Oracle特有函数 decode, case when then, nvl, instr
decode函数

1、使用decode判断字符串是否一样
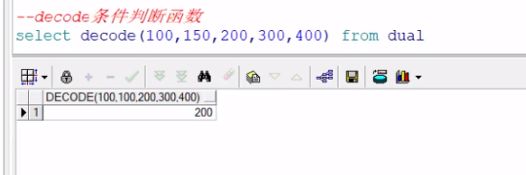
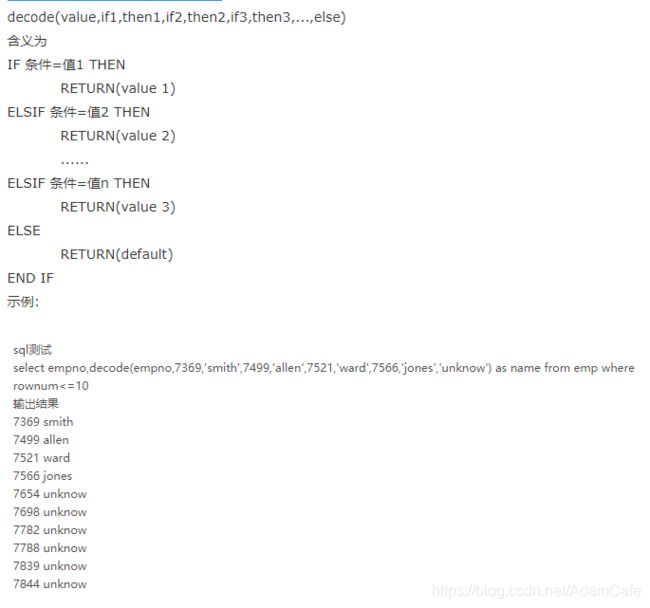
decode(X,A,B,C,D,E)
这个函数运行的结果是,当X = A,函数返回B;当X != A 且 X = C,函数返回D;当X != A 且 X != C,函数返回E。 其中,X、A、B、C、D、E都可以是表达式,这个函数使得某些sql语句简单了许多。
例如 :
decode (X,"1","张三",""2","李四","王五") as name;
x=1 name="张三",
x=2 name="李四"
x等于其他 name="王五"
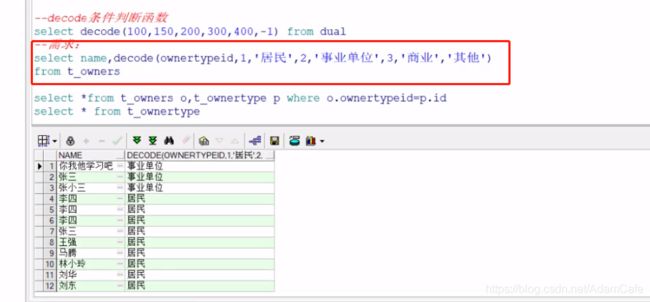
2、 使用decode函数比较大小

3、 使用decode函数分段

nvl函数 空值处理函数
1 nvl函数
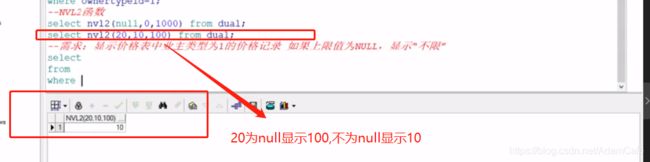
NVL(E1, E2)的功能为:如果E1为NULL,则函数返回E2,否则返回E1本身。


2 nvl2函数
NVL2(E1, E2, E3)的功能为:如果E1为NULL,则函数返回E3,否则返回E2。

instr函数
1 格式一:
instr(源字符串, 目标字符串)
1 select instr('helloworld','l') from dual; --返回结果:3 默认第一次出现“l”的位置 2 select instr('helloworld','lo') from dual; --返回结果:4 即:在“lo”中,“l”开始出现的位置
2 格式二:
instr(源字符串, 目标字符串, 起始位置, 匹配序号)
1 select instr('helloworld','l',2,2) from dual; --返回结果:4 也就是说:在"helloworld"的第2(e)号位置开始,查找第二次出现的“l”的位置
2 select instr('helloworld','l',3,2) from dual; --返回结果:4 也就是说:在"helloworld"的第3(l)号位置开始,查找第二次出现的“l”的位置
3 select instr('helloworld','l',4,2) from dual; --返回结果:9 也就是说:在"helloworld"的第4(l)号位置开始,查找第二次出现的“l”的位置
4 select instr('helloworld','l',-1,1) from dual; --返回结果:9 也就是说:在"helloworld"的倒数第1(d)号位置开始,往回查找第一次出现的“l”的位置
5 select instr('helloworld','l',-2,2) from dual; --返回结果:4 也就是说:在"helloworld"的倒数第2(l)号位置开始,往回查找第二次出现的“l”的位置
6 select instr('helloworld','l',2,3) from dual; --返回结果:9 也就是说:在"helloworld"的第2(e)号位置开始,查找第三次出现的“l”的位置
7 select instr('helloworld','l',-2,3) from dual; --返回结果:3 也就是说:在"helloworld"的倒数第2(l)号位置开始,往回查找第三次出现的“l”的位置
*
3 格式三: (重要)
MySQL中的模糊查询 like 和 Oracle中的 instr() 函数有同样的查询效果
select * from user u where 1=1
and instr(u.DETAIL_ORG_NAME,#{orgName,jdbcType=VARCHAR})>0
MySQL: select * from tableName where name like '%helloworld%';
Oracle:select * from tableName where instr(name,'helloworld')>0; --这两条语句的效果是一样的
工作中实际接触到的sql语句如下:
select project.PROJECT_ID as projectId,
project.PROJECT_NAME as projectName
from BDT_BUSINESS_PROJECT
where PROJECT_LIBRARY_LIBRARY_ID = '1'
and STATUS = '0'
and PROV_ORG_CODE =#{h_provOrgCode,jdbcType=VARCHAR}
and instr(PROJECT_NAME,#{projectName,jdbcType=VARCHAR})>0
#{respCenterLevel}
oracle中的case when then else end 用法
1 第一种写法
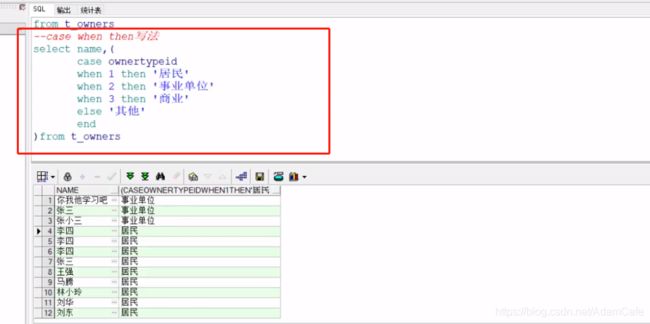
2 第二种写法
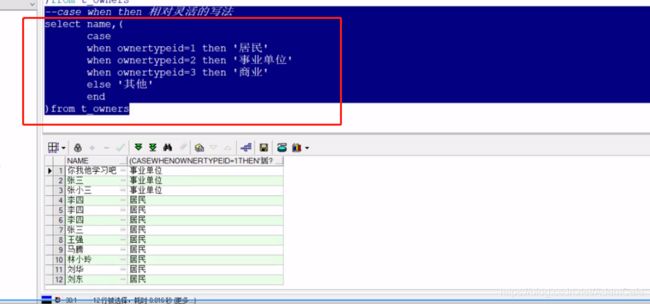
向oracle数据库某张表内添加新字段
如下图所示: