像素缓冲区对象(PBO) 的Streaming-Texture上传 源码解析
接这篇文章 OpenGL深入探索——像素缓冲区对象 (PBO)(附完整工程代码地址)
原理示意图:

首选检查显卡是否支持 PBO :
#if defined(_WIN32)
// check PBO is supported by your video card
// 检查显卡是否支持 PBO
if (glInfo.isExtensionSupported("GL_ARB_pixel_buffer_object"))
{
// get pointers to GL functions
glGenBuffersARB = (PFNGLGENBUFFERSARBPROC)wglGetProcAddress("glGenBuffersARB");
glBindBufferARB = (PFNGLBINDBUFFERARBPROC)wglGetProcAddress("glBindBufferARB");
glBufferDataARB = (PFNGLBUFFERDATAARBPROC)wglGetProcAddress("glBufferDataARB");
glBufferSubDataARB = (PFNGLBUFFERSUBDATAARBPROC)wglGetProcAddress("glBufferSubDataARB");
glDeleteBuffersARB = (PFNGLDELETEBUFFERSARBPROC)wglGetProcAddress("glDeleteBuffersARB");
glGetBufferParameterivARB = (PFNGLGETBUFFERPARAMETERIVARBPROC)wglGetProcAddress("glGetBufferParameterivARB");
glMapBufferARB = (PFNGLMAPBUFFERARBPROC)wglGetProcAddress("glMapBufferARB");
glUnmapBufferARB = (PFNGLUNMAPBUFFERARBPROC)wglGetProcAddress("glUnmapBufferARB");
// check once again PBO extension
if (glGenBuffersARB && glBindBufferARB && glBufferDataARB && glBufferSubDataARB &&
glMapBufferARB && glUnmapBufferARB && glDeleteBuffersARB && glGetBufferParameterivARB)
{
pboSupported = true;
pboMode = 1; // using 1 PBO
cout << "Video card supports GL_ARB_pixel_buffer_object." << endl;
}
else
{
pboSupported = false;
pboMode = 0; // without PBO
cout << "Video card does NOT support GL_ARB_pixel_buffer_object." << endl;
}
}
// Query the system memory page size and update the default value
SYSTEM_INFO si;
GetSystemInfo(&si);
if (si.dwPageSize > 0)
{
systemPageSize = si.dwPageSize;
}
#elif defined (__gnu_linux__)
// for linux, do not need to get function pointers, it is up-to-date
if (glInfo.isExtensionSupported("GL_ARB_pixel_buffer_object"))
{
pboSupported = true;
cout << "Video card supports GL_ARB_pixel_buffer_object" << endl;
}
else
{
cout << "Video card does NOT support GL_ARB_pixel_buffer_object" << endl;
}
if (glInfo.isExtensionSupported("GL_AMD_pinned_memory"))
{
amdSupported = true;
cout << "Video card supports GL_AMD_pinned_memory" << endl;
}
else
{
cout << "Video card does NOT support GL_AMD_pinned_memory" << endl;
}
// Query the system memory page size and update the default value
if (sysconf(_SC_PAGE_SIZE) > 0)
{
systemPageSize = sysconf(_SC_PAGE_SIZE);
}
#endif创建PBO / 调整 PBO个数 的代码:
// 创建 count 个 PBO
void setPboCount(int count)
{
if (!pboSupported)
return;
// 如果 count 大于 当前的 PBO 数
if (count > pboCount)
{
if (pboMethod != AMD)
{
// Generate each Pixel Buffer object and allocate memory for it(生成 PBO,并为其分配内存)
// Hopefully, PBOs will get allocated in VRAM
glBindBuffer(GL_PIXEL_UNPACK_BUFFER, 0); // Unbind any buffer object previously bound(释放之前所绑定的 PBO)
for (int i = pboCount; i < count; ++i)
{
GLuint pboId;
glGenBuffers(1, &pboId); // Generate new Buffer Object ID
glBindBuffer(GL_PIXEL_UNPACK_BUFFER, pboId); // Create a zero-sized memory Pixel Buffer Object and bind it
glBufferData(GL_PIXEL_UNPACK_BUFFER, DATA_SIZE, NULL, GL_STREAM_DRAW); // Reserve the memory space for the PBO
glBindBuffer(GL_PIXEL_UNPACK_BUFFER, 0); // Release the PBO binding
pboIds.push_back(pboId); // Update our list of PBO IDs
pboFences.push_back(NULL);
cout << "Created PBO buffer #" << i << " of size: " << DATA_SIZE << endl;
}
pboCount = pboIds.size();
assert(GL_NO_ERROR == glGetError());
}
// 特殊的 DMA 模式,需要自己手动分配对齐的内存,并提供内存指针
else
{
// Generate each Pixel Buffer object and allocate memory for it
// PBOs will get allocated in System RAM, and GPU will access it through DMA
glBindBuffer(GL_EXTERNAL_VIRTUAL_MEMORY_BUFFER_AMD, 0); // Unbind any buffer object previously bound
for (int i = pboCount; i < count; ++i)
{
GLuint pboId;
glGenBuffers(1, &pboId); // Generate new Buffer Object ID
glBindBuffer(GL_EXTERNAL_VIRTUAL_MEMORY_BUFFER_AMD, pboId); // Create a zero-sized memory Pixel Buffer Object and bind it
assert(GL_NO_ERROR == glGetError());
// Memory alignment functions are compiler-specific
GLubyte *ptAlignedBuffer = (GLubyte *)alignedMalloc(systemPageSize, DATA_SIZE);
if (NULL == ptAlignedBuffer)
{
cout << "ERROR [setPboCount] (alignedMalloc) size: " << DATA_SIZE << " alignment: " << systemPageSize << endl;
break;
}
cout << "Created memory buffer #" << i << " of size: " << DATA_SIZE << " alignment: " << systemPageSize << endl;
glBufferData(GL_EXTERNAL_VIRTUAL_MEMORY_BUFFER_AMD, DATA_SIZE, ptAlignedBuffer, GL_STREAM_DRAW); // Take control of the memory space for the PBO
GLenum error = glGetError();
if (GL_NO_ERROR != error)
{
cout << "ERROR [setPboCount] (glBufferData): " << (char *)gluErrorString(error) << endl;
alignedFree(ptAlignedBuffer);
cout << "Freed memory buffer #" << i << endl;
break;
}
glBindBuffer(GL_EXTERNAL_VIRTUAL_MEMORY_BUFFER_AMD, 0); // Release the PBO binding
assert(GL_NO_ERROR == glGetError());
pboIds.push_back(pboId); // Update our list of PBO IDs
pboFences.push_back(NULL);
alignedBuffers.push_back((GLubyte *)ptAlignedBuffer);
cout << "Created PBO buffer #" << i << endl;
}
pboCount = pboIds.size();
assert(GL_NO_ERROR == glGetError());
}
}
// 如果 count 小于当前的 PBO 数
else if (count < pboCount)
{
if (pboMethod != AMD)
{
glBindBuffer(GL_PIXEL_UNPACK_BUFFER, 0); // Unbind any buffer object previously bound
for (int i = pboCount - 1; i >= count; --i)
{
glDeleteSync(pboFences.back());
pboFences.pop_back();
GLuint pboId = pboIds.back();
glDeleteBuffers(1, &pboId);
pboIds.pop_back(); // Update our list of PBO IDs
cout << "Deleted PBO buffer #" << i << endl;
}
pboCount = pboIds.size();
assert(GL_NO_ERROR == glGetError());
}
else
{
glBindBuffer(GL_EXTERNAL_VIRTUAL_MEMORY_BUFFER_AMD, 0); // Unbind any buffer object previously bound
for (int i = pboCount - 1; i >= count; --i)
{
glDeleteSync(pboFences.back());
pboFences.pop_back();
GLuint pboId = pboIds.back();
glDeleteBuffers(1, &pboId);
pboIds.pop_back(); // Update our list of PBO IDs
cout << "Deleted PBO buffer #" << i << endl;
// 手动释放自己分配的内存
alignedFree(alignedBuffers.back());
alignedBuffers.pop_back();
cout << "Freed memory buffer #" << i << endl;
}
pboCount = pboIds.size();
assert(GL_NO_ERROR == glGetError());
}
}
cout << "PBO Count: " << pboCount << endl;
}
最关键的显示回调方法:
void displayCB()
{
if (pboMethod == NONE)
{
/*
* Update data in System Memory.
*/
t1.start();
updatePixels(imageData, DATA_SIZE); // 更新 imageData 的像素
t1.stop();
updateTime = t1.getElapsedTimeInMilliSec();
/*
* Copy data from System Memory to texture object. (将 imageData 的内容从内存拷贝到纹理当中)
*/
t1.start();
glBindTexture(GL_TEXTURE_2D, textureId);
glTexSubImage2D(GL_TEXTURE_2D, 0, 0, 0, IMAGE_WIDTH, IMAGE_HEIGHT, PIXEL_FORMAT, GL_UNSIGNED_BYTE, (GLvoid *)imageData);
t1.stop();
copyTime = t1.getElapsedTimeInMilliSec();
}
else
{
/*
* Update buffer indices used in data upload & copy.
*
* "uploadIdx": index used to upload pixels to a Pixel Buffer Object.(上传像素至 uploadIdx 指定的 PBO)
* "copyIdx": index used to copy pixels from a Pixel Buffer Object to a GPU texture.(拷贝 cpyIdx 指定的 PBO 的像素到 GPU 纹理)
*
* When (pboCount > 1), this will allow to perform(当 pboCount 数大于1时,就允许使用备用buffer来同时进行上传和拷贝)
* simultaneous upload & copy, by using alternative buffers.
* That is a good thing, unless the double buffering is being already
* done somewhere else in the code.
*/
static int copyIdx = 0;
copyIdx = (copyIdx + 1) % pboCount;
int uploadIdx = (copyIdx + 1) % pboCount;
/*
* Upload new data to a Pixel Buffer Object.
*/
t1.start();
glBindBuffer(GL_PIXEL_UNPACK_BUFFER, pboIds[uploadIdx]); // Access the Pixel Buffer Object and bind it
// pboMethod 表示不同的纹理流机制(Texture Stream methods)
if (pboMethod == ORPHAN)
{
// GL_STREAM_DRAW 表示每次渲染都会更新该 PBO的像素数据
// GL_DYNAMITC_DRAW 表示每帧都会更新该 Buffer
// GL_STATIC_DRAW 表示几乎或从不更新该 Buffer
glBufferDataARB(GL_PIXEL_UNPACK_BUFFER_ARB, DATA_SIZE, NULL, GL_STREAM_DRAW_ARB);
// 获得 PBO 的映射 Buffer 指针,以待写入操作
GLubyte *ptr = (GLubyte *)glMapBufferARB(GL_PIXEL_UNPACK_BUFFER_ARB, GL_WRITE_ONLY_ARB);
if (NULL == ptr)
{
cout << "ERROR [displayCB] (glMapBufferARB): " << (char *)gluErrorString(glGetError()) << endl;
return;
}
else
{
// update data directly on the mapped buffer(在映射的 Buffer 上直接更新 PBO 的像素数据)
updatePixels(ptr, DATA_SIZE);
// release pointer to mapping buffer(释放映射 Buffer 的指针)
if (!glUnmapBufferARB(GL_PIXEL_UNPACK_BUFFER_ARB))
{
cout << "ERROR [displayCB] (glUnmapBufferARB): " << (char *)gluErrorString(glGetError()) << endl;
}
}
}
// 异步模式
else if (pboMethod == UNSYNCH_ORPHAN || pboMethod == UNSYNCH_FENCES)
{
if (pboMethod == UNSYNCH_FENCES)
{
// 检查索引的pboFences 是否是同步对象(Sync Object)
if (glIsSync(pboFences[uploadIdx]))
{
// 阻塞并 wait 同步对象,等待被 signal
GLenum result = glClientWaitSync(pboFences[uploadIdx], 0, GL_TIMEOUT_IGNORED);
switch (result)
{
case GL_ALREADY_SIGNALED:
// Transfer was already done when trying to use buffer
// (说明此时传输已经完成)
cout << "DEBUG (glClientWaitSync): ALREADY_SIGNALED (good timing!) uploadIdx: " << uploadIdx << endl;
break;
case GL_CONDITION_SATISFIED:
// This means that we had to wait for the fence to synchronize us after using all the buffers,
// which implies that the GPU command queue is full and that we are GPU-bound (DMA transfers aren't fast enough).
// (说明我们不得不等待 fence 的同步,即 我们所绑定的 GPU 命令队列已满[DMA传输还不够快])
cout << "WARNING (glClientWaitSync): CONDITION_SATISFIED (had to wait for the sync) uploadIdx: " << uploadIdx << endl;
break;
case GL_TIMEOUT_EXPIRED:
cout << "WARNING (glClientWaitSync): TIMEOUT_EXPIRED (DMA transfers are too slow!) uploadIdx: " << uploadIdx << endl;
break;
case GL_WAIT_FAILED:
cout << "ERROR (glClientWaitSync): WAIT_FAILED: " << (char *)gluErrorString(glGetError()) << endl;
break;
}
// 删除同步对象
glDeleteSync(pboFences[uploadIdx]);
pboFences[uploadIdx] = NULL;
}
}
// 注意和 ORPHAN 的区别
else if (pboMethod == UNSYNCH_ORPHAN)
{
// Buffer 需要重新指定
glBufferData(GL_PIXEL_UNPACK_BUFFER, DATA_SIZE, NULL, GL_STREAM_DRAW); // Buffer re-specification (orphaning)
}
// 获得 PBO 的映射 Buffer 指针,以待写入操作
GLubyte *ptr = (GLubyte *)glMapBufferRange(GL_PIXEL_UNPACK_BUFFER, 0, DATA_SIZE, GL_MAP_WRITE_BIT | GL_MAP_UNSYNCHRONIZED_BIT);
if (NULL == ptr)
{
cout << "ERROR [displayCB] (glMapBufferRange): " << (char *)gluErrorString(glGetError()) << endl;
return;
}
else
{
updatePixels(ptr, DATA_SIZE); // Update data directly on the mapped buffer(直接更新映射 Buffer 的数据)
if (!glUnmapBuffer(GL_PIXEL_UNPACK_BUFFER))
{
cout << "ERROR [displayCB] (glUnmapBuffer): " << (char *)gluErrorString(glGetError()) << endl;
}
}
}
else if (pboMethod == AMD)
{
// 同样要进行手动同步
if (glIsSync(pboFences[uploadIdx]))
{
GLenum result = glClientWaitSync(pboFences[uploadIdx], 0, GL_TIMEOUT_IGNORED);
switch (result)
{
case GL_ALREADY_SIGNALED:
// Transfer was already done when trying to use buffer
//cout << "DEBUG (glClientWaitSync): ALREADY_SIGNALED (good timing!) uploadIdx: " << uploadIdx << endl;
break;
case GL_CONDITION_SATISFIED:
// This means that we had to wait for the fence to synchronize us after using all the buffers,
// which implies that the GPU command queue is full and that we are GPU-bound (DMA transfers aren't fast enough).
//cout << "WARNING (glClientWaitSync): CONDITION_SATISFIED (had to wait for the sync) uploadIdx: " << uploadIdx << endl;
break;
case GL_TIMEOUT_EXPIRED:
cout << "WARNING (glClientWaitSync): TIMEOUT_EXPIRED (DMA transfers are too slow!) uploadIdx: " << uploadIdx << endl;
break;
case GL_WAIT_FAILED:
cout << "ERROR (glClientWaitSync): WAIT_FAILED: " << (char *)gluErrorString(glGetError()) << endl;
break;
}
glDeleteSync(pboFences[uploadIdx]);
pboFences[uploadIdx] = NULL;
}
// alignedBuffers 存储的是手动分配的一块对齐过的内存指针
updatePixels(alignedBuffers[uploadIdx], DATA_SIZE); // Update data directly on the mapped buffer
}
t1.stop();
updateTime = t1.getElapsedTimeInMilliSec();
/*
* Protect each Pixel Buffer Object against being overwritten.(防止 PBO 被重复写入)
*
* Tipically the data upload will be slower than our main loop, so this
* function will be called again before the previous frame was uploaded
* and processed. The main bottleneck is the PCI bus transfer speed,
* which limits how fast the DMA (System Memory --> VRAM) can work.
*
* 通常数据上传将会慢于主循环,意味着在先前的帧被上传处理之前,该方法将会被再次调用。
* 主要的性能瓶颈在于 PCI 总线的传输速度, 它限制了 DMA 的传输速度(内存到显存)。
*
* OpenGL Sync Fences will block until the PBO is released.(GL 同步对象将会阻塞主线程,直到 PBO 被释放为止)
*/
if (pboMethod == UNSYNCH_FENCES || pboMethod == AMD)
{
// 创建一个同步对象,并将其加入 GL 的命令流中(❤ 具体请参看第八版红宝书的 P589 第11章 Memory ❤)
pboFences[uploadIdx] = glFenceSync(GL_SYNC_GPU_COMMANDS_COMPLETE, 0);
}
/*
* Copy data from a Pixel Buffer Object to a GPU texture.
* glTexSubImage2D() will copy pixels to the corresponding texture in the GPU.
* 传输 PBO 中的数据到 GPU 纹理
*/
t1.start();
glBindTexture(GL_TEXTURE_2D, textureId); // Bind the texture
glBindBufferARB(GL_PIXEL_UNPACK_BUFFER_ARB, pboIds[copyIdx]); // Access the Pixel Buffer Object and bind it
// Use offset instead of pointer(由于使用了 PBO,所以传递的是偏移量)
glTexSubImage2D(GL_TEXTURE_2D, 0, 0, 0, IMAGE_WIDTH, IMAGE_HEIGHT, PIXEL_FORMAT, GL_UNSIGNED_BYTE, 0);
t1.stop();
copyTime = t1.getElapsedTimeInMilliSec();
// it is good idea to release PBOs with ID 0 after use.
// Once bound with 0, all pixel operations behave normal ways.
glBindBufferARB(GL_PIXEL_UNPACK_BUFFER_ARB, 0);
}
// clear buffer
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT | GL_STENCIL_BUFFER_BIT);
// save the initial ModelView matrix before modifying ModelView matrix
glPushMatrix();
// tramsform camera
glTranslatef(0, 0, -cameraDistance);
glRotatef(cameraAngleX, 1, 0, 0); // pitch
glRotatef(cameraAngleY, 0, 1, 0); // heading
// draw a point with texture
glBindTexture(GL_TEXTURE_2D, textureId);
glColor4f(1, 1, 1, 1);
glBegin(GL_QUADS);
glNormal3f(0, 0, 1);
glTexCoord2f(0.0f, 0.0f);
glVertex3f(-1.0f, -1.0f, 0.0f);
glTexCoord2f(1.0f, 0.0f);
glVertex3f(1.0f, -1.0f, 0.0f);
glTexCoord2f(1.0f, 1.0f);
glVertex3f(1.0f, 1.0f, 0.0f);
glTexCoord2f(0.0f, 1.0f);
glVertex3f(-1.0f, 1.0f, 0.0f);
glEnd();
// unbind texture
glBindTexture(GL_TEXTURE_2D, 0);
// draw info messages
showInfo();
//showTransferRate();
printTransferRate();
glPopMatrix();
glutSwapBuffers();
}运行结果对比:
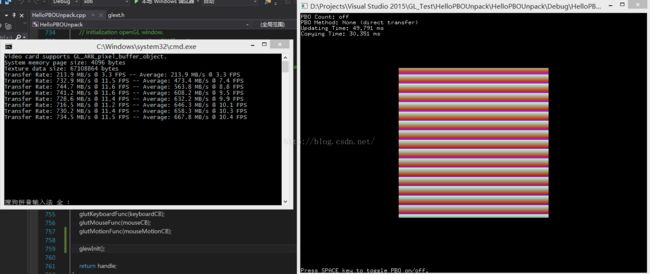
【未使用 PBO 的情况】
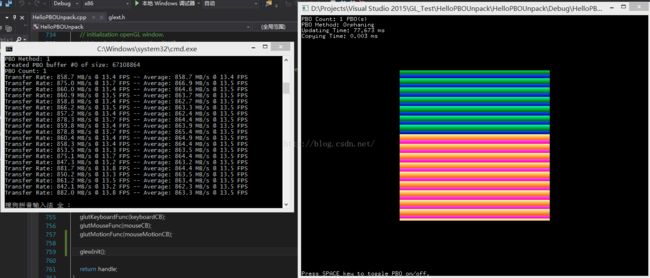
【Orphaning模式,PBO 个数 = 1】
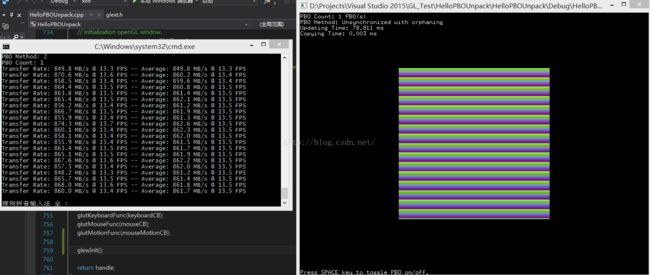
【异步 Orphaning模式, PBO个数 = 1】
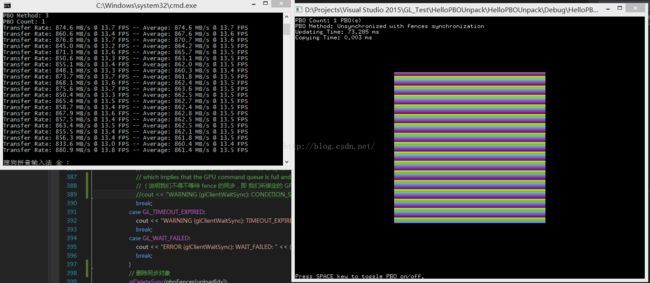
【Fences 的 同步模式, PBO个数 = 1】
【Orphaning模式, PBO个数=3】

【异步的 Orphaning 模式, PBO个数=3】

可见使用了 PBO 的确比未使用 PBO 性能要略优,但一味增加 PBO 的数量,并不能显著提高性能。
本例中 不同的 PBO 模式性能差别不大,但是 Orphan 模式的写法最简单,不需要自己手动同步和创建额外对齐的内存。