Redis集群之Redis-Cluster实践详解
Redis Cluster 官网地址:https://redis.io/topics/cluster-tutorial 。 本篇博文背景使用Redis 5.X,低版本的可能不太适用,具体参考官网。
需要注意的是,Redis5.0版本后才支持命令--cluster ,5.0版本前的Redis不支持该命令。。
【1】基础入门
Redis Cluster集群保证高可用但是不支持强一致性,具有自动切分数据集到多个节点上的能力,当部分节点宕机或无法通讯的情况下仍可继续处理命令。但是如果大部分节点挂掉,那么该集群就停止工作。
① Redis Cluster需要的TCP端口
每一个redis集群的节点需要开通两个TCP端口。一个是用于客户端的Redis TCP,如6379。另一个由客户端加10000所得,如16379,用于Redis集群总线连接。 这是一个用户 节点对节点的 二进制协议通讯通道。集群总线是用来处理节点的失效检测,配置更新,灾备授权等事情。
集群总线使用了一种不同的二进制协议,供节点和节点之间交换信息用。该协议可以让节点和节点之间以更小的流量和和更短的时间来交换信息。
② 数据是怎么在cluster中存放的
Redis集群用的不是基于哈希值的分片方式,用的是另一种不同的分片方式-hash slot。在该分片方式下所有键在概念上都是我们称之为哈希槽的一部分。
Redis集群有16384个哈希槽。当需要在 Redis 集群中放置一个 key-value 时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点。
Redis集群中的每个节点都存放了一些哈希槽。所以举例来说,比如你有3个节点:
节点A 保存了从 0 到 5500 的哈希槽
节点B 保存了从 5501 到 11000的哈希槽
节点C 保存了从 11001 到 16384 的哈希槽
这么做让集群增加或者减少节点变得很简单。比如我要增加一个节点D,我只需要从节点ABC移动一部分哈希槽到D。如果我要从节点中去除节点A,我只需要把节点A上的哈希槽移动到节点B或者C。当节点A的哈希槽被全部移走了之后,我就可以将它从节点中完全去除。
因为把哈希槽从一个节点移动到另外一个节点并不需要停止集群, 所以增加、删除节点或者在各节点间调整哈希槽的占有率的时候是不用停止集群的。Redis集群支持在一条命令里面对同一个哈希槽的多个键同时操作(或者在一个事务中,或者在一个lua脚本执行过程中)。
用户可以通过哈希标签强制的把多个键放到一个哈希槽里面。在Redis集群手册中可以查到哈希标签的相关说明, 不过归纳成一句话就是:当有在key里面写上段包含在{...}中的文字的时候,之后大括号{...}中的文字会被计算成哈希键。比如有两个key一个名叫 this{foo}key 另一个名叫 another{foo}key ,这两个key会被归纳到同一个哈希槽里面。这样这两个key就可以在一个命令中同时进行操作了。
③ Redis 集群主从模型
为了在部分节点失败或者无法通信的情况下集群仍然可用,Redis 集群采用了一种 主从模型。在该模型下每一个哈希槽都会被从master端复制N份到slave节点。在上面例子中有三个节点分别是ABC,如果节点B挂掉了,集群就无法继续工作,因为从5501到11000的哈希槽就没了。
不过如果当集群被创建的时候(迟些时候也可以)我们给每一个master节点增加一个slave从节点。模型变成这样:集群中有三个节点A,B,C,以及他们各自的从节点 A1,B1,C1,当节点B挂掉的时候,系统还可以正常运行。节点B1是用来做为节点B的镜像的。当节点B挂掉了,集群会选举B1作为新的master节点,并继续运行下去。不过要注意当节点B和节点B1都挂掉的时候,redis集群还是无法继续运行。
④ Redis 集群一致性保证
Redis 集群并不能保证数据的强一致性。在实际应用中这意味着在特定的情况下,就算Redis 集群告知客户端已经收到了写请求,这个写请求仍然有可能丢失。Redis集群之所以会丢失写请求的首要原因是:它采用了异步的复制机制。
在write的时候会经历以下的步骤:
你的客户端发送了一个写请求给master B 节点
master B 节点回复了一个OK给你的客户端。
master B 节点把这个写请求传播到它的 slave B1, B2, B3 节点上去。
正如你所见, B节点并不会等到B1,B2,B3节点都回复它之后才回复OK给客户端。因为这样会造成redis集群过高的延迟度。所以如果你的客户端正在写入,节点B告知你的客户端它收到了写请求,但是在它把这个写请求发送给它的slave节点们之前,节点B挂了,那么其中一个slave节点(假设它还没收到写请求)被选举为master那么你这个写请求就永久的丢失了。
Redis集群也支持同步写入(但是就会导致性能降低,需要在高性能和强一致性做权衡)。它通过实现WAIT命令来实现。这样一来基本不会丢失写操作。但是请注意就算你使用了同步复制,Redis集群也不能达到强一致性,因为总是会遇到某些更复杂的错误场景,比如一个slave节点在被选举为master的时候不能收到写请求命令。
还有一个需要注意的会丢失数据的情况。当进行一次网络网络分裂的时候某个客户端被分配到一个拥有很少节点的区域中的情况。
就拿我们的6节点例子(master是ABC,slave是A1,B1,C1),此时有一个客户端,我们称之为Z1。当网络分裂后,有可能有这种情况:现在有2方,一方是 A,C,A1,B1,C1,另一方是B和Z1。Z1依然可以写入B,而且B也会接受来自Z1的写请求。如果这次网络分裂在很短的时间内被修复, 集群依然会保持正常运行。 然而如果网络分裂持续了较长时间,长到足够B1在多数方被选举为master。那么Z1发送给B的写请求都会丢失。
注意, 在网络分裂出现期间, 客户端 Z1 可以向主节点 B 发送写命令的最大时间是有限制的, 这一时间限制称为节点超时时间(node timeout), 是 Redis 集群的一个重要的配置选项。
- 对于majority 一方来说, 如果一个主节点未能在节点超时时间所设定的时限内重新加入集群, 那么集群会将这个主节点视为下线, 并使用从节点替换掉。
- 对于minority 一方, 如果一个主节点未能在节点超时时间所设定的时限内重新联系上集群, 那么它将停止处理写命令, 并向客户端报告错误。
⑤ 集群配置一些参数
集群配置参数主要有:
cluster-enabled
cluster-config-file
cluster-node-timeout
cluster-slave-validity-factor
cluster-migration-barrier
cluster-require-full-coverage
详细解释如下:
cluster-enabled: 该项如果设置成yes,该实例支持redis集群。否则该实例会像往常一样以独立模式启动。cluster-config-file: 必须注意到尽管该项是可选的,这并不是一个用户可以编辑的配置文件,这是redis集群节点自动生成的配置文件,每次一旦配置有修改它都通过该配置文件来持久化配置(基本上都是状态),这样在下次启动的时候可以重新读取这些配置。该文件中列出了该集群中的其他节点的状态,持久化变量等信息。 当节点收到一些信息的时候该文件就会被冲重写。cluster-node-timeout: redis集群节点的最大超时时间。响应超过这个时间的话该节点会被认为是挂掉了。如果一个master节点超过一定的时候无法访问,它会被它的slave取代。 该参数在redis集群配置中很重要。很明显,当节点无法访问大部分master节点超过一定时间后,它会停止接受查询请求。cluster-slave-validity-factor:如果将该项设置为0,不管slave节点和master节点间失联多久都会一直尝试failover(设为正数,失联大于一定时间(factor*节点TimeOut),不再进行FailOver)。比如,如果节点的timeout设置为5秒,该项设置为10,如果master跟slave之间失联超过50秒,slave不会去failover它的master(意思是不会去把master设置为挂起状态,并取代它)。注意:任意非0数值都有可能导致当master挂掉又没有slave去failover它,这样redis集群不可用。在这种情况下只有原来那个master重新回到集群中才能让集群恢复工作。cluster-migration-barrier: 一个master可以拥有的最小slave数量。该项的作用是,当一个master没有任何slave的时候,某些有富余slave的master节点,可以自动的分一个slave给它。具体参见手册中的replica migration章节cluster-require-full-coverage: 如果该项设置为yes(默认就是yes) 当一定比例的键空间没有被覆盖到(就是某一部分的哈希槽没了,有可能是暂时挂了)集群就停止处理任何查询炒作。如果该项设置为no,那么就算请求中只有一部分的键可以被查到,一样可以查询(但是有可能会查不全)
【2】Redis Cluster部署
① 下载安装redis-5.0.4.tar.gz
不会安装的可以参考博文:CentOS7 下源码安装Redis并配置服务开机启动 ,注意这里只编译安装就可以,不需要做成服务开机启动。
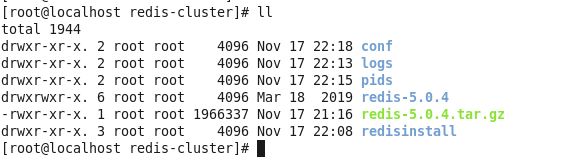
② 创建文件夹存放配置和日志以及pid等
目录如下所示,conf中存放不同redis实例的配置文件,logs存放不同redis实例的日志文件,pids存放不同实例的pid文件。redisinstall是第一步中redis的安装目录(/opt/redis-cluster/redisinstall)。
③ 编辑redis实例配置文件
Redis官网给了最小配置实例:
port 7000
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
这里进行修改,主要配置如下(可根据需要自行修改配置):
#bind 127.0.0.1
port 7000
daemonize yes
pidfile /opt/redis-cluster/pids/redis-7000.pid
logfile "/opt/redis-cluster/logs/redis-7000.log"
dbfilename dump-7000.rdb
appendonly yes
appendfilename "appendonly-7000.aof"
cluster-enabled yes
cluster-config-file nodes-7000.conf
cluster-node-timeout 15000
如下所示,可启动每个实例:
[root@localhost bin]# ./redis-server ../../conf/redis-7000.conf
[root@localhost bin]# ps -ef|grep redis
root 17809 1 0 22:11 ? 00:00:00 ./redis-server *:7000 [cluster]
root 17816 13225 0 22:11 pts/0 00:00:00 tail -f redis-7000.log
root 17852 11902 0 22:12 pts/1 00:00:00 grep redis
[root@localhost bin]# ./redis-server ../../conf/redis-7001.conf
[root@localhost bin]# ./redis-server ../../conf/redis-8000.conf
[root@localhost bin]# ./redis-server ../../conf/redis-8001.conf
[root@localhost bin]# ./redis-server ../../conf/redis-9000.conf
[root@localhost bin]# ./redis-server ../../conf/redis-9001.conf
再次查看redis的安装目录(/opt/redis-cluster/redisinstall/bin)bin目录如下:
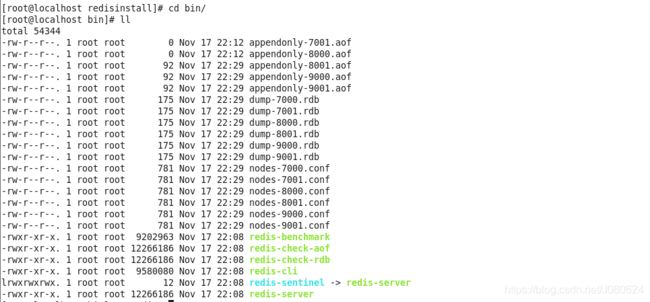
其中nodes-*.conf保存了对应实例的节点信息,内容如下所示(目前都是主):
//7000 实例
[root@localhost conf]# tail -f ../redisinstall/bin/nodes-7000.conf
2a470dfa7453c058ae5d92d67e8164026f4a3652 :0@0 myself,master - 0 0 0 connected
vars currentEpoch 0 lastVoteEpoch 0
//7001 实例
[root@localhost conf]# more ../redisinstall/bin/nodes-7001.conf
acbcd9e9ff52bf241608f5fbb6dfa081e99ca0db :0@0 myself,master - 0 0 0 connected
vars currentEpoch 0 lastVoteEpoch 0
//8000 实例
[root@localhost conf]# more ../redisinstall/bin/nodes-8000.conf
62b736242d1ed6f619ae13fbf90da5a737a44449 :0@0 myself,master - 0 0 0 connected
vars currentEpoch 0 lastVoteEpoch 0
//8001实例
[root@localhost conf]# more ../redisinstall/bin/nodes-8001.conf
c57cb1e504c386e7337eef47dd83278da802ea6f :0@0 myself,master - 0 0 0 connected
vars currentEpoch 0 lastVoteEpoch 0
//9000 实例
[root@localhost conf]# more ../redisinstall/bin/nodes-9000.conf
49913b6e8c220010d9f02c6b4df56f13cf7524e8 :0@0 myself,master - 0 0 0 connected
vars currentEpoch 0 lastVoteEpoch 0
// 9001 实例
[root@localhost conf]# more ../redisinstall/bin/nodes-9001.conf
6de2cdb208f73acd7de535a44c8c49f36fc4bdf9 :0@0 myself,master - 0 0 0 connected
vars currentEpoch 0 lastVoteEpoch 0
创建集群
./redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:8000 127.0.0.1:8001 127.0.0.1:9000 127.0.0.1:9001 --cluster-replicas 1
注意,这种方式创建的集群会自动选择从节点随机分配到一个主节点上。如果需要指定主从关系,下面再实践。如下是创建集群后的结果:

输入yes,表示接受:
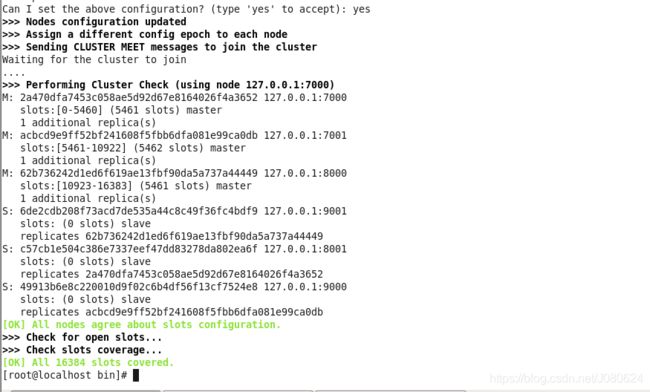
至此,集群就创建完成,从7000的日志可以看到8001作为其从节点。
【3】Redis Cluster 操作
① 查看集群信息
bin目录下执行如下命令:
./redis-cli -p 7000 cluster nodes
结果如下:
[root@localhost bin]# ./redis-cli -c -p 7000
127.0.0.1:7000> cluster nodes
49913b6e8c220010d9f02c6b4df56f13cf7524e8 127.0.0.1:9000@19000 master - 0 1574070202801 8 connected 5461-10922
c57cb1e504c386e7337eef47dd83278da802ea6f 127.0.0.1:8001@18001 master - 0 1574070201791 7 connected 0-5460
6de2cdb208f73acd7de535a44c8c49f36fc4bdf9 127.0.0.1:9001@19001 slave 62b736242d1ed6f619ae13fbf90da5a737a44449 0 1574070202000 6 connected
2a470dfa7453c058ae5d92d67e8164026f4a3652 127.0.0.1:7000@17000 myself,slave c57cb1e504c386e7337eef47dd83278da802ea6f 0 1574070199000 1 connected
acbcd9e9ff52bf241608f5fbb6dfa081e99ca0db 127.0.0.1:7001@17001 slave 49913b6e8c220010d9f02c6b4df56f13cf7524e8 0 1574070201000 8 connected
62b736242d1ed6f619ae13fbf90da5a737a44449 127.0.0.1:8000@18000 master - 0 1574070200000 3 connected 10923-16383
关于上面信息解释:
1. id: 节点ID,一个40字节的随机字符串,节点创建时生成,且不会变化(除非使用CLUSTER RESET HARD命令)。
2. ip:port: 客户端访问的地址。
3. flags: 逗号分隔的标记位,可能值有:myself, master, slave, fail?, fail, handshake, noaddr, noflags。
4. master -: 若是已知master节点的slave,这里出现的是master的节点ID,否则是"-"。或者是slave 对应的master_id
6. ping-sent: 最近一次发送ping的unix毫秒时间戳,0代表没有发送过。
7. pong-recv: 最近一次收到pong的unix毫秒时间戳。
8. config-epoch: 该节点或其master节点的epoch值。每次故障转移都会生成一个新的,唯一的,递增的epoch值。若多个节点竞争相同的slot,epoch值大的获胜。
9. link-state: 节点和集群总线间的连接状态,可以是connected或disconnected。
10. slot: 该节点负责的slot,只有master会有这个提示
其中flags字段各标记含义如下:
myself: 当前连接的节点。
master: 节点是master。
slave: 节点是slave。
fail?: 节点处于pfail状态,当前节点无法和其联系,但其它节点可以。
fail: 节点处于fail状态,大多数节点都无法和其联系,将其由pfail升级到fail状态。
handshake: 还没完全加入集群,正在握手阶段。
noaddr: 不知道节点地址。
noflags: 没有任何标记。
② 使用redis-cli操作cluster
查看 帮助命令redis-cli --cluster help,使用方式redis-cli --cluster 操作 操作选项,如redis-cli --cluster info 127.0.0.1:7000
redis-cli --cluster help
Cluster Manager Commands:
create host1:port1 ... hostN:portN #创建集群
--cluster-replicas #从节点个数
check host:port #检查集群
--cluster-search-multiple-owners #检查是否有槽同时被分配给了多个节点
info host:port #查看集群状态
fix host:port #修复集群
--cluster-search-multiple-owners #修复槽的重复分配问题
reshard host:port #指定集群的任意一节点进行迁移slot,重新分slots
--cluster-from #需要从哪些源节点上迁移slot,可从多个源节点完成迁移,以逗号隔开,传递的是节点的node id,还可以直接传递--from all,这样源节点就是集群的所有节点,不传递该参数的话,则会在迁移过程中提示用户输入
--cluster-to #slot需要迁移的目的节点的node id,目的节点只能填写一个,不传递该参数的话,则会在迁移过程中提示用户输入
--cluster-slots #需要迁移的slot数量,不传递该参数的话,则会在迁移过程中提示用户输入。
--cluster-yes #指定迁移时的确认输入
--cluster-timeout #设置migrate命令的超时时间
--cluster-pipeline #定义cluster getkeysinslot命令一次取出的key数量,不传的话使用默认值为10
--cluster-replace #是否直接replace到目标节点
rebalance host:port #指定集群的任意一节点进行平衡集群节点slot数量
--cluster-weight #指定集群节点的权重
--cluster-use-empty-masters #设置可以让没有分配slot的主节点参与,默认不允许
--cluster-timeout #设置migrate命令的超时时间
--cluster-simulate #模拟rebalance操作,不会真正执行迁移操作
--cluster-pipeline #定义cluster getkeysinslot命令一次取出的key数量,默认值为10
--cluster-threshold #迁移的slot阈值超过threshold,执行rebalance操作
--cluster-replace #是否直接replace到目标节点
add-node new_host:new_port existing_host:existing_port #添加节点,把新节点加入到指定的集群,默认添加主节点
--cluster-slave #新节点作为从节点,默认随机一个主节点
--cluster-master-id #给新节点指定主节点
del-node host:port node_id #删除给定的一个节点,成功后关闭该节点服务
call host:port command arg arg .. arg #在集群的所有节点执行相关命令
set-timeout host:port milliseconds #设置cluster-node-timeout
import host:port #将外部redis数据导入集群
--cluster-from #将指定实例的数据导入到集群
--cluster-copy #migrate时指定copy
--cluster-replace #migrate时指定replace
help
For check, fix, reshard, del-node, set-timeout you can specify the host and port of any working node in the cluster.
③ 移除一个节点
指定IP、端口和node_id 来删除一个节点,从节点可以直接删除,主节点不能直接删除,删除之后,该节点会被shutdown。
命令如下所示:
[root@localhost bin]# ./redis-cli --cluster del-node 127.0.0.1:7000 2a470dfa7453c058ae5d92d67e8164026f4a3652
>>> Removing node 2a470dfa7453c058ae5d92d67e8164026f4a3652 from cluster 127.0.0.1:7000
>>> Sending CLUSTER FORGET messages to the cluster...
>>> SHUTDOWN the node.
7000的日志文件如下所示:
19846:S 18 Nov 2019 02:00:16.347 # User requested shutdown...
19846:S 18 Nov 2019 02:00:16.347 * Saving the final RDB snapshot before exiting.
19846:S 18 Nov 2019 02:00:16.354 * DB saved on disk
19846:S 18 Nov 2019 02:00:16.354 * Removing the pid file.
19846:S 18 Nov 2019 02:00:16.354 # Redis is now ready to exit, bye bye...
//可以看到,退出前redis进行了数据保存操作。
④ 查看集群状态
命令如下:
[root@localhost bin]# ./redis-cli --cluster info 127.0.0.1:7001
127.0.0.1:8001 (c57cb1e5...) -> 3 keys | 5461 slots | 0 slaves.
127.0.0.1:8000 (62b73624...) -> 4 keys | 5461 slots | 1 slaves.
127.0.0.1:9000 (49913b6e...) -> 2 keys | 5462 slots | 1 slaves.
[OK] 9 keys in 3 masters.
0.00 keys per slot on average.
⑤ 检查集群
命令如下所示:
./redis-cli --cluster check 127.0.0.1:7001 --cluster-search-multiple-owners
测试结果如下:
[root@localhost bin]# ./redis-cli --cluster check 127.0.0.1:7001 --cluster-search-multiple-owners
127.0.0.1:8001 (c57cb1e5...) -> 3 keys | 5461 slots | 0 slaves.
127.0.0.1:8000 (62b73624...) -> 4 keys | 5461 slots | 1 slaves.
127.0.0.1:9000 (49913b6e...) -> 2 keys | 5462 slots | 1 slaves.
[OK] 9 keys in 3 masters.
0.00 keys per slot on average.
>>> Performing Cluster Check (using node 127.0.0.1:7001)
S: acbcd9e9ff52bf241608f5fbb6dfa081e99ca0db 127.0.0.1:7001
slots: (0 slots) slave
replicates 49913b6e8c220010d9f02c6b4df56f13cf7524e8
M: c57cb1e504c386e7337eef47dd83278da802ea6f 127.0.0.1:8001
slots:[0-5460] (5461 slots) master
S: 6de2cdb208f73acd7de535a44c8c49f36fc4bdf9 127.0.0.1:9001
slots: (0 slots) slave
replicates 62b736242d1ed6f619ae13fbf90da5a737a44449
M: 62b736242d1ed6f619ae13fbf90da5a737a44449 127.0.0.1:8000
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
M: 49913b6e8c220010d9f02c6b4df56f13cf7524e8 127.0.0.1:9000
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Check for multiple slot owners...
经过了系列操作后,再次查看几个节点配置文件信息如下所示:
[root@localhost bin]# more nodes-7000.conf
49913b6e8c220010d9f02c6b4df56f13cf7524e8 127.0.0.1:9000@19000 master - 0 1574061211979 8 connected 5461-10922
c57cb1e504c386e7337eef47dd83278da802ea6f 127.0.0.1:8001@18001 master - 0 1574061213000 7 connected 0-5460
6de2cdb208f73acd7de535a44c8c49f36fc4bdf9 127.0.0.1:9001@19001 slave 62b736242d1ed6f619ae13fbf90da5a737a44449 0 1574061210000 6 connected
2a470dfa7453c058ae5d92d67e8164026f4a3652 127.0.0.1:7000@17000 myself,slave c57cb1e504c386e7337eef47dd83278da802ea6f 0 1574061213000 1 connected
acbcd9e9ff52bf241608f5fbb6dfa081e99ca0db 127.0.0.1:7001@17001 slave 49913b6e8c220010d9f02c6b4df56f13cf7524e8 0 1574061213701 8 connected
62b736242d1ed6f619ae13fbf90da5a737a44449 127.0.0.1:8000@18000 master - 0 1574061213000 3 connected 10923-16383
vars currentEpoch 8 lastVoteEpoch 0
[root@localhost bin]# more nodes-7001.conf
2a470dfa7453c058ae5d92d67e8164026f4a3652 127.0.0.1:7000@17000 slave c57cb1e504c386e7337eef47dd83278da802ea6f 0 1574061213621 7 connected
c57cb1e504c386e7337eef47dd83278da802ea6f 127.0.0.1:8001@18001 master - 0 1574061213621 7 connected 0-5460
acbcd9e9ff52bf241608f5fbb6dfa081e99ca0db 127.0.0.1:7001@17001 myself,slave 49913b6e8c220010d9f02c6b4df56f13cf7524e8 0 1574061213612 2 connected
6de2cdb208f73acd7de535a44c8c49f36fc4bdf9 127.0.0.1:9001@19001 slave 62b736242d1ed6f619ae13fbf90da5a737a44449 0 1574061213621 6 connected
62b736242d1ed6f619ae13fbf90da5a737a44449 127.0.0.1:8000@18000 master - 0 1574061213621 3 connected 10923-16383
49913b6e8c220010d9f02c6b4df56f13cf7524e8 127.0.0.1:9000@19000 master - 0 1574061213621 8 connected 5461-10922
vars currentEpoch 8 lastVoteEpoch 7
[root@localhost bin]# more nodes-8000.conf
acbcd9e9ff52bf241608f5fbb6dfa081e99ca0db 127.0.0.1:7001@17001 slave 49913b6e8c220010d9f02c6b4df56f13cf7524e8 0 1574061213698 8 connected
6de2cdb208f73acd7de535a44c8c49f36fc4bdf9 127.0.0.1:9001@19001 slave 62b736242d1ed6f619ae13fbf90da5a737a44449 0 1574061213000 6 connected
49913b6e8c220010d9f02c6b4df56f13cf7524e8 127.0.0.1:9000@19000 master - 0 1574061213000 8 connected 5461-10922
2a470dfa7453c058ae5d92d67e8164026f4a3652 127.0.0.1:7000@17000 slave c57cb1e504c386e7337eef47dd83278da802ea6f 0 1574061213000 7 connected
c57cb1e504c386e7337eef47dd83278da802ea6f 127.0.0.1:8001@18001 master - 0 1574061213000 7 connected 0-5460
62b736242d1ed6f619ae13fbf90da5a737a44449 127.0.0.1:8000@18000 myself,master - 0 1574061213000 3 connected 10923-16383
vars currentEpoch 8 lastVoteEpoch 8
[root@localhost bin]# more nodes-8001.conf
62b736242d1ed6f619ae13fbf90da5a737a44449 127.0.0.1:8000@18000 master - 0 1574061211069 3 connected 10923-16383
49913b6e8c220010d9f02c6b4df56f13cf7524e8 127.0.0.1:9000@19000 master - 0 1574061213087 8 connected 5461-10922
acbcd9e9ff52bf241608f5fbb6dfa081e99ca0db 127.0.0.1:7001@17001 slave 49913b6e8c220010d9f02c6b4df56f13cf7524e8 0 1574061213699 8 connected
6de2cdb208f73acd7de535a44c8c49f36fc4bdf9 127.0.0.1:9001@19001 slave 62b736242d1ed6f619ae13fbf90da5a737a44449 0 1574061212080 6 connected
c57cb1e504c386e7337eef47dd83278da802ea6f 127.0.0.1:8001@18001 myself,master - 0 1574061213000 7 connected 0-5460
2a470dfa7453c058ae5d92d67e8164026f4a3652 127.0.0.1:7000@17000 slave c57cb1e504c386e7337eef47dd83278da802ea6f 0 1574061213000 7 connected
vars currentEpoch 8 lastVoteEpoch 8
[root@localhost bin]# more nodes-9000.conf
acbcd9e9ff52bf241608f5fbb6dfa081e99ca0db 127.0.0.1:7001@17001 slave 49913b6e8c220010d9f02c6b4df56f13cf7524e8 0 1574061213695 8 connected
49913b6e8c220010d9f02c6b4df56f13cf7524e8 127.0.0.1:9000@19000 myself,master - 0 1574061213000 8 connected 5461-10922
62b736242d1ed6f619ae13fbf90da5a737a44449 127.0.0.1:8000@18000 master - 0 1574061213000 3 connected 10923-16383
6de2cdb208f73acd7de535a44c8c49f36fc4bdf9 127.0.0.1:9001@19001 slave 62b736242d1ed6f619ae13fbf90da5a737a44449 0 1574061210283 3 connected
c57cb1e504c386e7337eef47dd83278da802ea6f 127.0.0.1:8001@18001 master - 0 1574061213393 7 connected 0-5460
2a470dfa7453c058ae5d92d67e8164026f4a3652 127.0.0.1:7000@17000 slave c57cb1e504c386e7337eef47dd83278da802ea6f 0 1574061213000 7 connected
vars currentEpoch 8 lastVoteEpoch 0
[root@localhost bin]# more nodes-9001.conf
6de2cdb208f73acd7de535a44c8c49f36fc4bdf9 127.0.0.1:9001@19001 myself,slave 62b736242d1ed6f619ae13fbf90da5a737a44449 0 1574061213000 6 connected
49913b6e8c220010d9f02c6b4df56f13cf7524e8 127.0.0.1:9000@19000 master - 0 1574061213000 8 connected 5461-10922
62b736242d1ed6f619ae13fbf90da5a737a44449 127.0.0.1:8000@18000 master - 0 1574061213000 3 connected 10923-16383
c57cb1e504c386e7337eef47dd83278da802ea6f 127.0.0.1:8001@18001 master - 0 1574061211375 7 connected 0-5460
acbcd9e9ff52bf241608f5fbb6dfa081e99ca0db 127.0.0.1:7001@17001 slave 49913b6e8c220010d9f02c6b4df56f13cf7524e8 0 1574061213697 8 connected
2a470dfa7453c058ae5d92d67e8164026f4a3652 127.0.0.1:7000@17000 slave c57cb1e504c386e7337eef47dd83278da802ea6f 0 1574061213393 7 connected
vars currentEpoch 8 lastVoteEpoch 0
【4】创建集群并手动指定主从关系
先把上面的环境清空,如删除pid/log/node等信息。
① 创建主节点集群
命令如下:
./redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:8000 127.0.0.1:9000
测试结果如下:
[root@localhost bin]# ./redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:8000 127.0.0.1:9000
>>> Performing hash slots allocation on 3 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
M: 558b5ed0195dfa34fecb5a06e30141a4c215939e 127.0.0.1:7000
slots:[0-5460] (5461 slots) master
M: 6ea417ccf44da7ce702b346d41952b259196be9f 127.0.0.1:8000
slots:[5461-10922] (5462 slots) master
M: 7f2189d54d4b3fd40da05d6f6698be12fe38f5a8 127.0.0.1:9000
slots:[10923-16383] (5461 slots) master
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
.
>>> Performing Cluster Check (using node 127.0.0.1:7000)
M: 558b5ed0195dfa34fecb5a06e30141a4c215939e 127.0.0.1:7000
slots:[0-5460] (5461 slots) master
M: 7f2189d54d4b3fd40da05d6f6698be12fe38f5a8 127.0.0.1:9000
slots:[10923-16383] (5461 slots) master
M: 6ea417ccf44da7ce702b346d41952b259196be9f 127.0.0.1:8000
slots:[5461-10922] (5462 slots) master
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
② 加入从节点并指定主节点
主从关系指定如下所示:
从----->主
7001-->7000
8001-->8000
9001-->9000
- 添加7001从节点指定到7000主节点上
./redis-cli --cluster add-node 127.0.0.1:7001 127.0.0.1:7000 --cluster-slave --cluster-master-id 558b5ed0195dfa34fecb5a06e30141a4c215939e
结果如下所示:
[root@localhost bin]# ./redis-cli --cluster add-node 127.0.0.1:7001 127.0.0.1:7000 --cluster-slave --cluster-master-id 558b5ed0195dfa34fecb5a06e30141a4c215939e
>>> Adding node 127.0.0.1:7001 to cluster 127.0.0.1:7000
>>> Performing Cluster Check (using node 127.0.0.1:7000)
M: 558b5ed0195dfa34fecb5a06e30141a4c215939e 127.0.0.1:7000
slots:[0-5460] (5461 slots) master
M: 7f2189d54d4b3fd40da05d6f6698be12fe38f5a8 127.0.0.1:9000
slots:[10923-16383] (5461 slots) master
M: 6ea417ccf44da7ce702b346d41952b259196be9f 127.0.0.1:8000
slots:[5461-10922] (5462 slots) master
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Send CLUSTER MEET to node 127.0.0.1:7001 to make it join the cluster.
Waiting for the cluster to join
..
>>> Configure node as replica of 127.0.0.1:7000.
[OK] New node added correctly.
分别使用命令查看当前集群状态:
//查看集群信息
./redis-cli --cluster info 127.0.0.1:7000
//检测集群
./redis-cli --cluster check 127.0.0.1:7001 --cluster-search-multiple-owners
结果如下所示:
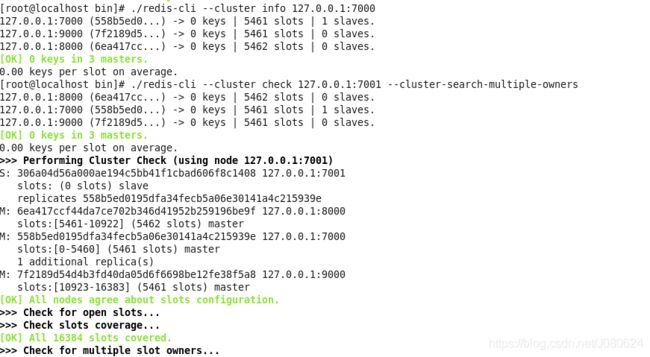
查看7001的日志如下所示:
# IP address for this node updated to 127.0.0.1
* Before turning into a replica, using my master parameters to synthesize a cached master: I may be able to synchronize with the new master with just a partial transfer.
# Cluster state changed: ok
* Connecting to MASTER 127.0.0.1:7000
* MASTER <-> REPLICA sync started
* Non blocking connect for SYNC fired the event.
* Master replied to PING, replication can continue...
* Trying a partial resynchronization (request 9bbb39d172a4464491448b5e49be1b6a01945585:1).
* Full resync from master: 915d80708067cfe1c1289adf2e7275c50e4bf78e:0
* Discarding previously cached master state.
* MASTER <-> REPLICA sync: receiving 175 bytes from master
* MASTER <-> REPLICA sync: Flushing old data
* MASTER <-> REPLICA sync: Loading DB in memory
* MASTER <-> REPLICA sync: Finished with success
* Background append only file rewriting started by pid 27688
* AOF rewrite child asks to stop sending diffs.
* Parent agreed to stop sending diffs. Finalizing AOF...
* Concatenating 0.00 MB of AOF diff received from parent.
* SYNC append only file rewrite performed
* AOF rewrite: 4 MB of memory used by copy-on-write
* Background AOF rewrite terminated with success
* Residual parent diff successfully flushed to the rewritten AOF (0.00 MB)
* Background AOF rewrite finished successfully
上面标明7001已经成功加入集群并作为7000的slaver,同样可以使用客户端命令测试如下:
[root@localhost bin]# ./redis-cli -c -p 7000
127.0.0.1:7000> keys *
(empty list or set)
127.0.0.1:7000> set k1 1
-> Redirected to slot [12706] located at 127.0.0.1:9000
OK
127.0.0.1:9000> set k2 2
-> Redirected to slot [449] located at 127.0.0.1:7000
OK
127.0.0.1:7000> exit
[root@localhost bin]# ./redis-cli -p 7001
127.0.0.1:7001> keys *
1) "k2"
127.0.0.1:7001>
- 添加8001从节点指定到8000主节点上
./redis-cli --cluster add-node 127.0.0.1:8001 127.0.0.1:8000 --cluster-slave --cluster-master-id 6ea417ccf44da7ce702b346d41952b259196be9f
- 添加9001从节点指定到9000主节点上
./redis-cli --cluster add-node 127.0.0.1:9001 127.0.0.1:9000 --cluster-slave --cluster-master-id 7f2189d54d4b3fd40da05d6f6698be12fe38f5a8
再次检查集群状态如下:
[root@localhost bin]# ./redis-cli --cluster check 127.0.0.1:7001 --cluster-search-multiple-owners
127.0.0.1:9000 (7f2189d5...) -> 1 keys | 5461 slots | 1 slaves.
127.0.0.1:8000 (6ea417cc...) -> 0 keys | 5462 slots | 1 slaves.
127.0.0.1:7000 (558b5ed0...) -> 1 keys | 5461 slots | 1 slaves.
[OK] 2 keys in 3 masters.
0.00 keys per slot on average.
>>> Performing Cluster Check (using node 127.0.0.1:7001)
S: 306a04d56a000ae194c5bb41f1cbad606f8c1408 127.0.0.1:7001
slots: (0 slots) slave
replicates 558b5ed0195dfa34fecb5a06e30141a4c215939e
S: a342ac4a22113e728825af905ca3c333d8f9f1ef 127.0.0.1:8001
slots: (0 slots) slave
replicates 6ea417ccf44da7ce702b346d41952b259196be9f
S: ed36b7098a0dfeee66dfc480d32bb40992b268f2 127.0.0.1:9001
slots: (0 slots) slave
replicates 7f2189d54d4b3fd40da05d6f6698be12fe38f5a8
M: 7f2189d54d4b3fd40da05d6f6698be12fe38f5a8 127.0.0.1:9000
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
M: 6ea417ccf44da7ce702b346d41952b259196be9f 127.0.0.1:8000
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
M: 558b5ed0195dfa34fecb5a06e30141a4c215939e 127.0.0.1:7000
slots:[0-5460] (5461 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Check for multiple slot owners...
[root@localhost bin]# ./redis-cli --cluster info 127.0.0.1:7000
127.0.0.1:7000 (558b5ed0...) -> 1 keys | 5461 slots | 1 slaves.
127.0.0.1:9000 (7f2189d5...) -> 1 keys | 5461 slots | 1 slaves.
127.0.0.1:8000 (6ea417cc...) -> 0 keys | 5462 slots | 1 slaves.
[OK] 2 keys in 3 masters.
0.00 keys per slot on average.
查看7000的节点配置文件(bin/nodes-7000.conf):
[root@localhost bin]# more nodes-7000.conf
7f2189d54d4b3fd40da05d6f6698be12fe38f5a8 127.0.0.1:9000@19000 master - 0 1574077063000 3 connected 10923-16383
306a04d56a000ae194c5bb41f1cbad606f8c1408 127.0.0.1:7001@17001 slave 558b5ed0195dfa34fecb5a06e30141a4c215939e 0 1574077064542 1 connected
ed36b7098a0dfeee66dfc480d32bb40992b268f2 127.0.0.1:9001@19001 slave 7f2189d54d4b3fd40da05d6f6698be12fe38f5a8 0 1574077065553 3 connected
558b5ed0195dfa34fecb5a06e30141a4c215939e 127.0.0.1:7000@17000 myself,master - 0 1574077062000 1 connected 0-5460
a342ac4a22113e728825af905ca3c333d8f9f1ef 127.0.0.1:8001@18001 slave 6ea417ccf44da7ce702b346d41952b259196be9f 0 1574077062526 2 connected
6ea417ccf44da7ce702b346d41952b259196be9f 127.0.0.1:8000@18000 master - 0 1574077063532 2 connected 5461-10922
vars currentEpoch 3 lastVoteEpoch 0
【5】5.0版本前集群操作
① 5.0版本前如何测试集群呢?
可以用如下命令:
redis-cli -h ip p port -c
ip:ip地址 port:端口号 -c 指定是集群模式连接