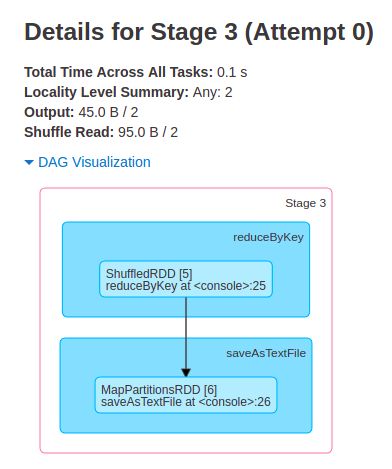
Spark 的计算流程
我们的程序执行环境
通过 spark-shell 程序运行一个交互式会话来演示
Spark-shell 是添加了一些 Spark 功能的 Scala REPL 交互式解释器
而不是 Spark 加了 Scala 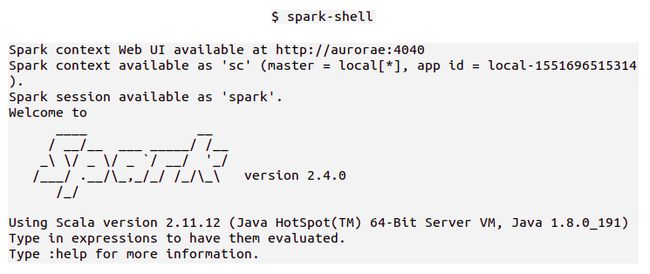
从控制台的输出,我们可以看到三个关键信息
首先我们可以通过 4040 端口查看Spark上下文的信息 
有一个事件时间线会比较实时的记录我们的操作 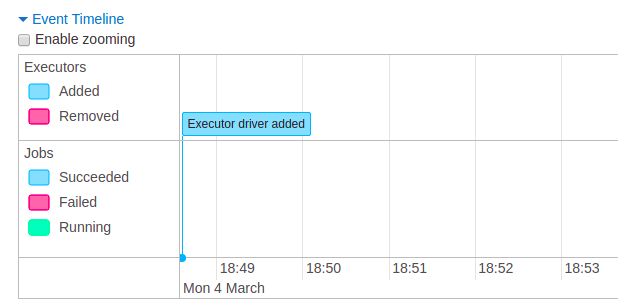
另外这个 Shell 环境已经为我们默认创建了两个 Scala 变量
一个名为 sc 的 Spark context 变量:用于保存 SparkContext 实例,这也是 Spark 的主要入口点,就像我们通过 ApplicationContext 介入 Spring 一样;
还有一个名为 spark 的 Spark session 变量
接下来,我们以一个文本数据来做示例
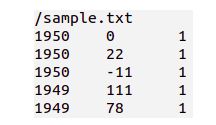
这是截取1950年和1949年中的几个温度数据
我们的任务就要找出每年的最高温度。
其中在真实的数据中,如果数据有缺失会以“9999”来表示
所以在我们的程序中额外要做的一件事就是把温度是“9999”的给过滤掉
textFile
首先,用我们的上下文对象加载我们在文本文件中的数据

结果用 lines 来引用
这个 lines 变量引用的就是一个RDD(Resilient Distributed Dataset,弹性分布式数据集)
问世间 RDD 为何物?
RDD,Spark 的核心概念
从它的名字看出来,它的本质就是一个数据集,
比如我们会把原始的文本文件中的数据一股脑的交给 RDD
所以提到 RDD,你就知道它指代的是我们整个计算过程中的数据集就行。
这个数据集有两个特点
- 一是有弹性
- 二是分布式
分布式比较好理解,它是在集群中跨多个机器分区存储的,而且是只读的对象集合
而所谓的“弹性”其实就指的是它可以让 Spark 通过重新安排计算去自动重建丢失的分区。
关于 Spark 怎么去重新安排计算,而又怎么去重建丢失的分区,分区又是什么,
这些都将贯穿我们学习 Spark 的整个过程。
知会了 RDD 是整个计算中的数据集,就可以谈 Spark 的整个计算流程了
Spark 对 RDD 的计算流程
通常一个 Spark 程序
要经过三大步:加载,转换,动作
加载一个或多个 RDD
然后它们作为输入通过一系列转换得到一组目标 RDD
然后对这些目标 RDD 执行一个动作。
其中转换贯穿了 Spark 整个执行过程,
也就说,Spark 整个过程就是对 RDD 进行转换的过程
而最后以一个动作吻别了整个作业。
另外,
要知道加载 RDD 或执行转换并不会立即触发任何数据处理的操作,
只不过创建了一个计算的计划(这个计划可以像下面这样以一个有向无环图刻画)。
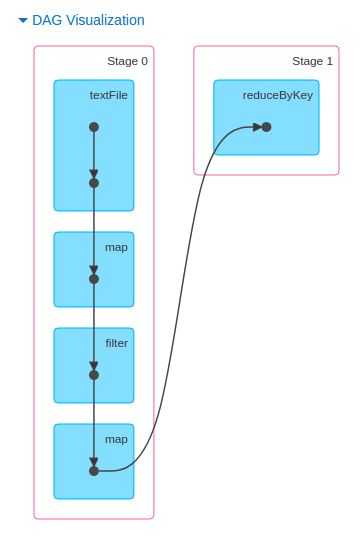
只有当对 RDD 执行某个动作(比如 foreach()时,再比如把结果作为文本文件进行持久存储时),
才会触发真正的计算。
我们把文本文件数据交给一个 String 类型的 RDD 后,
驮着这个 RDD 的引用 lines 继续超我们的目标前行。
map
接下来,我们先把这个 RDD 中有“\t”的地方进行split(这样会好驮一点)
然后一段一段的放进一个数组中,用 records 变量引用,它是一个 Array[String] 类型的 RDD。

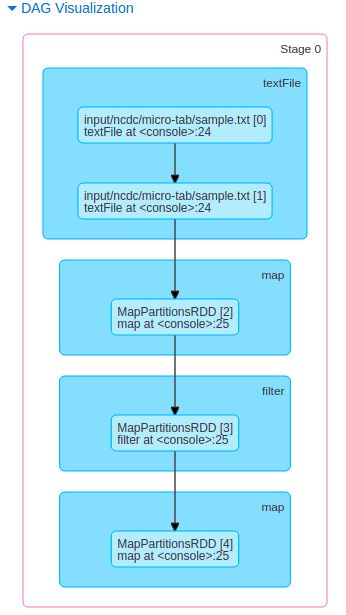
是否曾记得,第一步时,我们得到的有个 MapPartitionsRDD[1] at textFile
而这一步,我们又得到一个 MapPartitionsRDD[2] at map,
思量一下其中的奥妙,好玩的在后面。
通过 RDD 的 map() 方法可以对 RDD 中的每个元素应用某个函数。
因此,我们就能将每一行文本(即一个 String)拆分成一个 String 类型的 Scala 数组。
然后,我们驮着这个一段一段的 records 继续前行。
filter
其实啊,之所以要 split,是因为这样我们可以把那些没用的段给过滤出来扔掉,以减轻负重。

对,就是把那些“9999”给过滤掉,还有那些读数质量不达标的。
我们用 RDD 的 filter() 方法来完成,
其输入的是一个过滤谓词,
也就是一个返回布尔值的函数。
剩下的东西我们用 filtered 变量引用着,它仍是一个 Array[String] 类型的 RDD。
这里我们又得到了一个 MapPartitionsRDD[3] at filter,有思路了么?
继续走吧......
map
为了找出每年的最高温度,
我们需要按年份字段分组,
这样才能对每年的所有温度值进行处理,对吧?
Spark 的 reduceByKey() 方法提供了分组功能,
但是它需要一个用 Scala Tuple2 来表示的键-值对 RDD。
因此我们需要再来一次 map,
把 RDD 转化成适当的形式:

然后驮着这个(Int, Int)类型的 RDD 去见 reduceByKey,
我们暂且就用 tuples 变量引用这个 RDD 吧?
这次,我们得道的是一个 MapPartitionsRDD[4] at map
reduceByKey
好,终于见到大神了,前面铺了那么长的路,只为与大神谋面。
大神的参数是一个函数,
它能把输入的一对值,
按照你的要求输出其中一个值。

好,修成正果.....一个 (Int, Int) 类型的 RDD,我们暂且就管它叫 maxTemps 吧?
这次得道的是一个 ShuffledRDD[5] at reduceByKey
foreach
通过调用 foreach() 方法,
并传递 println() 参数,
把其中的每个元素打印到控制台
看结果
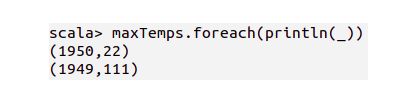
对不对?
存结果
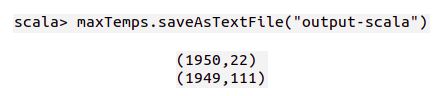
好不好?

完成了两个 Job
Job 0
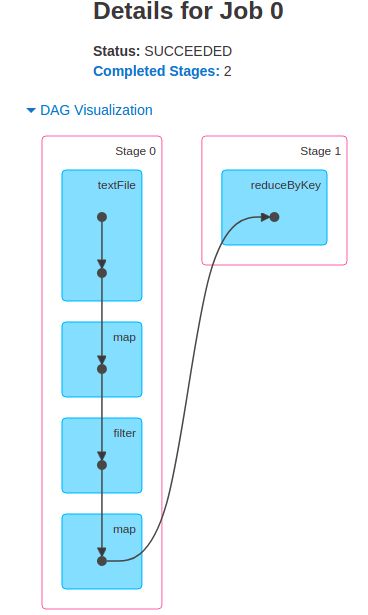
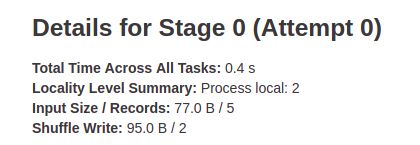
Stage 0
Stage 1

Job 1
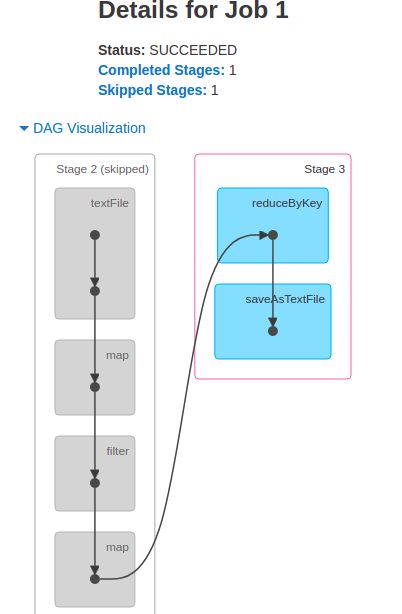
跳过了一个 Stage,完成了一个 Stage

Stage 2

Stage 3