) VALUES (2,'李四');
-- 删除表中的数据(不推荐使用,直接删除整个表的数据)
DELETE FROM student;
-- 带条件的删除表中的数据(推荐使用)
DELETE FROM student WHERE sage IS NULL;
DELETE FROM student WHERE sage IS NULL OR sage=18;
-- 修改表中的数据
UPDATE student SET sage=18;
-- 带条件的修改表中的数据
UPDATE student SET sage=20 WHERE sid=2;
UPDATE student SET sage=20,sname='王五',sid=3 WHERE sid=2;
先创建如下图所示的表:
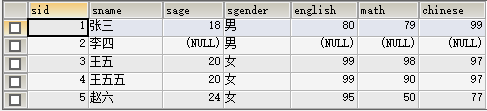
重点掌握查询
-- 查询表中的数据
-- 1.查询所有列
SELECT * FROM student;
-- 2.查询指定列
SELECT sid,sname,sgender FROM student;
-- 3.查询时添加常量列、添加别称
SELECT *,'汉族' AS '民族' FROM student;
-- 4.查询时去除重复记录
SELECT DISTINCT sgender FROM student;
-- 另一种写法
SELECT DISTINCT(sgender) FROM student;
-- 5.查询时合并列
SELECT sid,sname,(english+math+chinese) AS 'sum' FROM student;
-- 6.条件查询
-- 6.1 逻辑条件 与(and) 或(or)
-- 6.2 比较条件 < > <= >= <>(不等于) between and
SELECT * FROM student WHERE english BETWEEN 75 AND 90;
SELECT * FROM student WHERE english>=75 AND english<=90;
-- 6.3 判空条件 is null / is not null / =''/ <>''
SELECT * FROM student WHERE english IS NOT NULL OR english <>'';
-- 6.4 模糊条件 like
-- %:表示任意个字符
-- _:表示单个字符
SELECT * FROM student WHERE sname LIKE '王%';
SELECT * FROM student WHERE sname LIKE '王__'
-- 7.聚合查询(使用聚合函数的查询)
-- 常见的聚合函数:sum()/avg()/max()/min()/count()
SELECT SUM(english) AS 'sumOfEnglish' FROM student;
SELECT AVG(math) AS 'mathOfAvg' FROM student;
SELECT MAX(math) AS 'mathOfMax' FROM student;
SELECT COUNT(*) FROM student;
SELECT COUNT(sid) FROM student;
-- count()函数统计的数量不包含null的数据
SELECT COUNT(chinese) FROM student;
-- 8.分页查询
-- 分页查询当前页的数据:select * from student limit (当前页-1)*每页显示多少条,每页显示多少条
SELECT * FROM student LIMIT 0,3;
SELECT * FROM student LIMIT 3,3;
-- 9.查询排序
-- 语法:order by 字段 asc(正序)/desc(倒序)
SELECT * FROM student ORDER BY sage DESC;
SELECT * FROM student ORDER BY english ASC,math DESC;
-- 10.分组排序
SELECT sgender,COUNT(sid) FROM student GROUP BY sgender;
-- 11.分组排序后筛选
-- 分组之前的条件使用where关键字,分组之后的条件使用having关键字
SELECT sgender,COUNT(*) FROM student GROUP BY sgender HAVING COUNT(*)>2;
2.MySQL进阶-- 数据约束
2.1 默认值(DEFAULT) -->> 可以对默认值字段插入null
-- 先创建新的数据库和表
CREATE DATABASE day02 DEFAULT CHARACTER SET utf8;
USE day02;
-- 默认值
CREATE TABLE teacher(
id INT,
NAME VARCHAR(20) DEFAULT '默认名字'
);
INSERT INTO teacher(id) VALUES(1);
INSERT INTO teacher VALUES(2,NULL);
效果图
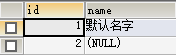
2.2 非空(NOT NULL) -->>非空字符必须赋值且不能赋null
DROP TABLE teacher;
-- 非空
CREATE TABLE teacher(
id INT NOT NULL,
NAME VARCHAR(20)
);
-- 错误
-- insert into teacher(name) values('张三');
-- INSERT INTO teacher VALUES(null,'王五');
2.3 唯一(UNIQUE)–>> 唯一字段可以插入null且可以插入多个null
DROP TABLE teacher;
-- 唯一
CREATE TABLE teacher(
id INT UNIQUE,
NAME VARCHAR(20)
);
INSERT INTO teacher VALUES(1,'张三');
INSERT INTO teacher VALUES(1,'李四'); -- Duplicate entry '1' for key 'id'
-- 下面两个的id都是Null
INSERT INTO teacher(NAME) VALUES('王五');
INSERT INTO teacher(NAME) VALUES('赵六');
2.4 主键(PRIMARY_KEY) -->>非空+唯一
注意:
1)通常情况下,每张表都会设置一个主键字段。用于标记表中的每条记录的唯一性。
2)建议不要选择表的包含业务含义的字段作为主键,建议给每张表独立设计一个非业务含义的 id字段。
2.5 自增长(AUTO_INCREMENT)
DROP TABLE teacher;
-- 自增长
CREATE TABLE teacher(
id INT(4) ZEROFILL PRIMARY KEY AUTO_INCREMENT, -- int(4) zerofill 自动填充至4位
NAME VARCHAR(20)
);
INSERT INTO teacher(NAME) VALUES('张三');
INSERT INTO teacher(NAME) VALUES('李四');
INSERT INTO teacher(NAME) VALUES('王五');
效果图:
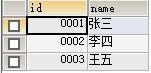
– 不能影响自增长约束
DELETE FROM student;
– 可以影响自增长约束
TRUNCATE TABLE student;
2.6 外键约束
为什么使用外键?
解决数据冗余高的问题(给冗余的字段放到一张独立表中),然后再用外键关联这两张表。
例如: 员工表 和 部门表
问题出现:在插入员工表数据的时候,员工表的部门ID字段可以随便插入,即使没有该部门ID字段(一个部门ID字段对应一个部门)。
解决方法:使用外键约束:约束插入员工表的部门ID字段值
CREATE TABLE employee(
id INT PRIMARY KEY,
NAME VARCHAR(20),
deptName VARCHAR(20)
);
INSERT INTO employee VALUES(1,'张三','秘书部');
INSERT INTO employee VALUES(2,'李四','软件开发部');
INSERT INTO employee VALUES(3,'王五','应用维护部');
-- 添加员工,当数据量很大或者部门名称比较长时,可看出部门名称的数据冗余高
INSERT INTO employee VALUES(4,'赵六','秘书部');
-- 解决数据冗余高的问题:给冗余的字段放到一张独立表中
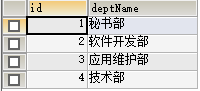
CREATE TABLE dept(
id INT PRIMARY KEY,
deptName VARCHAR(20)
);
INSERT INTO dept VALUES(1,'秘书部');
INSERT INTO dept VALUES(2,'软件开发部');
INSERT INTO dept VALUES(3,'应用维护部');
-- 修改employee表
DROP TABLE employee;
CREATE TABLE employee(
id INT,
NAME VARCHAR(20),
deptID INT
);
INSERT INTO employee VALUES(1,'张三',1);
INSERT INTO employee VALUES(2,'李四',2);
INSERT INTO employee VALUES(3,'王五',3);
INSERT INTO employee VALUES(4,'赵六',1);
-- insert into employee values(5,'赵六',4); -- 该记录业务上不合法,员工插入了一个不存在的部门数据,但是却可以加入,因为没有条件约束。
-- 声明一个外键约束
CREATE TABLE employee(
id INT,
NAME VARCHAR(20),
deptID INT,
-- CONSTRAINT(约束) FOREIGN KEY(外键) REFERENCES(参考)
-- employee(副表,被约束的表) dept(主表,约束别人的表)
-- 译为:约束副表的外键(deptID)参考主表的(id)
CONSTRAINT employee_dept_fk FOREIGN KEY(deptID) REFERENCES dept(id)
);
-- 声明外键约束后,直接报错。
INSERT INTO employee VALUES(5,'赵六',4); -- Cannot add or update a child row: a foreign key constraint fails (`day02`.`employee`, CONSTRAINT `employee_dept_fk` FOREIGN KEY (`deptID`) REFERENCES `dept` (`id`))
– 1)当有了外键约束,添加数据的顺序: 先添加主表,再添加副表数据
– 2)当有了外键约束,修改数据的顺序: 先修改副表,再修改主表数据
– 3)当有了外键约束,删除数据的顺序: 先删除副表,再删除主表数据
2.7 级联操作
问题: 当有了外键约束的时候,必须先修改或删除副表中的所有关联数据,才能修改或删除主表!但是,我们希望直接修改或删除主表数据,从而影响副表数据。可以使用级联操作实现。
级联修改: ON UPDATE CASCADE
级联删除: ON DELETE CASCADE
-- 关键代码,其他自行测试
CREATE TABLE employee(
id INT,
NAME VARCHAR(20),
deptID INT,
CONSTRAINT employee_dept_fk FOREIGN KEY(deptID) REFERENCES dept(id) ON UPDATE CASCADE ON DELETE CASCADE
);
3. 数据库设计
3.1关联查询(多表查询)
– 多表查询规则:1)确定查询哪些表 2)确定查询哪些字段 3)表与表之间连接条件 (规律:连接条件数量是表数量-1)
先创建两张表,代码如下:
CREATE TABLE dept(
id INT PRIMARY KEY,
deptName VARCHAR(20)
);
INSERT INTO dept VALUES(1,'秘书部');
INSERT INTO dept VALUES(2,'软件开发部');
INSERT INTO dept VALUES(3,'应用维护部');
INSERT INTO dept VALUES(4,'技术部');
CREATE TABLE employee(
id INT PRIMARY KEY,
NAME VARCHAR(20),
deptID INT,
CONSTRAINT employee_dept_fk FOREIGN KEY(deptID) REFERENCES dept(id)
);
INSERT INTO employee VALUES(1,'张三',1);
INSERT INTO employee VALUES(2,'李四',2);
INSERT INTO employee VALUES(3,'王五',3);
INSERT INTO employee VALUES(4,'赵六',1);

3.1.1 内连接查询:只有满足条件的结果才会显示(使用最频繁)
– 需求:查询员工及其所在部门(显示员工姓名,部门名称)
SELECT NAME,deptName -- 2)确定查询哪些字段
FROM employee,dept -- 1)确定查询哪张表
WHERE employee.deptID=dept.id; -- 3)表与表之间的连接关系
-- 内连接的另一种写法:
SELECT NAME,deptName
FROM employee
INNER JOIN dept
ON employee.deptID=dept.id;
-- 使用别名的写法(as可以省略)
SELECT NAME,deptName
FROM employee AS e
INNER JOIN dept AS d
ON e.deptID=d.id;
效果图:

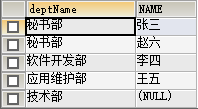
3.1.2 左外连接查询
-- 左【外】连接查询: 使用左边表的数据去匹配右边表的数据,如果符合连接条件的结果则显示,如果不符合连接条件则显示null
SELECT deptName,NAME
FROM dept
LEFT OUTER JOIN employee
ON dept.id=employee.deptID;
效果图:
3.1.3 右外连接查询
-- 右[外]连接查询: 使用右边表的数据去匹配左边表的数据,如果符合连接条件的结果则显示,如果不符合连接条件则显示null
SELECT d.deptName,e.name
FROM employee AS e
RIGHT OUTER JOIN dept AS d
ON e.deptID=d.id;
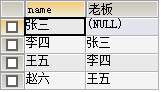
3.1.4 自连接查询
-- 自连接查询
CREATE TABLE person(
id INT PRIMARY KEY,
NAME VARCHAR(20),
bosID INT
);
INSERT INTO person(id,NAME) VALUES(1,'张三');
INSERT INTO person VALUES(2,'李四',1);
INSERT INTO person VALUES(3,'王五',2);
INSERT INTO person VALUES(4,'赵六',3);
SELECT py.name,pl.name AS '老板'
FROM person py
LEFT OUTER JOIN person pl
ON py.bosID=pl.id;
效果图:
3.2 三大范式
设计原则: 建议设计的表尽量遵守三大范式。
第一范式: 要求表的每个字段必须是不可分割的独立单元
student : name -- 违反第一范式
张小名|狗娃
sutdent : name old_name --符合第一范式
张小名 狗娃
第二范式: 在第一范式的基础上,要求每张表只表达一个意思。表的每个字段都和表的主键有依赖。
employee(员工): 员工编号 员工姓名 部门名称 订单名称 --违反第二范式
员工表:员工编号 员工姓名 部门名称
订单表: 订单编号 订单名称 -- 符合第二范式
第三范式: 在第二范式基础,要求每张表的主键之外的其他字段都只能和主键有直接决定依赖关系。
员工表: 员工编号(主键) 员工姓名 部门编号 部门名 --符合第二范式,违反第三范式 (数据冗余高)
员工表:员工编号(主键) 员工姓名 部门编号 --符合第三范式(降低数据冗余)
部门表:部门编号 部门名
4.存储过程
4.1 什么是存储过程
存储过程,带有逻辑的sql语句。之前的sql没有条件判断,没有循环。
4.2 存储过程特点
1)执行效率非常快!存储过程是在数据库的服务器端执行的!!!
2)移植性很差!不同数据库的存储过程是不能移植。
4.3 存储过程语法
-- 创建存储过程
DELIMITER $ -- 声明存储过程的结束符
CREATE PROCEDURE pro_test() -- 存储过程名称(参数列表)
BEGIN -- 开始
-- 可以写多个sql语句; -- sql语句+流程控制
SELECT * FROM employee;
END $ -- 结束 结束符
-- 执行存储过程
CALL pro_test(); -- CALL 存储过程名称(参数);
-- 参数列表:
-- IN: 表示输入参数,可以携带数据到存储过程中
-- OUT: 表示输出参数,可以从存储过程中返回结果
-- INOUT: 表示输入输出参数,既有输入功能,又有输出功能
4.3.1 带有输入参数的存储过程
-- 带有输入参数的存储过程
DELIMITER $
CREATE PROCEDURE pro_in(IN idIN INT)
BEGIN
SELECT * FROM employee WHERE id=idIN;
END $
CALL pro_in(3);
4.3.2 带有输出参数的存储过程
********************************* mysql的变量 *********************************
全局变量(内置变量):mysql数据库内置的变量 (所有连接都起作用)
– 查看所有全局变量: show variables
– 查看某个全局变量: select @@变量名
– 修改全局变量: set 变量名=新值
– character_set_client: mysql服务器的接收数据的编码
– character_set_results:mysql服务器输出数据的编码
会话变量: 只存在于当前客户端与数据库服务器端的一次连接当中。如果连接断开,那么会话变量全部丢失!
– 定义会话变量: set @变量=值
– 查看会话变量: select @变量
局部变量: 在存储过程中使用的变量就叫局部变量。只要存储过程执行完毕,局部变量就丢失!!
-- 带有输出参数的存储过程
DELIMITER $
CREATE PROCEDURE pro_out(OUT str VARCHAR(20))
BEGIN
-- 给参数赋值
SET str='helloworld';
END $
-- 调用pro_out()方法,声明一个变量接收。但是如何接受返回参数的值??
-- 1)定义一个会话变量name, 2)使用name会话变量接收存储过程的返回值
CALL pro_out(@NAME);
-- 查看变量值
SELECT @NAME AS '接收到的数据';
4.3.3 带有输入输出参数的存储过程
-- 带有输入输出参数的存储过程
DELIMITER $
CREATE PROCEDURE pro_inout(INOUT n INT)
BEGIN
-- 这里的变量变成了局部变量
SELECT n AS '结果';
SET n=100;
END $
-- CALL_pro_inout(10) --错误 OUT or INOUT argument 1 for routine day02.pro_inout is not a variable or NEW pseudo-variable in BEFORE trigger
-- 这里设置一个会话变量
SET @n = 10;
CALL pro_inout(@n);
SELECT @n AS '新结果';
4.3.4 带有条件判断的存储过程
需求:输入一个整数,如果1,则返回“星期一”,如果2,返回“星期二”,如果3,返回“星期三”。其他数字,返回“错误输入”;
DELIMITER $
CREATE PROCEDURE pro_testIf(IN num INT,OUT str VARCHAR(20))
BEGIN
IF num=1 THEN
SET str='星期一';
ELSEIF num=2 THEN
SET str='星期二';
ELSEIF num=3 THEN
SET str='星期三';
ELSE
SET str='输入错误';
END IF;
END $
CALL pro_testIf(4,@str);
SELECT @str;
4.3.5 带有循环功能的存储过程
需求: 输入一个整数,求和。例如,输入100,统计1-100的和
DELIMITER $
CREATE PROCEDURE pro_while(IN num INT,OUT result INT)
BEGIN
DECLARE i INT DEFAULT 1;
DECLARE sumNum INT DEFAULT 0;
WHILE i<=num DO
SET sumNum = sumNum+i;
SET i=i+1;
END WHILE;
SET result = sumNum;
END $
CALL pro_while(100,@result);
SELECT @result AS '总和';
4.3.6 使用查询的结果赋值给变量
-- 使用查询的结果赋值给变量
DELIMITER $
CREATE PROCEDURE pro_into(IN idIN INT,OUT result VARCHAR(20))
BEGIN
SELECT deptName INTO result FROM dept WHERE idIN=id;
END $
CALL pro_into(2,@result);
SELECT @result AS '查询结果';
5. 触发器
当操作了某张表时,希望同时触发一些动作/行为,可以使用触发器完成!!
例如: 当向员工表插入一条记录时,希望同时往日志表插入数据。
-- 首先创建一张日志表
CREATE TABLE log_table(
id INT PRIMARY KEY AUTO_INCREMENT,
LOGS VARCHAR(20)
)
-- 需求: 当向员工表插入一条记录时,希望mysql自动同时往日志表插入数据
CREATE TRIGGER tri_empAdd AFTER INSERT ON employee FOR EACH ROW
INSERT INTO log_table(LOGS) VALUES('插入一条记录');
INSERT INTO employee VALUES(5,'张三三',2);
-- 需求: 当向员工表修改一条记录时,希望mysql自动同时往日志表插入数据
CREATE TRIGGER tri_empUpdate AFTER UPDATE ON employee FOR EACH ROW
INSERT INTO log_table(LOGS) VALUES('更新一条记录');
UPDATE employee SET deptID=3 WHERE id=5;
-- 需求: 当向员工表删除一条记录时,希望mysql自动同时往日志表插入数据
CREATE TRIGGER tri_empDelete AFTER DELETE ON employee FOR EACH ROW
INSERT INTO log_table(LOGS) VALUES('删除一条记录');
DELETE FROM employee WHERE id=5;