- GitHub上克隆项目
bigbig猩猩
github
从GitHub上克隆项目是一个简单且直接的过程,它允许你将远程仓库中的项目复制到你的本地计算机上,以便进行进一步的开发、测试或学习。以下是一个详细的步骤指南,帮助你从GitHub上克隆项目。一、准备工作1.安装Git在克隆GitHub项目之前,你需要在你的计算机上安装Git工具。Git是一个开源的分布式版本控制系统,用于跟踪和管理代码变更。你可以从Git的官方网站(https://git-scm.
- 01-Git初识
Meereen
Gitgit
01-Git初识概念:一个免费开源,分布式的代码版本控制系统,帮助开发团队维护代码作用:记录代码内容。切换代码版本,多人开发时高效合并代码内容如何学:个人本机使用:Git基础命令和概念多人共享使用:团队开发同一个项目的代码版本管理Git配置用户信息配置:用户名和邮箱,应用在每次提交代码版本时表明自己的身份命令:查看git版本号git-v配置用户名gitconfig--globaluser.name
- Kafka是如何保证数据的安全性、可靠性和分区的
喜欢猪猪
kafka分布式
Kafka作为一个高性能、可扩展的分布式流处理平台,通过多种机制来确保数据的安全性、可靠性和分区的有效管理。以下是关于Kafka如何保证数据安全性、可靠性和分区的详细解析:一、数据安全性SSL/TLS加密:Kafka支持SSL/TLS协议,通过配置SSL证书和密钥来加密数据传输,确保数据在传输过程中不会被窃取或篡改。这一机制有效防止了中间人攻击,保护了数据的安全性。SASL认证:Kafka支持多种
- WebMagic:强大的Java爬虫框架解析与实战
Aaron_945
Javajava爬虫开发语言
文章目录引言官网链接WebMagic原理概述基础使用1.添加依赖2.编写PageProcessor高级使用1.自定义Pipeline2.分布式抓取优点结论引言在大数据时代,网络爬虫作为数据收集的重要工具,扮演着不可或缺的角色。Java作为一门广泛使用的编程语言,在爬虫开发领域也有其独特的优势。WebMagic是一个开源的Java爬虫框架,它提供了简单灵活的API,支持多线程、分布式抓取,以及丰富的
- 华为云分布式缓存服务DCS 8月新特性发布
华为云PaaS服务小智
华为云分布式缓存
分布式缓存服务(DistributedCacheService,简称DCS)是华为云提供的一款兼容Redis的高速内存数据处理引擎,为您提供即开即用、安全可靠、弹性扩容、便捷管理的在线分布式缓存能力,满足用户高并发及数据快速访问的业务诉求。此次为大家带来DCS8月的特性更新内容,一起来看看吧!
- 浅谈MapReduce
Android路上的人
Hadoop分布式计算mapreduce分布式框架hadoop
从今天开始,本人将会开始对另一项技术的学习,就是当下炙手可热的Hadoop分布式就算技术。目前国内外的诸多公司因为业务发展的需要,都纷纷用了此平台。国内的比如BAT啦,国外的在这方面走的更加的前面,就不一一列举了。但是Hadoop作为Apache的一个开源项目,在下面有非常多的子项目,比如HDFS,HBase,Hive,Pig,等等,要先彻底学习整个Hadoop,仅仅凭借一个的力量,是远远不够的。
- KVM+GFS分布式存储系统构建KVM高可用
henan程序媛
分布式GFS高可用KVM
一、案列分析1.1案列概述本章案例主要使用之前章节所学的KVM及GlusterFs技术,结合起来从而实现KVM高可用。利用GlusterFs分布式复制卷,对KVM虚拟机文件进行分布存储和冗余。分布式复制卷主要用于需要冗余的情况下把一个文件存放在两个或两个以上的节点,当其中一个节点数据丢失或者损坏之后,KVM仍然能够通过卷组找到另一节点上存储的虚拟机文件,以保证虚拟机正常运行。当节点修复之后,Glu
- Hadoop
傲雪凌霜,松柏长青
后端大数据hadoop大数据分布式
ApacheHadoop是一个开源的分布式计算框架,主要用于处理海量数据集。它具有高度的可扩展性、容错性和高效的分布式存储与计算能力。Hadoop核心由四个主要模块组成,分别是HDFS(分布式文件系统)、MapReduce(分布式计算框架)、YARN(资源管理)和HadoopCommon(公共工具和库)。1.HDFS(HadoopDistributedFileSystem)HDFS是Hadoop生
- 【Death Note】网吧战神之7天爆肝渗透测试死亡笔记_sqlmap在默认情况下除了使用 char() 函数防止出现单引号
2401_84561374
程序员笔记
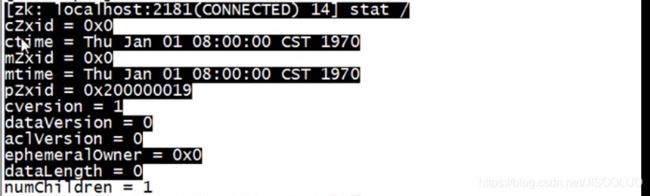
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。需要这份系统化的资料的朋友,可以戳这里获取一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!特殊服务端口2181zookeeper服务未授权访问
- 大模型训练数据库Common Crawl
WindyChanChan
数据集语言模型数据库
CommonCrawl介绍CommonCrawl是一个非营利组织,致力于通过大规模分布式爬虫系统定期抓取整个Web并将其存储在一个可公开访问的数据库中。CommonCrawl的数据收集和处理过程包括使用Python开源爬虫工具收集全球范围内的网站数据,并将其上传到CommonCrawl基金会的数据仓库中。该项目从2008年开始,至今已经积累了大量的原始网页数据、元数据和文本提取数据。这些数据
- 慢速连接攻击是什么?慢速连接攻击怎么防护?
快快小毛毛
网络ddos服务器
慢速连接攻击(SlowConnectionAttack),又称慢速攻击(SlowlorisAttack),是一种网络攻击技术,旨在通过占用服务器上的所有可用连接资源来使其无法响应正常请求。与传统的拒绝服务(DoS)和分布式拒绝服务(DDoS)攻击不同,慢速攻击并不依赖于发送大量数据包来消耗带宽,而是利用HTTP、TCP或SSL等协议的特性,通过发送大量不完整的请求或缓慢发送数据来占用服务器资源,使
- 分布式锁和spring事务管理
暴躁的鱼
锁及事务分布式springjava
最近开发一个小程序遇到一个需求需要实现分布式事务管理业务需求用户在使用小程序的过程中可以查看景点,对景点地区或者城市标记是否想去,那么需要统计一个地点被标记的人数,以及记录某个用户对某个地点是否标记为想去,用两个表存储数据,一个地点表记录改地点被标记的次数,一个用户意向表记录某个用户对某个地点是否标记为想去。由于可能有多个用户同时标记一个地点,每个用户在前端点击想去按钮之后,后台接收到请求,从数据
- Gobelieve 架构
weixin_34099526
数据库golangjson
Gobelievegithub地址声明:转简书JackieF的文章,为了自己方便copy了一份,加一些自己的东西.链接:https://www.jianshu.com/p/8121d6e85282IMCore主要分三大块:im客户连接服务器(可分布式部署,暂无负载均衡模块)imr路由查询服务器(主要解决im分布式部署的问题)ims存储服务器(主从部署)基础模块1.数据包协议包:header(12)
- Kafka详细解析与应用分析
芊言芊语
kafka分布式
Kafka是一个开源的分布式事件流平台(EventStreamingPlatform),由LinkedIn公司最初采用Scala语言开发,并基于ZooKeeper协调管理。如今,Kafka已经被Apache基金会纳入其项目体系,广泛应用于大数据实时处理领域。Kafka凭借其高吞吐量、持久化、分布式和可靠性的特点,成为构建实时流数据管道和流处理应用程序的重要工具。Kafka架构Kafka的架构主要由
- linux挂载文件夹
小码快撩
linux
1.使用NFS(NetworkFileSystem)NFS是一种分布式文件系统协议,允许一个系统将其文件系统的一部分共享给其他系统。检查是否安装NFSrpm-qa|grepnfs2.启动和启用NFS服务假设服务名称为nfs-server.service,你可以使用以下命令启动和启用它:sudosystemctlstartnfs-server.servicesudosystemctlenablenf
- Kafka 基础与架构理解
StaticKing
KAFKAkafka
目录前言Kafka基础概念消息队列简介:Kafka与传统消息队列(如RabbitMQ、ActiveMQ)的对比Kafka的组件Kafka的工作原理:消息的生产、分发、消费流程Kafka系统架构Kafka的分布式架构设计Leader-Follower机制与数据复制Log-basedStorage和持久化Broker间通信协议Zookeeper在Kafka中的角色总结前言Kafka是一个分布式的消息系
- Rides实现分布式锁,保障数据一致性,Redisson分布式事务处理
朱杰jjj
缓存分布式
分布式环境下分布式锁有三种方式:基于数据库分布式锁基于Redis分布式锁基于zk分布式锁本帖只介绍Redis分布式锁为什么需要用到分布式锁?在单机环境下一个服务中多个线程对同一个事物或数据资源进行操作时,可以通过添加加锁方式(synchronized和lock)来解决数据一致性的问题。但是如果出现多个服务的情况下,这时候我们在通过synchronized和lock的方式来加锁会出现问题,因为多个服
- 机电综合管理系统架构
小熊coder
机载系统系统架构
文章目录一、机电综合管理系统架构1.系统概述2.架构层次3.核心组件二、余度管理1.余度概述2.硬件冗余3.软件冗余4.通信冗余三、总线架构1.MIL-STD-1553B总线2.ARINC429总线3.ARINC629总线4.AFDX/ARINC664总线四、未来发展趋势1.分布式架构2.高速网络3.智能化与自动化结语机电综合管理系统(ElectromechanicalManagementSyst
- 华为云分布式缓存服务DCS与开源服务差异对比
hcinfo_18
redis使用华为云Redis5.0分布式缓存服务Redis客户端
分布式缓存服务DCS提供单机、主备、集群等丰富的实例类型,满足用户高读写性能及快速数据访问的业务诉求。支持丰富的实例管理操作,帮助用户省去运维烦恼。用户可以聚焦于业务逻辑本身,而无需过多考虑部署、监控、扩容、安全、故障恢复等方面的问题。DCS基于开源Redis、Memcached向用户提供一定程度定制化的缓存服务,因此,除了拥有开源服务缓存数据库的优秀特性,DCS提供更多实用功能。一、与开源Red
- Dubbo架构概览:服务注册与发现、远程调用、监控与管理
木南曌
dubbo架构
Dubbo是一个成熟的、高性能的、基于Java的微服务开发框架,它主要用于解决分布式系统中的服务治理问题,包括服务的注册与发现、远程过程调用(RPC)、服务监控与管理等多个关键环节。以下是Dubbo架构概览的详细介绍:服务注册与发现Dubbo的服务注册与发现机制是其核心功能之一,它依赖于注册中心来管理服务的生命周期和定位服务提供者。1.服务提供者(Provider)服务提供者是实际提供服务的节点,
- nfs服务搭建
GHope
nfs是什么?基哥度娘网络文件系统(NFS)是sun微系统最初开发的分布式文件系统协议,[1]允许客户端计算机上的用户通过计算机网络访问文件很像本地存储被访问。NFS与许多其他协议一样,在开放网络计算远程过程调用(很久以前RPC)系统上建立。NFS是在请求注释(RFC)中定义的开放标准,允许任何人实现协议。NFSNFS优势:节省本地存储空间,将常用的数据存放在一台NFS服务器上且可以通过网络访问,
- hbase介绍
CrazyL-
云计算+大数据hbase
hbase是一个分布式的、多版本的、面向列的开源数据库hbase利用hadoophdfs作为其文件存储系统,提供高可靠性、高性能、列存储、可伸缩、实时读写、适用于非结构化数据存储的数据库系统hbase利用hadoopmapreduce来处理hbase、中的海量数据hbase利用zookeeper作为分布式系统服务特点:数据量大:一个表可以有上亿行,上百万列(列多时,插入变慢)面向列:面向列(族)的
- Flume:大规模日志收集与数据传输的利器
傲雪凌霜,松柏长青
后端大数据flume大数据
Flume:大规模日志收集与数据传输的利器在大数据时代,随着各类应用的不断增长,产生了海量的日志和数据。这些数据不仅对业务的健康监控至关重要,还可以通过深入分析,帮助企业做出更好的决策。那么,如何高效地收集、传输和存储这些海量数据,成为了一项重要的挑战。今天我们将深入探讨ApacheFlume,它是如何帮助我们应对这些挑战的。一、Flume概述ApacheFlume是一个分布式、可靠、可扩展的日志
- 探索未来,大规模分布式深度强化学习——深入解析IMPALA架构
汤萌妮Margaret
探索未来,大规模分布式深度强化学习——深入解析IMPALA架构scalable_agent项目地址:https://gitcode.com/gh_mirrors/sc/scalable_agent在当今的人工智能研究前沿,深度强化学习(DRL)因其在复杂任务中的卓越表现而备受瞩目。本文要介绍的是一个开源于GitHub的重量级项目:“ScalableDistributedDeep-RLwithImp
- Docker安装Kafka和Kafka-Manager
阿靖哦
本文介绍如何通过Docker安装kafka与kafka界面管理界面一、拉取zookeeper由于kafka需要依赖于zookeeper,因此这里先运行zookeeper1、拉取镜像dockerpullwurstmeister/zookeeper2、启动dockerrun-d--namezookeeper-p2181:2181-eTZ="Asia/Shanghai"--restartalwayswu
- 主流行架构
rainbowcheng
架构架构
nexus,gitlab,svn,jenkins,sonar,docker,apollo,catteambition,axure,蓝湖,禅道,WCP;redis,kafka,es,zookeeper,dubbo,shardingjdbc,mysql,InfluxDB,Telegraf,Grafana,Nginx,xxl-job,Neo4j,NebulaGraph是一个高性能的,NOSQL图形数据库
- 等保测评中的关键技术挑战与应对策略
亿林数据
网络安全等保测评
在信息安全领域,等保测评(信息安全等级保护测评)作为确保信息系统安全性的重要手段,其过程中不可避免地会遇到一系列技术挑战。这些挑战不仅考验着企业的技术实力,也对其安全管理水平提出了更高要求。本文将深入探讨等保测评中的关键技术挑战,并提出相应的应对策略。一、等保测评中的关键技术挑战1.复杂系统架构的评估难度随着信息技术的快速发展,企业信息系统的架构日益复杂,包括分布式系统、微服务架构、云计算环境等。
- 系统架构师软考历年论文题目(2009-2024年)及分析
pccai-vip
系统架构师系统架构
时间题目20091.论基于DSSA的软件架构设计与应用;2.论信息系统建模方法;3.论基于REST服务的Web应用系统设计;4.论软件可靠性设计与应用20101.论软件的静态演化和动态演化及其应用;2.论数据挖掘技术的应用;3.论大规模分布式系统缓存设计策略;4.论软件可靠性评价20111.论模型驱动架构在系统开发中的应用;2.论企业集成平台的架构设计;3.论企业架构管理与应用;4.论软件需求获取
- 深入解析 Dubbo 的 attachments 机制及其应用场景
molashaonian
dubboattachments隐式传参
背景在分布式系统中,服务之间的调用(RPC调用)是非常常见的。而在这种服务调用过程中,常常需要在不同服务之间传递一些上下文信息,比如用户身份信息、请求追踪ID、客户端IP等。Dubbo提供的attachments机制,能够帮助开发者在RPC调用时隐式传递这些数据,而不需要修改接口方法签名。通过分析架构图,我们可以看到,在服务调用链路中,使用Dubbo的attachments机制可以简化上下文信息的
- 座舱交互的下一个时代
高工智能汽车
交互物联网人工智能
为了满足座舱信息娱乐的更高性能要求,几乎所有的一线品牌都在准备“换芯”。去年开始,不少车型开始推动传统的分布式座舱仪表和中控电子架构进入域控制器时代,高通成为大赢家。今年6月,特斯拉也正式官宣,即将推出的新款ModelS将配备能够运行PS5游戏机性能的AMD芯片,包括专门定制的AMDRyzenCPU和独立的Navi23图形处理器。最新消息,特斯拉将率先在中国市场生产的ModelY高性能版车型换装A
- java责任链模式
3213213333332132
java责任链模式村民告县长
责任链模式,通常就是一个请求从最低级开始往上层层的请求,当在某一层满足条件时,请求将被处理,当请求到最高层仍未满足时,则请求不会被处理。
就是一个请求在这个链条的责任范围内,会被相应的处理,如果超出链条的责任范围外,请求不会被相应的处理。
下面代码模拟这样的效果:
创建一个政府抽象类,方便所有的具体政府部门继承它。
package 责任链模式;
/**
*
- linux、mysql、nginx、tomcat 性能参数优化
ronin47
一、linux 系统内核参数
/etc/sysctl.conf文件常用参数 net.core.netdev_max_backlog = 32768 #允许送到队列的数据包的最大数目
net.core.rmem_max = 8388608 #SOCKET读缓存区大小
net.core.wmem_max = 8388608 #SOCKET写缓存区大
- php命令行界面
dcj3sjt126com
PHPcli
常用选项
php -v
php -i PHP安装的有关信息
php -h 访问帮助文件
php -m 列出编译到当前PHP安装的所有模块
执行一段代码
php -r 'echo "hello, world!";'
php -r 'echo "Hello, World!\n";'
php -r '$ts = filemtime("
- Filter&Session
171815164
session
Filter
HttpServletRequest requ = (HttpServletRequest) req;
HttpSession session = requ.getSession();
if (session.getAttribute("admin") == null) {
PrintWriter out = res.ge
- 连接池与Spring,Hibernate结合
g21121
Hibernate
前几篇关于Java连接池的介绍都是基于Java应用的,而我们常用的场景是与Spring和ORM框架结合,下面就利用实例学习一下这方面的配置。
1.下载相关内容: &nb
- [简单]mybatis判断数字类型
53873039oycg
mybatis
昨天同事反馈mybatis保存不了int类型的属性,一直报错,错误信息如下:
Caused by: java.lang.NumberFormatException: For input string: "null"
at sun.mis
- 项目启动时或者启动后ava.lang.OutOfMemoryError: PermGen space
程序员是怎么炼成的
eclipsejvmtomcatcatalina.sheclipse.ini
在启动比较大的项目时,因为存在大量的jsp页面,所以在编译的时候会生成很多的.class文件,.class文件是都会被加载到jvm的方法区中,如果要加载的class文件很多,就会出现方法区溢出异常 java.lang.OutOfMemoryError: PermGen space.
解决办法是点击eclipse里的tomcat,在
- 我的crm小结
aijuans
crm
各种原因吧,crm今天才完了。主要是接触了几个新技术:
Struts2、poi、ibatis这几个都是以前的项目中用过的。
Jsf、tapestry是这次新接触的,都是界面层的框架,用起来也不难。思路和struts不太一样,传说比较简单方便。不过个人感觉还是struts用着顺手啊,当然springmvc也很顺手,不知道是因为习惯还是什么。jsf和tapestry应用的时候需要知道他们的标签、主
- spring里配置使用hibernate的二级缓存几步
antonyup_2006
javaspringHibernatexmlcache
.在spring的配置文件中 applicationContent.xml,hibernate部分加入
xml 代码
<prop key="hibernate.cache.provider_class">org.hibernate.cache.EhCacheProvider</prop>
<prop key="hi
- JAVA基础面试题
百合不是茶
抽象实现接口String类接口继承抽象类继承实体类自定义异常
/* * 栈(stack):主要保存基本类型(或者叫内置类型)(char、byte、short、 *int、long、 float、double、boolean)和对象的引用,数据可以共享,速度仅次于 * 寄存器(register),快于堆。堆(heap):用于存储对象。 */ &
- 让sqlmap文件 "继承" 起来
bijian1013
javaibatissqlmap
多个项目中使用ibatis , 和数据库表对应的 sqlmap文件(增删改查等基本语句),dao, pojo 都是由工具自动生成的, 现在将这些自动生成的文件放在一个单独的工程中,其它项目工程中通过jar包来引用 ,并通过"继承"为基础的sqlmap文件,dao,pojo 添加新的方法来满足项
- 精通Oracle10编程SQL(13)开发触发器
bijian1013
oracle数据库plsql
/*
*开发触发器
*/
--得到日期是周几
select to_char(sysdate+4,'DY','nls_date_language=AMERICAN') from dual;
select to_char(sysdate,'DY','nls_date_language=AMERICAN') from dual;
--建立BEFORE语句触发器
CREATE O
- 【EhCache三】EhCache查询
bit1129
ehcache
本文介绍EhCache查询缓存中数据,EhCache提供了类似Hibernate的查询API,可以按照给定的条件进行查询。
要对EhCache进行查询,需要在ehcache.xml中设定要查询的属性
数据准备
@Before
public void setUp() {
//加载EhCache配置文件
Inpu
- CXF框架入门实例
白糖_
springWeb框架webserviceservlet
CXF是apache旗下的开源框架,由Celtix + XFire这两门经典的框架合成,是一套非常流行的web service框架。
它提供了JAX-WS的全面支持,并且可以根据实际项目的需要,采用代码优先(Code First)或者 WSDL 优先(WSDL First)来轻松地实现 Web Services 的发布和使用,同时它能与spring进行完美结合。
在apache cxf官网提供
- angular.equals
boyitech
AngularJSAngularJS APIAnguarJS 中文APIangular.equals
angular.equals
描述:
比较两个值或者两个对象是不是 相等。还支持值的类型,正则表达式和数组的比较。 两个值或对象被认为是 相等的前提条件是以下的情况至少能满足一项:
两个值或者对象能通过=== (恒等) 的比较
两个值或者对象是同样类型,并且他们的属性都能通过angular
- java-腾讯暑期实习生-输入一个数组A[1,2,...n],求输入B,使得数组B中的第i个数字B[i]=A[0]*A[1]*...*A[i-1]*A[i+1]
bylijinnan
java
这道题的具体思路请参看 何海涛的微博:http://weibo.com/zhedahht
import java.math.BigInteger;
import java.util.Arrays;
public class CreateBFromATencent {
/**
* 题目:输入一个数组A[1,2,...n],求输入B,使得数组B中的第i个数字B[i]=A
- FastDFS 的安装和配置 修订版
Chen.H
linuxfastDFS分布式文件系统
FastDFS Home:http://code.google.com/p/fastdfs/
1. 安装
http://code.google.com/p/fastdfs/wiki/Setup http://hi.baidu.com/leolance/blog/item/3c273327978ae55f93580703.html
安装libevent (对libevent的版本要求为1.4.
- [强人工智能]拓扑扫描与自适应构造器
comsci
人工智能
当我们面对一个有限拓扑网络的时候,在对已知的拓扑结构进行分析之后,发现在连通点之后,还存在若干个子网络,且这些网络的结构是未知的,数据库中并未存在这些网络的拓扑结构数据....这个时候,我们该怎么办呢?
那么,现在我们必须设计新的模块和代码包来处理上面的问题
- oracle merge into的用法
daizj
oraclesqlmerget into
Oracle中merge into的使用
http://blog.csdn.net/yuzhic/article/details/1896878
http://blog.csdn.net/macle2010/article/details/5980965
该命令使用一条语句从一个或者多个数据源中完成对表的更新和插入数据. ORACLE 9i 中,使用此命令必须同时指定UPDATE 和INSE
- 不适合使用Hadoop的场景
datamachine
hadoop
转自:http://dev.yesky.com/296/35381296.shtml。
Hadoop通常被认定是能够帮助你解决所有问题的唯一方案。 当人们提到“大数据”或是“数据分析”等相关问题的时候,会听到脱口而出的回答:Hadoop! 实际上Hadoop被设计和建造出来,是用来解决一系列特定问题的。对某些问题来说,Hadoop至多算是一个不好的选择,对另一些问题来说,选择Ha
- YII findAll的用法
dcj3sjt126com
yii
看文档比较糊涂,其实挺简单的:
$predictions=Prediction::model()->findAll("uid=:uid",array(":uid"=>10));
第一个参数是选择条件:”uid=10″。其中:uid是一个占位符,在后面的array(“:uid”=>10)对齐进行了赋值;
更完善的查询需要
- vim 常用 NERDTree 快捷键
dcj3sjt126com
vim
下面给大家整理了一些vim NERDTree的常用快捷键了,这里几乎包括了所有的快捷键了,希望文章对各位会带来帮助。
切换工作台和目录
ctrl + w + h 光标 focus 左侧树形目录ctrl + w + l 光标 focus 右侧文件显示窗口ctrl + w + w 光标自动在左右侧窗口切换ctrl + w + r 移动当前窗口的布局位置
o 在已有窗口中打开文件、目录或书签,并跳
- Java把目录下的文件打印出来
蕃薯耀
列出目录下的文件文件夹下面的文件目录下的文件
Java把目录下的文件打印出来
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
蕃薯耀 2015年7月11日 11:02:
- linux远程桌面----VNCServer与rdesktop
hanqunfeng
Desktop
windows远程桌面到linux,需要在linux上安装vncserver,并开启vnc服务,同时需要在windows下使用vnc-viewer访问Linux。vncserver同时支持linux远程桌面到linux。
linux远程桌面到windows,需要在linux上安装rdesktop,同时开启windows的远程桌面访问。
下面分别介绍,以windo
- guava中的join和split功能
jackyrong
java
guava库中,包含了很好的join和split的功能,例子如下:
1) 将LIST转换为使用字符串连接的字符串
List<String> names = Lists.newArrayList("John", "Jane", "Adam", "Tom");
- Web开发技术十年发展历程
lampcy
androidWeb浏览器html5
回顾web开发技术这十年发展历程:
Ajax
03年的时候我上六年级,那时候网吧刚在小县城的角落萌生。传奇,大话西游第一代网游一时风靡。我抱着试一试的心态给了网吧老板两块钱想申请个号玩玩,然后接下来的一个小时我一直在,注,册,账,号。
彼时网吧用的512k的带宽,注册的时候,填了一堆信息,提交,页面跳转,嘣,”您填写的信息有误,请重填”。然后跳转回注册页面,以此循环。我现在时常想,如果当时a
- 架构师之mima-----------------mina的非NIO控制IOBuffer(说得比较好)
nannan408
buffer
1.前言。
如题。
2.代码。
IoService
IoService是一个接口,有两种实现:IoAcceptor和IoConnector;其中IoAcceptor是针对Server端的实现,IoConnector是针对Client端的实现;IoService的职责包括:
1、监听器管理
2、IoHandler
3、IoSession
- ORA-00054:resource busy and acquire with NOWAIT specified
Everyday都不同
oraclesessionLock
[Oracle]
今天对一个数据量很大的表进行操作时,出现如题所示的异常。此时表明数据库的事务处于“忙”的状态,而且被lock了,所以必须先关闭占用的session。
step1,查看被lock的session:
select t2.username, t2.sid, t2.serial#, t2.logon_time
from v$locked_obj
- javascript学习笔记
tntxia
JavaScript
javascript里面有6种基本类型的值:number、string、boolean、object、function和undefined。number:就是数字值,包括整数、小数、NaN、正负无穷。string:字符串类型、单双引号引起来的内容。boolean:true、false object:表示所有的javascript对象,不用多说function:我们熟悉的方法,也就是
- Java enum的用法详解
xieke90
enum枚举
Java中枚举实现的分析:
示例:
public static enum SEVERITY{
INFO,WARN,ERROR
}
enum很像特殊的class,实际上enum声明定义的类型就是一个类。 而这些类都是类库中Enum类的子类 (java.l