数据挖掘——关联规则分析(一)概述
记录自己所学,若有不对的地方,希望大家指出来。
2.1 关联分析概述
2.1.1 关联分析定义及应用
1、关联分析定义:从数据集中找出对象或项集之间同时发生的关联或顺序关系。
应用: 购物篮数据分析
关联销售
目录编排
促销分析
web日志分析
DNA序列分析(癌症数据分析中,搜索DNA和蛋白质序列的有趣且频繁出现的模式) 移动通信套餐业务分析
关联规则挖掘是用于知识发现,而非预测,所以是属于无监督的机器学习方法。
2.1.2 事务与规则
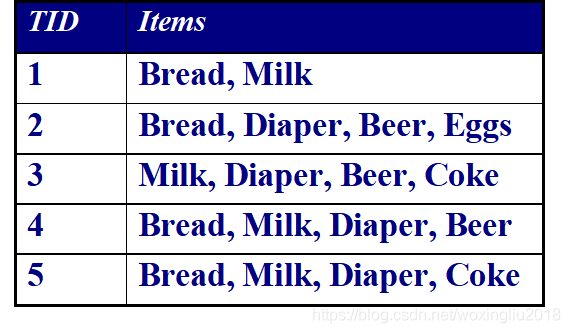
事务标识:T={t1 , t2 , ... ,tN} 例:TID={1,2,3,4,5}
项集:I={i1,i2 ,... , id} 例:I={Bread,Milk,Diaper,Beer,Eggs,Coke}
k-项集:{Break、Milk}是一个2-项集,{Bread、Diaper、Beer、Eggs}是一个4-项集
事务:若干项组成的集合 例:{Bread,Milk}即一个事务
2.1.3 关联规则
1、关联规则(Association Rule):一般记为 X→Y 的形式,用于表示数据内隐含的关联性
2、关联规则的强度由 “三度” 控制:支持度、置信度、提升度
3、支持度、频繁项集
①支持度(Support ):指所有项集中{X,Y}同时出现的项集所占的百分比 即项集中同时含有X和Y 的概率;
②最小支持度(minsupport):即用户规定的关联规则必须满足的最小的支持度阈值。
③频繁项集(Frequent Itemset):支持度大于或等于minsupport的非空项集
4、置信度
①置信度(Confidence):关联规则X→Y的置信度(Confidence) 是指包含X和Y的项集数与包含X的项集数之比 即Confidence(X→Y ) = support(X,Y)/ support(X) 易知, Confidence(X→Y ) =P(Y |X)
②最小置信度(minconfidence): 即用户规定的关联规则必须满足的最小的置信度阈值 它反应了关联规则的最低可靠度
5、强关联规则(Strong Association Rule): 同时满足最小支持度(Minsupport)和最小置信度(Minconfidence)的关联规则称为强关联规则。
6、支持度和可信度计算举例

规则 X → Y 的支持度和可信度
支持度 s:一次交易中同时包含{X 、 Y }的可能性
置信度 c :包含项X 的交易中同时也包含Y的条件概率

设最小支持度为0.5, 最小可信度为 0.5, 则可得到关联规则
A → C (0.5, 0.67)
第一个0.5表示支持度,2(A,C同时出现次数)/4(共4条记录)
第二个0.67表示置信度,2(A,C同时出现次数)/3(A出现的次数)
C → A (0.5, 1)
第一个0.5表示支持度,2(A,C同时出现次数)/4(共4条记录)
第二个1表示置信度,2(A,C同时出现次数)/2(C出现的次数)
7、规则置信度、规则支持度、前项支持度、后项支持度
| Y | 合计 | |||
| 1 | 0 | |||
| X | 1 | A | B | R1 |
| 0 | C | D | R2 | |
| 合计 | C1 | C2 | T | |
规则置信度:A/R1 规则支持度:A/T
前项支持度:R1/T 后项支持度:C1/T
例:
| 吃 | 不吃 | 合计 | |
|---|---|---|---|
| 优异 | 60 | 40 | 100 |
| 不优异 | 66 | 14 | 80 |
| 合计 | 126 | 54 | 180 |
规则置信度:60/100=60% 规则支持度:60/180=33.33%
前项支持度:100/180 后项支持度:126/180=70%
8、提升度(lift)
提升度(lift)= 规则置信度 / 后项支持度
即 Lift(X→Y) = Confidence(X→Y) / P(Y) = P(Y|X) / P(Y)
这个公式是用来衡量 A 出现的情况下,是否会对 B 出现的概率有所提升。
所以提升度有三种可能:
提升度 (A→B)>1:代表有提升;
提升度 (A→B)=1:代表有没有提升,也没有下降;
提升度 (A→B)<1:代表有下降。
9、关联规则挖掘问题
①挖掘关联规则问题就是寻找支持度和置信度分别大于用户给定的最小阈值的关联规则。
②挖掘关联规则问题可以划分成两个子问题: 发现频繁项目集:通过用户给定Minsupport ,寻找所有频繁项目集或者最大频繁项目集。 生成关联规则:通过用户给定Minconfidence ,在频繁项目集中,寻找关联规则。 第1个子问题是近年来关联规则挖掘算法研究的重点。
10、关联规则挖掘的基本模型

2.1.4 小结
主要了解支持度(S)、置信度(C)、提升度(L)如何计算