爬取新浪微博关于ios12.1.2的内容——多线程爬虫的应用
文章目录
- 一、思路
- 二、爬虫
-
-
- 1.网页分析
- 2.代码实现
-
- 三、结果分析
-
-
- 1.情感分析
- 2.关键词与词云分析
-
一入爬虫深似海,回头还是在入门
2018年12月18日凌晨,苹果正式推送ios12.1.2,博主是前天才升级的,结果升完级后发现使用数据流量上网时的信号变差了,具体有两个事例:一是在地铁出口买早餐,刷不出付款码;二是玩游戏的时候很卡。这是升级系统前没有遇到的问题。
一、思路
做数据分析的不能凭主观感觉就直接下结论,为了验证博主遇到的情况是不是普遍存在,选取了具有代表性的社交平台——新浪微博作为爬取对象,搜索与ios12.1.2相关的微博内容,对结果进行分析。
爬虫目标为新浪微博手机版网站,方法主要采用模拟Ajax请求,从返回的json格式的数据中提取微博内容。同时将使用多线程以提高爬虫效率,首先将爬取目标集合生成一个队列,各线程依次从队列取出爬取目标进行爬取,每条线程单独缓存爬取的数据,最后将所有线程缓存的数据合并得到结果。
二、爬虫
1.网页分析
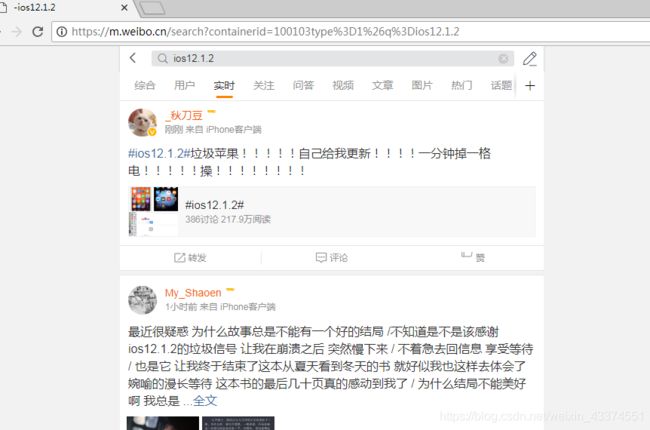
由于涉及ios12.1.2的热门微博量不大,所以本次分析还是选择了ios12.1.2搜索出来的所有的微博,具体操作是选择"实时"选项。
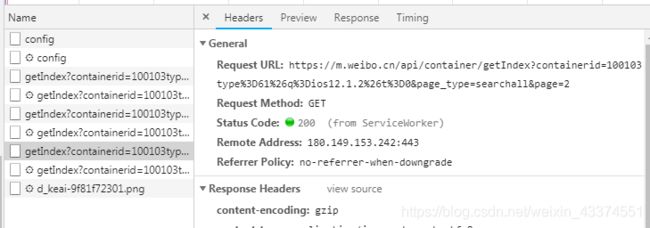
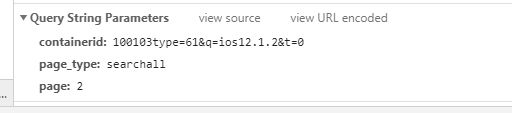
向下滚动,有更多的微博加载出来,在谷歌浏览器开发者模式里可以看到数据流,从General可以看到返回微博内容的Ajax请求是一个GET请求,有3个参数,分别是containerid、page_type、page,其中前两个参数表示搜索的关键字和搜索方法,是固定的,变化的是page,表示页数。

具体看一下返回的json数据,每一页数据包含10条微博,具体在cards的card_group内。
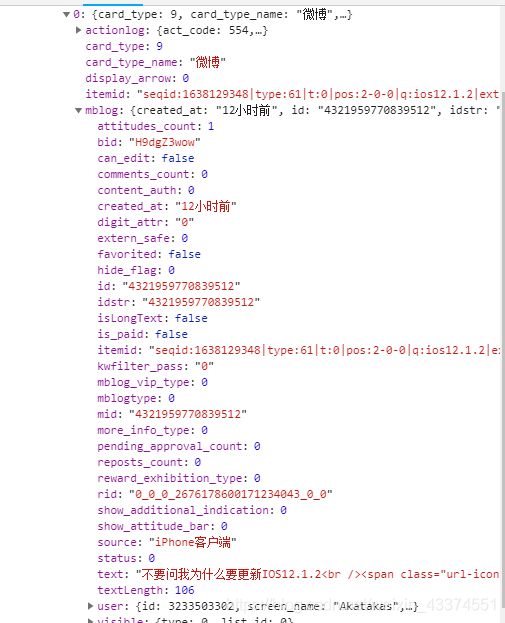
而每一条微博的具体内容,是mblog内的text。可以看到微博内容里还有一些类似
的html本文,在提取的时候顺便清洗掉。
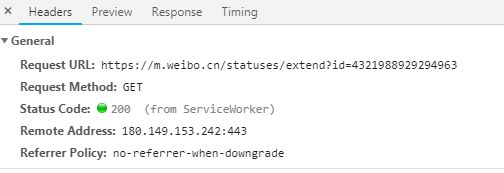
如果一条微博内容较多显示不全的,就需要单独进入这条微博的页面进行提取,可以看到也是一个GET请求,只有一个参数就是id,而这个id正是mblog内可以提取到的id。
2.代码实现
import requests
import threading
import queue
import re
from openpyxl import Workbook
class GetText_Thread(threading.Thread):
def run(self):
global DataList
url='https://m.weibo.cn/api/container/getIndex'
pattern=re.compile('<.*?>') #清洗文本
DataList_tmp=[] #每个线程存储提取结果的缓存列表
while not DataQueue.empty():
#从队列取值
queueLock.acquire()
data=DataQueue.get()
queueLock.release()
try:
js_resp=requests.get(url,params=data).json()
items=js_resp.get('data').get('cards')[0]['card_group']
for item in items:
#分情况获取文本,有...全文的单独提取
if re.sub(pattern,'',item.get('mblog')['text']).find('...全文')!=-1:
url_total='https://m.weibo.cn/statuses/extend?id='+item.get('mblog')['id']
js_total=requests.get(url_total).json()
DataList_tmp.append(re.sub(pattern,'',js_total.get('data').get('longTextContent')))
else:
DataList_tmp.append(re.sub(pattern,'',item.get('mblog')['text']))
except Exception as e:
print(repr(e))
#将该线程获得的结果存入DataList
queueLock.acquire()
DataList+=DataList_tmp
queueLock.release()
#填充队列
def QueueFill():
#微博实时搜索结果共91页
for i in range(1,92):
data={
'containerid':'100103type=61&q=ios12.1.2&t=0',
'page_type':'searchall',
'page':i
}
DataQueue.put(data)
#保存到excel
def SaveToExcel():
wb=Workbook()
ws=wb.active
r=1
for data in DataList:
ws.cell(row=r,column=1,value=data)
r+=1
wb.save(r'C:\Users\Administrator\Desktop\weibo_data.xlsx')
def main():
#生成队列
QueueFill()
#创建30个线程
for i in range(30):
thread=GetText_Thread()
thread.start()
threads.append(thread)
#等待所有线程完成
for t in threads:
t.join()
#结果保存到Excel
SaveToExcel()
if __name__=='__main__':
queueLock=threading.Lock()
DataQueue=queue.Queue()
DataList=[]
threads=[]
main()
三、结果分析
爬取的结果一共是833条微博,其中一部分是ios12.1.1或者ios12.1的,将这部分过滤掉后,剩下669条微博。同时文本中的所有标点符号和空格也全部去掉。数据清洗的具体过程这里略过不讲。
1.情感分析
SnowNLP是国人开发的强大的中文文本处理库,其情感分析模块的训练数据用的是商品评价的语料库,训练模型是朴素贝叶斯,因此用它做ios12.1.2微博内容的情感分析是很契合的。SnowNLP的sentiments返回对文本表达的情绪预测的评分,趋向1为积极情绪,趋向0为消极情绪。这里我们将评分大于等于0.6的归为积极评价,小于0.6的归为消极评价。
from snownlp import SnowNLP
import matplotlib.pyplot as plt
score_list=[]
with open(r'C:\Users\Administrator\Desktop\weibo_data.txt') as fn:
data=fn.readlines()
for line in data:
score_list.append(SnowNLP(line).sentiments)
#画直方图
plt.rcParams[ 'font.sans-serif'] = [ 'Microsoft YaHei']
plt.rcParams[ 'axes.unicode_minus'] = False
plt.style.use('ggplot')
plt.title('情感分析评分直方图')
plt.hist(score_list,bins=10,color='steelblue',edgecolor='k')
plt.show()
#情感评分0.6以上为积极评价
num=0
for i in score_list:
if i>=0.6:
num+=1
print('总微博数:',len(score_list))
print('积极评价数:%d,占比:%.2f%%' % (num,num*100/len(score_list)))
print('消极评价数:%d,占比:%.2f%%' % (len(score_list)-num,(len(score_list)-num)*100/len(score_list)))
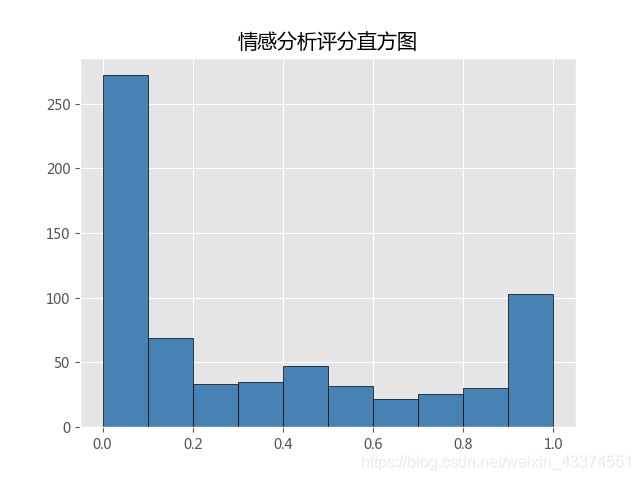
可以从评分直方图直观的看到,微博用户对ios12.1.2的评价态度是较为鲜明的,具体表现为评分明显集中在0-0.1和0.9-1.0两个区间,说明是爱的很爱,恨的也很恨。另外在这两个区间也可以看到消极评价的数量要多于积极评价的数量。

从具体的统计数字来看,积极评价与消极评价之比约为3:7。
2.关键词与词云分析
涉及词频的文本分析,通常需要先进行分词。英文单词与单词之间天然就有空格,但是中文字与字之间没有,所以需要分词。分词的准确率影响文本分析的结果。这里博主用的是当今最流行的中文分词方案,嗯,之一,jieba分词方案。
import jieba
import re
from wordcloud import WordCloud
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
#载入停用词
def MyStopword():
with open(r'C:\Users\Administrator\Desktop\stopwords.txt','r',encoding='UTF-8-sig') as fn:
data=fn.readlines()
stopwords=[word.strip() for word in data]
return stopwords
#分词
def SegSentence(sentence):
#去除标点符号和停用词
sentence_seg=jieba.cut(re.sub('[’ !"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~’!“”¥、‘(),。:;《》?【】……]+','',sentence))
stopwords=MyStopword()
str=[]
for word in sentence_seg:
if word not in stopwords:
str.append(word)
return str
jieba.load_userdict(r'C:\Users\Administrator\Desktop\mydict.txt') #导入用户自定义词典
with open(r'C:\Users\Administrator\Desktop\weibo_text.txt') as fn:
data=fn.readlines()
text_list=[]
text_positive=[]
text_negative=[]
for i in data:
text_list.append(SegSentence(i))
if SnowNLP(ws.cell(i,2).value).sentiments>=0.6:
text_positive.append(SegSentence(ws.cell(i,2).value))
else:
text_negative.append(SegSentence(ws.cell(i,2).value))
为了减少停用词的干扰,需要在分词之后过滤掉中文停用词,博主用的停用词来自中文停用词表https://blog.csdn.net/u010533386/article/details/51458591
同时还添加了诸如"微博"、“苹果”、“ios12.1.2"等。为了避免专用词被误分,还要导入用户自定义的词典,这里主要添加了诸如"ios”、“ios12.1.2”、"IOS12.1.2"等。
word_list=[]
for word in text_list:
word_list+=word
word_set=set(word_list)
wordcount_dict={
}
itemcount_dict={
}
#计算词频
for word in list(word_set):
wordcount_dict[word]=word_list.count(word)
itemcount_dict[word]=0
for item in text_list:
if word in item:
itemcount_dict[word]+=1
#词频排序
wordsort=sorted(wordcount_dict.items(),key=lambda item:item[1],reverse=True)
itemsort=sorted(itemcount_dict.items(),key=lambda item:item[1],reverse=True)
print('词频排序:')
for i in range(20):
print(i+1,wordsort[i][0],wordsort[i][1])
print('\n包含词语的微博数排序')
for i in range(20):
print(i+1,itemsort[i][0],itemsort[i][1])
词频主要计算了词语在整个样本中出现的频数,以及词语在多少条微博中出现过。得到的结果如下:
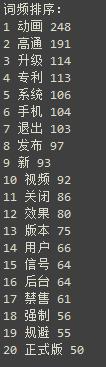
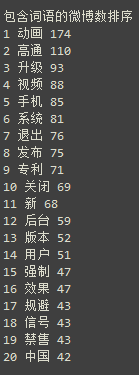
从前20的排名可以看到,动画、高通、退出均是高频词语,原来大家最关心的还是苹果为了规避高通的侵权案,在ios12.1.2中更改了程序退出的动画,由以前的向上滑动退出变成了逐渐淡化退出。而博主关心的信号问题,总共仅出现了64次,在43条微博中出现过,占比仅为6.4%,看来还是有一些人遇到过同样的问题,只是不算很普遍(博主太倒霉了!)。
下面我们再来看一下,积极评价和消极评价的关键词分别是哪些。
word_list=[]
for word in text_list:
word_list+=word
word_set=set(word_list)
wordcount_dict={
}
itemcount_dict={
}
positive_list=[]
negative_list=[]
for word in text_positive:
positive_list+=word
for word in text_negative:
negative_list+=word
positive_set=set(positive_list)
negative_set=set(negative_list)
positivecount_dict={
}
negativecount_dict={
}
#计算词频
for word in list(positive_set):
positivecount_dict[word]=positive_list.count(word)
for word in list(negative_set):
negativecount_dict[word]=negative_list.count(word)
#词频排序
positivesort=sorted(positivecount_dict.items(),key=lambda item:item[1],reverse=True)
negativesort=sorted(negativecount_dict.items(),key=lambda item:item[1],reverse=True)
print('\n积极评价词频排序:')
for i in range(20):
print(i+1,positivesort[i][0],positivesort[i][1])
print('\n消极评价词频排序:')
for i in range(20):
print(i+1,negativesort[i][0],negativesort[i][1])
得到的结果是


可以看到消极评价中主要还是涉及到苹果与高通的侵权一案,但是积极评价中也有这一内容,说明SnowNLP自带的语料库还是主要针对购物评价,因此用于ios12.1.2的微博内容还是有一定偏差,这点可以通过训练自己的样本模型减少误差,这里不再赘述。而抛开动画、高通、专利和规避,消极评价中还有三个关键词,一是禁售,说明国内禁售iPhone也是热议话题;二是信号,这就是博主遇到的问题;三是壁纸,部分人反映升级后设置壁纸无法缩放。
最后我们生成一个词云
#生成词云
mask=np.array(Image.open(r'C:\Users\Administrator\Desktop\Apple.jpg'))
wc=WordCloud(
background_color='white',
max_words=2000,
mask=mask,
font_path='simfang.ttf',
max_font_size=60,
random_state=42
)
wc.generate_from_frequencies(wordcount_dict)
plt.imshow(wc,interpolation='bilinear')
plt.axis('off')
plt.show()
在词云中可以明显看到动画、高通、专利、规避、禁售等
