Hadoop3.0基础平台搭建(三节点),以及案例运行并使用python生成词云
一、设备配置列表,软件包
二、主机名映射
三、生成密钥
四、将密钥发送到各个节点
五、注意事项及验证
六、关闭防火墙和SeLinux安全模块(所有主机均需操作
七、解压JDK、hadoop包,设置Java和hadoop环境
八、配置Hadoop相关配置文件
九、将已经修改好的文件使用scp命令复制到各个节点
十、node1 、 node2使环境生效,并验证
十一、启动hadoop系统并验证
十二、在本地编写并测试mapreduce程序,运行WordCount案例
十三、在hadoop中运行运行WordCount案例
十四、利用生成文件结合python生成词云
一、假设有如下设备
| 设备编号 | 主机名 | 系统 | IP地址 | 准备文件 |
|---|---|---|---|---|
| 1 | master | centos7.2 | 10.0.0.10 | ----------------hadoop3.0.0.tar.gz -------------------------jdk-8u161-linux-x64.tar.gz |
| 2 | node1 | centos7.2 | 10.0.0.11 | |
| 3 | node2 | centos7.2 | 10.0.0.12 |
软件包下载地址:
链接: https://pan.baidu.com/s/1dvf4o8i9J02fmUu3SMRyDw 提取码: 3dk3
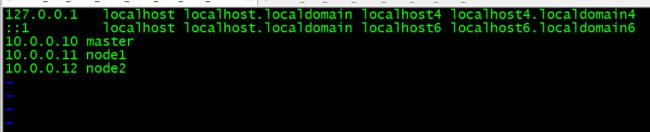
二、首先,需要在各个节点上设置主机名映射(千万不要忘了改主机名),以master为例
[root@master ~]# vi /etc/hosts
添加如下内容
10.0.0.10 master
10.0.0.11 node1
10.0.0.12 node2
三、使用命令生成密钥(以master节点为例)
ssh-keygen
[root@master ~]# ssh-keygen

四、然后使用命令复制SSH密钥到目标主机,开启无密码SSH登录(以master节点为例),这里对另外两台都需要将密钥复制过去
[root@master ~]# ssh-copy-id master
[root@master ~]# ssh-copy-id node1
[root@master ~]# ssh-copy-id node2
五、第一次会让你输入yes 这样master节点就可以免密登陆其他节点,同样其他节点也需要进行以上操作,就可以免密登陆其他节点
验证[root@master ~]# ssh master
[root@master ~]# ssh node1
[root@master ~]# ssh node2
六、关闭防火墙和SeLinux安全模块(所有主机均需操作
#systemctl stop firewalld;systemctl disable firewalld;setenforce 0
这里是关闭防火墙并关闭其开机自启,并将selinux设置为允许模式,个人认为这里较为重要,若不设置,可能防火墙会拦截主机间的通信流量
七、解压JDK、hadoop包,设置Java和hadoop环境
将tar.gz文件传输到master节点,进行如下操作
这里暂时只做master节点,到第九步才是将配置好的所有东西复制到其他节点,可以点击传送门查看
第九节传送门
1、每个节点创建文件夹
mkdir /opt/bigdata
2、将文件传输到bigdata目录中
[root@master ~]# mkdir /opt/bigdata
[root@master ~]# mv hadoop-3.0.0.tar.gz jdk-8u161-linux-x64.tar.gz /opt/bigdata/
[root@master ~]#
3、解压压缩包文件
[root@master bigdata]# tar -zxf hadoop-3.0.0.tar.gz -C /opt/bigdata/
[root@master bigdata]# tar -zxf jdk-8u161-linux-x64.tar.gz -C /opt/bigdata/
[root@master bigdata]# ll
total 484528
drwxr-xr-x 9 centos centos 139 Dec 8 2017 hadoop-3.0.0
-rw-r--r-- 1 root root 306392917 Mar 11 08:50 hadoop-3.0.0.tar.gz
drwxr-xr-x 8 10 143 4096 Dec 20 2017 jdk1.8.0_161
-rw-r--r-- 1 root root 189756259 Mar 11 08:50 jdk-8u161-linux-x64.tar.gz
4、添加环境变量
#vi /etc/profile添加如下内容
export JAVA_HOME=/opt/bigdata/jdk1.8.0_161
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/opt/bigdata/hadoop-3.0.0
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH

5、使环境变量生效
source /etc/profile
6、验证
# hadoop version
# java -version

八、配置Hadoop相关配置文件
hadoop目录是hadoop平台的配置目录,我们需要对hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml进行配置1、首先进入hadoop系统目录/opt/bigdata/hadoop-3.0.0/etc/hadoop
[root@master ~]# cd /opt/bigdata/hadoop-3.0.0/etc/hadoop
[root@master hadoop]# pwd
/opt/bigdata/hadoop-3.0.0/etc/hadoop
[root@master hadoop]# ls

2、编辑hadoop-env.sh,添加java环境
[root@master hadoop]# vi hadoop-env.sh
移动到第54行,删除前面的 '#' 和空格,并修改成如下内容
export JAVA_HOME=/opt/bigdata/jdk1.8.0_161
![]()
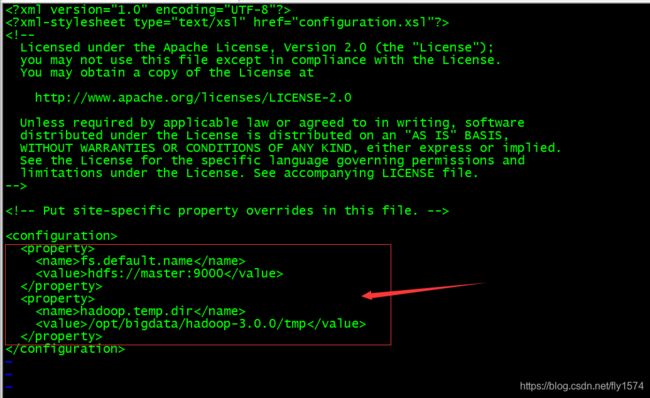
3、编辑core-site.xml文件
[root@master hadoop]# vi core-site.xml
fs.default.name</name>
hdfs://master:9000</value>
</property>
hadoop.temp.dir</name>
/opt/bigdata/hadoop-3.0.0/tmp</value>
</property>
4、编辑hdfs-site.xml文件
[root@master hadoop]# vi hdfs-site.xml
dfs.replication</name>
2</value>
</property>
dfs.namenode.name.dir</name>
/opt/bigdata/hadoop-3.0.0/hdfs/name</value>
</property>
dfs.datanode.data.dir</name>
/opt/bigdata/hadoop-3.0.0/hdfs/data</value>
</property>
dfs.namenode.secondary.http-address</name>
node1:9001</value>
</property>
dfs.http.address</name>
0.0.0.0:50070</value>
</property>

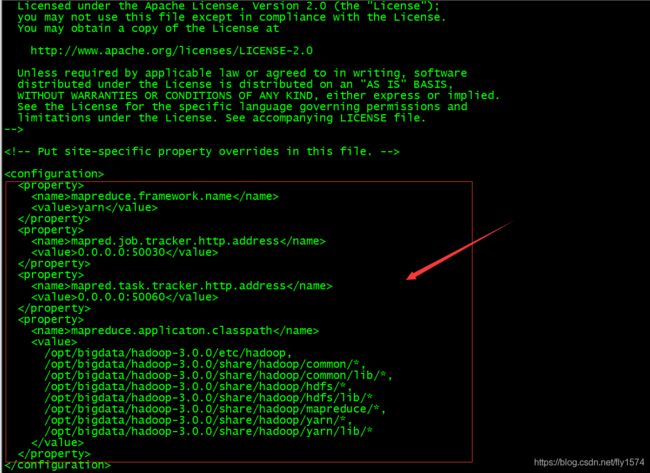
5、编辑mapred-site.xml文件
[root@master hadoop]# vi mapred-site.xml
mapreduce.framework.name</name>
yarn</value>
</property>
mapred.job.tracker.http.address</name>
0.0.0.0:50030</value>
</property>
mapred.task.tracker.http.address</name>
0.0.0.0:50060</value>
</property>
mapreduce.applicaton.classpath</name>
/opt/bigdata/hadoop-3.0.0/etc/hadoop,
/opt/bigdata/hadoop-3.0.0/share/hadoop/common/*,
/opt/bigdata/hadoop-3.0.0/share/hadoop/common/lib/*,
/opt/bigdata/hadoop-3.0.0/share/hadoop/hdfs/*,
/opt/bigdata/hadoop-3.0.0/share/hadoop/hdfs/lib/*
/opt/bigdata/hadoop-3.0.0/share/hadoop/mapreduce/*,
/opt/bigdata/hadoop-3.0.0/share/hadoop/yarn/*,
/opt/bigdata/hadoop-3.0.0/share/hadoop/yarn/lib/*
</value>
</property>
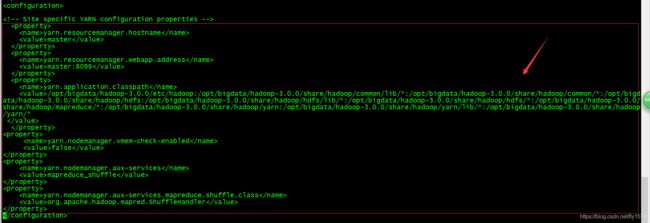
6、编辑yarn-site.xml文件
[root@master hadoop]# vi yarn-site.xml
yarn.resourcemanager.hostname</name>
master</value>
</property>
yarn.resourcemanager.webapp.address</name>
master:8099</value>
</property>
yarn.application.classpath</name>
/opt/bigdata/hadoop-3.0.0/etc/hadoop:/opt/bigdata/hadoop-3.0.0/share/hadoop/common/lib/*:/opt/bigdata/hadoop-3.0.0/share/hadoop/common/*:/opt/bigdata/hadoop-3.0.0/share/hadoop/hdfs:/opt/bigdata/hadoop-3.0.0/share/hadoop/hdfs/lib/*:/opt/bigdata/hadoop-3.0.0/share/hadoop/hdfs/*:/opt/bigdata/hadoop-3.0.0/share/hadoop/mapreduce/*:/opt/bigdata/hadoop-3.0.0/share/hadoop/yarn:/opt/bigdata/hadoop-3.0.0/share/hadoop/yarn/lib/*:/opt/bigdata/hadoop-3.0.0/share/hadoop/yarn/*
</value>
</property>
yarn.nodemanager.vmem-check-enabled</name>
false</value>
</property>
yarn.nodemanager.aux-services</name>
mapreduce_shuffle</value>
</property>
yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
7、编辑workers文件,指定节点
[root@master hadoop]# vi workers
添加node1 node2

如果不想master中也有datanode,就把localhost删掉,只保留node1 node2
8、编辑启动配置文件,都添加如下内容
[root@master ~]# vi /opt/bigdata/hadoop-3.0.0/sbin/start-dfs.sh
[root@master ~]# vi /opt/bigdata/hadoop-3.0.0/sbin/stop-dfs.sh
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root

编辑配置文件,都添加如下内容
[root@master ~]# vi /opt/bigdata/hadoop-3.0.0/sbin/start-yarn.sh
[root@master ~]# vi /opt/bigdata/hadoop-3.0.0/sbin/stop-yarn.sh
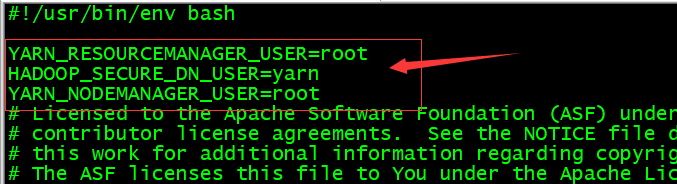
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
九、将已经修改好的文件使用scp命令复制到各个节点
1、首先要在各个节点创建/opt/bigdata目录
[root@node1 ~]# mkdir /opt/bigdata
[root@node2 ~]# mkdir /opt/bigdata
2、master节点复制hadoop文件夹 和jdk文件夹,以及环境配置文件
[root@master ~]# scp -r /opt/bigdata/hadoop-3.0.0 node1:/opt/bigdata
[root@master ~]# scp -r /opt/bigdata/hadoop-3.0.0 node2:/opt/bigdata
[root@master ~]# scp -r /opt/bigdata/jdk1.8.0_161/ node1:/opt/bigdata/
[root@master ~]# scp -r /opt/bigdata/jdk1.8.0_161/ node2:/opt/bigdata/
[root@master ~]# scp /etc/profile node1:/etc/
[root@master ~]# scp /etc/profile node2:/etc/
十、node1 、 node2使环境生效,并验证
##### 1、node1验证 ```powershell [root@node1 ~]# source /etc/profile [root@node1 ~]# java -version [root@node1 ~]# hadoop version ```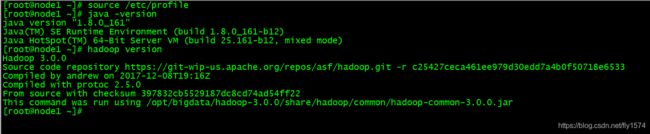
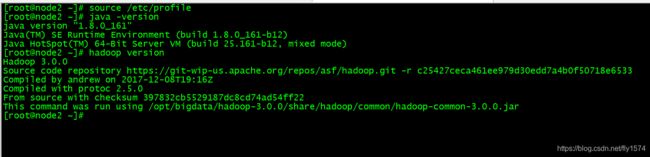
2、node2验证
[root@node2 ~]# source /etc/profile
[root@node2 ~]# java -version
[root@node2 ~]# hadoop version
十一、启动hadoop系统并验证
1、第一次启动,格式化namenode
[root@master ~]# hadoop namenode -format
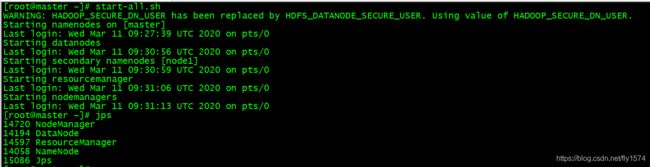
2、启动hadoop系统,并验证
[root@master ~]# start-all.sh
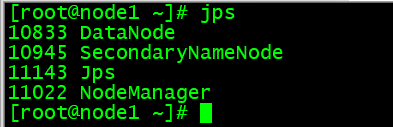
[root@master ~]# jps
[root@node1 ~]# jps
[root@node2 ~]# jps

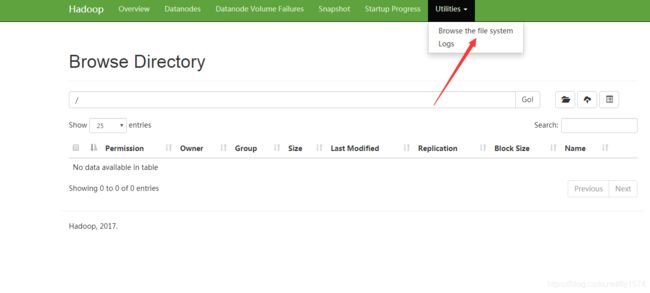
网页端访问master节点ip地址
http://Master_IP:50072
例:
http://10.0.0.10:50070

网页端查看HDFS文件系统
十二、在本地编写并测试mapreduce程序,运行WordCount案例
编写MapReduce程序,请注意,此处使用python2代码。因为CentOS7.2已经安装了python2
1、首先编写mapper.py程序
[root@master ~]# vi mapper.py
#!/usr/bin/env python
# -*- coding:UTF-8 -*-
import sys
for line in sys.stdin:
line = line.strip()
words = line.split()
for word in words:
print '%s\t%s' % (word, 1)
2、编写Reducer程序
[root@master ~]# vi reducer.py
#!/usr/bin/env python
# -*- coding:UTF-8 -*-
#from operator import itemgetter
import sys
current_word = None
current_count = 0
word = None
for line in sys.stdin:
line = line.strip()
word, count = line.split('\t', 1)
try:
count = int(count)
except ValueError:
continue
if current_word == word:
current_count += count
else:
if current_word:
print '%s\t%s' % (current_word, current_count)
current_count = count
current_word = word
if current_word == word:
print '%s\t%s' % (current_word, current_count)
3、给刚刚编写的程序添加执行权限
[root@master ~]# chmod a+x mapper.py
[root@master ~]# chmod a+x reducer.py

4、使用echo加sort对程序进行测试
[root@master ~]# echo “hello world hell hi word” | python mapper.py |sort|python reducer.py

十三、在hadoop中运行WordCount案例
一定要检查一下yarn-site.xml,之前的配置文件我已经重新修改了,请回到第八步第六小点再看看,yarn-site.xml有没有添加上
yarn.nodemanager.aux-services</name>
mapreduce_shuffle</value>
</property>
yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
1、首先编写MapReduce脚本mapreduce.sh
[root@master ~]# vi mapreduce.sh
hadoop jar /opt/bigdata/hadoop-3.0.0/share/hadoop/tools/lib/hadoop-*streaming*.jar -mapper "python mapper.py" -reducer "python reducer.py" -input /user_test/
data.txt -output /output_dir -file /opt/bigdata/mapreduce/mapper.py -file /opt/bigdata/mapreduce/reducer.py

#streaming可以执行任意语言写的mapper,reducer程序
-mapper "python mapper.py" #执行mapper程序
-reducer "python reducer.py" #执行reducer程序
-input /user_test/data.txt -output /output_dir #导入文件及导出文件地址
-file /opt/bigdata/mapreduce/mapper.py #mapper程序路径
-file /opt/bigdata/mapreduce/reducer.py #reducer程序路径
2、在本地,首先创建文件夹,将mapper.py和reducer.py移动到相应位置,也可在相应位置创建好
[root@master ~]# mkdir /opt/bigdata/mapreduce
[root@master ~]# mv mapper.py reducer.py /opt/bigdata/mapreduce/
[root@master ~]# ls /opt/bigdata/mapreduce/

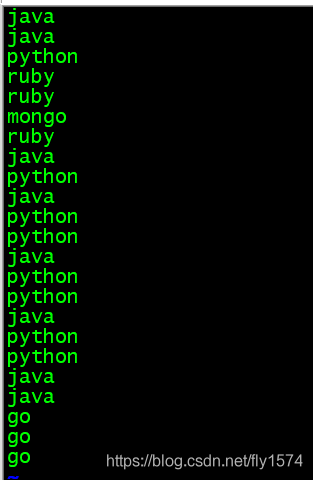
3、在本地创建data.txt文件,并输入相应数据
[root@master ~]# vi data.txt
java
java
python
ruby
ruby
mongo
ruby
java
python
java
python
python
java
python
python
java
python
python
java
java
4、在 HDFS 文件系统中创建相应目录以及将data.txt文件上传
[root@master ~]# hdfs dfs -mkdir /user_test
[root@master ~]# hdfs dfs -chmod -R 777 /user_test ##给目录添加权限
[root@master ~]# hdfs dfs -put /root/data.txt /user_test
[root@master ~]# hdfs dfs -ls /user_test

5、查看是否存在 输出目录 (一定不能存在,如果存在就需要删除)
[root@master ~]# hdfs dfs -ls /

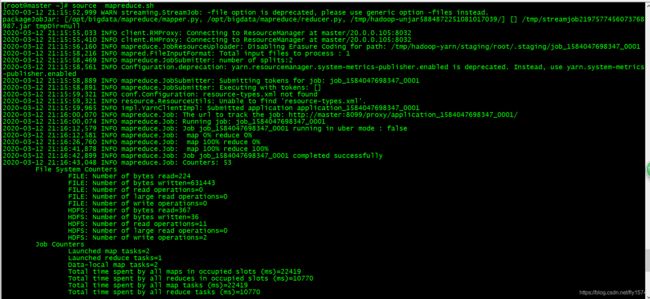
6、运行mapreduce.sh脚本,测试运行
[root@master ~]# source mapreduce.sh
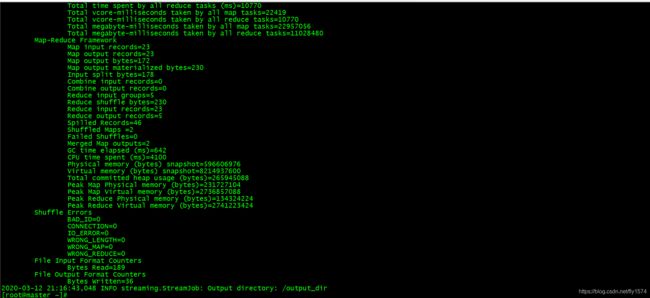
7、查看结果
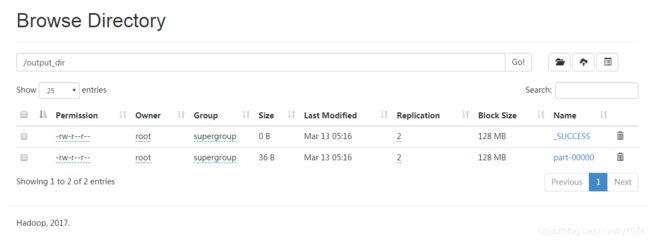
[root@master ~]# hdfs dfs -ls /output_dir
[root@master ~]# hdfs dfs -cat /output_dir/part-00000

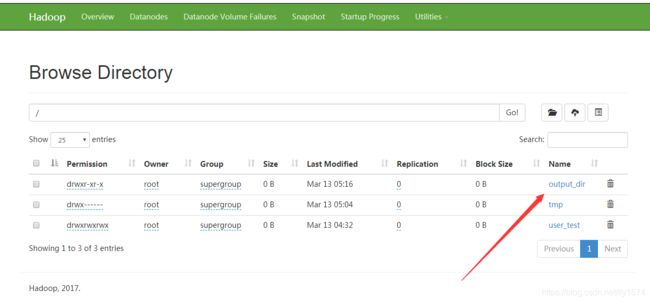
也可以在Web端查看
http://Master_I:50070
点击下载会提示网页无法访问,请将node1或者node2替换成相应的IP地址即可
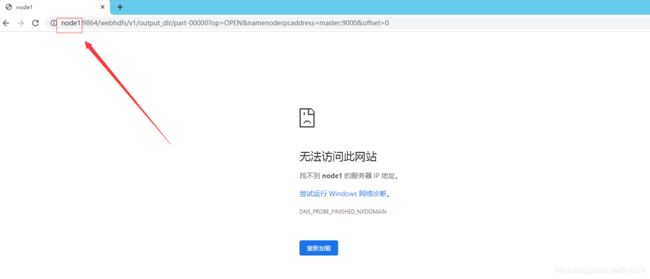
十四、利用生成文件结合python生成词云
这里我使用python3进行实验
1、将上述的文件下载到Windows
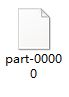
2、在windows下,下载/安装pip
pip install wordcloud(执行下载woedcloud)
pip install matplotlib(执行下载matplotlib)
3、此时我将part-00000文件存放于E盘下
4、编写输出词云的python程序
# -*-coding:UTF-8 -*-
# 导入相关的库
import matplotlib #导入matplotlib
matplotlib.use('Agg')
from os import path
import matplotlib.pyplot as plt
from wordcloud import WordCloud #从wordcloud导入WordCloud
# 获取当前文件路径
# __file__ 为当前文件, 在ide中运行此行会报错,可改为
# d = path.dirname('.')
d = path.dirname('.') ##选择文件路径
# 读取整个文件
text = open(path.join(d, 'E:\part-00000')).read() #打开文件并赋值给变量text
#wordcloud = WordCloud().generate(text)
wc = WordCloud().generate(text)
wc.to_file('Word Cloud.png') #命名生成的图片
# 绘图
plt.imshow(wc)
plt.axis("off")
6、运行程序得到词云图片


本次教程到此结束,如果您觉得不错,可以打赏,请您到B站观看更多技术视频,欢迎点赞投币打赏!
