avro数据序列化/反序列化
序列化:把数据加工成特定的格式
反序列化:把特定格式的数据解析成对象
Avro提供了两种序列化和反序列化的方式:一种是通过Schema文件来生成代码的方式,一种是不生成代码的通用方式,这两种方式都需要构建Schema文件。
Avro在序列化时可以通过指定编码器,将数据序列化成标准的JSON格式,也可以序列化成二进制格式。
Avro支持两种序列化编码方式:二进制编码和JSON编码,使用二进制编码会高效序列化,并且序列化后得到的结果会比较小。而JSON一般用于调试系统或是基于WEB的应用。对Avro数据序列化/反序列化时都需要对模式以深度优先(Depth-First),从左到右(Left-to-Right)的遍历顺序来执行。
下面通过具体的例子来进行演示:
项目框架
创建一个Maven项目:
- 在pom.xml文件中添加依赖:
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.12version>
<scope>testscope>
dependency>
<dependency>
<groupId>org.apache.avrogroupId>
<artifactId>avroartifactId>
<version>1.9.1version>
dependency>
- 在pom.xml文件中配置插件:
<plugins>
<plugin>
<groupId>org.apache.avrogroupId>
<artifactId>avro-maven-pluginartifactId>
<version>1.9.1version>
<executions>
<execution>
<phase>generate-sourcesphase>
<goals>
<goal>schemagoal>
goals>
<configuration>
<sourceDirectory>${project.basedir}/src/main/resources/sourceDirectory>
<outputDirectory>${project.basedir}/src/main/java/outputDirectory>
configuration>
execution>
executions>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<configuration>
<encoding>utf-8encoding>
<source>1.8source>
<target>1.8target>
configuration>
plugin>
plugins>
- 在resources目录下定义模式文件dept.avsc
{
"namespace":"com.hc.bean",
"type":"record",
"name":"Dept",
"fields":[
{
"name":"deptno","type":"int"},
{
"name":"dname","type":"string"},
{
"name":"loc","type":"string"}
]
}
使用生成的代码(类)进行序列化和反序列化
第一步:根据schema自动生成对应的Dept类
首先下载avro-tools-1.9.1.jar文件将该文件连同dept.avsc放到同一个目录下,然后执行下面命令:
java -jar avro-tools-1.9.1.jar compile schema dept.avsc java.

注意:最后面的**java.**指的是生成的avro文件存放在当前目录下的java文件夹下,点表示当前路径。
最终在当前目录生成java/com/hc/bean目录下有个Dept.java文件。将该java文件和avsc文件一起拷贝到Intellij项目目录下面:
注:在Intellij中,也可以采用图形化的方式生成Java代码:
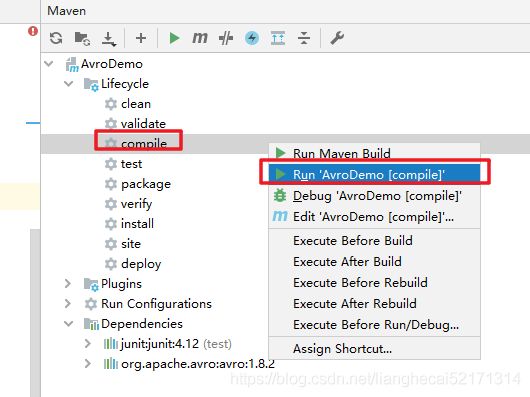
当然,也可以采用命令行的方式:
mvn clean install -DskipTests=true

不过使用mvn clean install -DskipTests=true命令时,需要添加下面Jackson注解,否则程序报错。
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.10.1</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.10.1</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-annotations</artifactId>
<version>2.10.1</version>
</dependency>
第二步:使用Avro生成的代码创建Dept对象:
可以使用有参的构造函数和无参的构造函数,也可以使用Builder构造Dept对象:
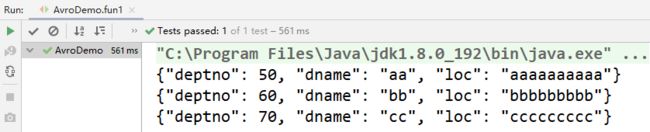
@Test
public void genBean(){
Dept dept1 = new Dept();
dept1.setDeptno(50);
dept1.setDname("aa");
dept1.setLoc("aaaaaaaaaa");
System.out.println(dept1);
Dept dept2 = new Dept(60, "bb", "bbbbbbbbb");
System.out.println(dept2);
Dept dept3 = Dept.newBuilder()
.setDeptno(70)
.setDname("cc")
.setLoc("ccccccccc")
.build();
System.out.println(dept3);
}
结果:
第三步:序列化:
@Test
public void serialize() throws IOException {
Dept dept = new Dept(60, "bb", "bbbbbbbbb");
DatumWriter<Dept> datumWriter = new SpecificDatumWriter<>(Dept.class); //缓存
DataFileWriter<Dept> dataFileWriter = new DataFileWriter< >(datumWriter);
dataFileWriter.create(dept.getSchema(), new File("dept.avro")); //将数据序列化到指定的文件中
dataFileWriter.append(dept); //可以追加多个对象
dataFileWriter.close();
}
上面代码中:DatumWrite接口用来把java对象转换成内存中的序列化格式,SpecificDatumWriter用来生成类并且指定生成的类型。最后使用DataFileWriter来进行具体的序列化,create方法指定目标文件和schema信息,append方法用来写数据,最后写完后close文件。
运行程序,结果:在当前目录生成一个名为dept.avro的二进制文件。
第四步:反序列化:
反序列化跟序列化很像,相应的Writer换成Reader。
@Test
public void deSerialize() throws IOException {
File file = new File("dept.avro");
DatumReader<Dept> datumReader = new SpecificDatumReader< >(Dept.class);
DataFileReader<Dept> dataFileReader = new DataFileReader< >(file, datumReader);
for(Dept dept : dataFileReader){
//通过迭代的方式一条条读取出来
System.out.println(dept);
}
}
上面代码只创建一个Dept对象,是为了性能优化,每次都重用这个Dept对象,如果文件量很大,对象分配和垃圾收集处理的代价很昂贵。最后使用 for (Dept dept: dataFileReader) 循环遍历对象
程序运行结果:
不使用生成的代码(类)进行序列化和反序列化(通用方式)
虽然Avro为我们提供了根据schema自动生成类的方法,我们也可以自己创建类,不使用Avro的自动生成工具。
第一步:创建Dept对象:
@Test
public void fun4() throws IOException {
Schema schema = new Schema.Parser().parse(new File("src/main/resources/dept.avsc"));//通过流的方式将Schema信息构建出来
GenericData.Record dept = new GenericData.Record(schema);
dept.put("deptno","80");
dept.put("dname","dd");
dept.put("loc","ddddddddddd");
System.out.println(dept);
}
上面代码首先使用Parser读取schema信息并且创建Schema类,有了Schema之后可以创建具体的Dept对象了。上面代码使用GenericRecord表示Dept,GenericRecord会根据schema验证字段是否正确,如果put进了不存在的字段 dept.put(“deptno”, “80”) ,那么运行的时候会得到AvroRuntimeException异常。
上面代码构建Schema也可以:
InputStream is = Thread.currentThread().getContextClassLoader().getResourceAsSteam("dept.avsc");
Schema schema = new Schema.Parser().parse(is);
第二步:通用序列化:
@Test
public void serialize() throws IOException {
Schema schema = new Schema.Parser().parse(new File("src/main/resources/dept.avsc"));
GenericRecord dept = new GenericData.Record(schema);
dept.put("deptno", 90);
dept.put("dname", "ee");
dept.put("loc", "eeeeeeeee");
DatumWriter<GenericRecord> datumWriter = new SpecificDatumWriter<>(schema); //泛型参数为GenericRecord
DataFileWriter<GenericRecord> dataFileWriter = new DataFileWriter<>(datumWriter);
dataFileWriter.create(schema, new File("dept.avro"));
dataFileWriter.append(dept);
dataFileWriter.close();
}
第三步:通用反序列化:
@Test
public void deSerialize() throws IOException {
Schema schema = new Schema.Parser().parse(new File("src/main/resources/dept.avsc"));
File file = new File("dept.avro");
DatumReader<GenericRecord> datumReader = new SpecificDatumReader<GenericRecord>(schema);
DataFileReader<GenericRecord> dataFileReader = new DataFileReader<GenericRecord>(file, datumReader);
GenericRecord dept = null;
while(dataFileReader.hasNext()) {
dept = dataFileReader.next(dept );
System.out.println(dept );
}
}
执行程序,结果:

示例:基于通用序列化反序列化演示模式转换(数据投影):
原理:序列化的模式文件和反序列化的模式文件不一致。
情况一:模式文件字段重命名
- 新创建模式文件dept2.avsc
{
"namespace":"com.hc.bean",
"type":"record",
"name":"Dept",
"fields":[
{
"name":"deptno","type":"int"},
{
"name":"deptname","type":"string","aliases":["dname"]},
{
"name":"loc","type":"string"}
]
}
-测试代码:
@Test
public void fun41() throws IOException {
//模式文件增加字段
Schema schema = new Schema.Parser().parse(new File("src/main/resources/dept1.avsc"));
File file = new File("src/main/resources/dept.avro");
DatumReader<GenericRecord> datumReader = new SpecificDatumReader<>(schema);
DataFileReader<GenericRecord> dataFileReader = new DataFileReader<>(file, datumReader);
GenericRecord dept = null;
while (dataFileReader.hasNext()) {
dept = dataFileReader.next(dept);
System.out.println(dept);
}
}
- 结果:

情况二:模式文件增加新的字段
- 新创建模式文件dept2.avsc
{
"namespace":"com.hc.bean",
"type":"record",
"name":"Dept",
"fields":[
{
"name":"deptno","type":"int"},
{
"name":"dname","type":"string"},
{
"name":"loc","type":"string"},
{
"name":"tel","type":"string","default":"110120"}
]
}
- 测试代码:
@Test
public void fun42() throws IOException {
//模式文件增加字段
Schema schema = new Schema.Parser().parse(new File("src/main/resources/dept2.avsc"));
File file = new File("src/main/resources/dept.avro");
DatumReader<GenericRecord> datumReader = new SpecificDatumReader<>(schema);
DataFileReader<GenericRecord> dataFileReader = new DataFileReader<>(file, datumReader);
GenericRecord dept = null;
while (dataFileReader.hasNext()) {
dept = dataFileReader.next(dept);
System.out.println(dept);
}
}
- 结果:

情况三:模式文件减少新的字段
- 新创建模式文件dept3.avsc
{
"namespace":"com.hc.bean",
"type":"record",
"name":"Dept",
"fields":[
{
"name":"deptno","type":"int"},
{
"name":"dname","type":"string"}
]
}
- 测试代码:
@Test
public void fun43() throws IOException {
//模式文件增加字段
Schema schema = new Schema.Parser().parse(new File("src/main/resources/dept3.avsc"));
File file = new File("src/main/resources/dept.avro");
DatumReader<GenericRecord> datumReader = new SpecificDatumReader<>(schema);
DataFileReader<GenericRecord> dataFileReader = new DataFileReader<>(file, datumReader);
GenericRecord dept = null;
while (dataFileReader.hasNext()) {
dept = dataFileReader.next(dept);
System.out.println(dept);
}
}
- 结果:

可以发现,上面几种情况,测试代码不用发生任何改变。这也正是采用通用模式的最大好处。
附:使用命令行的方式序列化/反序列化
第一步:提供表示数据的json文件:
{
"deptno":10,"dname":"RESEARCH","loc":"DALLAS"}
{
"deptno":20,"dname":"SALES","loc":"CHICAGO"}
{
"deptno":30,"dname":"OPERATION","loc":"BOSTON"}
{
"deptno":40,"dname":"ACCOUNTING","loc":"NEW YORK"}
第二步:使用avro工具将json文件转换成avro文件:
命令:java -jar avro-tools-1.9.1.jar fromjson --schema-file dept.avsc dept.json > dept.avro

可以设置压缩格式,命令:
java -jar avro-tools-1.9.1.jar fromjson --codec snappy --schema-file dept.avsc dept.json > dept2.avro

第三步:将avro文件反转换成json文件:
命令:java -jar avro-tools-1.9.1.jar tojson dept.avro
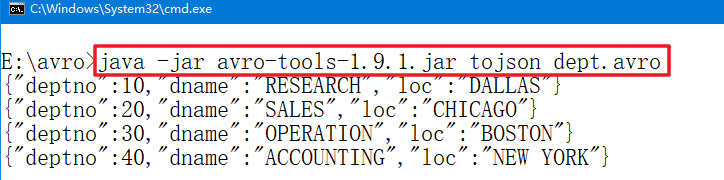
第四步:得到avro文件的meta:
命令:java -jar avro-tools-1.9.1.jar getmeta dept.avro

