PSPNet
一 引言
1.场景理解任务数据库
1.1 LMO dataset
C. Liu, J. Yuen, and A. Torralba. Nonparametric scene parsing:Label transfer via dense scene alignment. In CVPR, 2009.
1.2 PASCAL VOC
M. Everingham, L. J. V. Gool, C. K. I.Williams, J. M.Winn, and A. Zisserman. The pascal visual object classes VOC challenge. IJCV, 2010.
1.3 PASCAL context datasets
R. Mottaghi, X. Chen, X. Liu, N. Cho, S. Lee, S. Fidler, R. Urtasun, and A. L. Yuille. The role of context for object detection and semantic egmentation in the wild. In CVPR, 2014.
1.4 ADE20K dataset
B. Zhou, H. Zhao, X. Puig, S. Fidler, A. Barriuso, and A. Torralba. Semantic understanding of scenes through the ADE20K dataset. arXiv:1608.05442, 2016.
2.发现当今大多数基于FCN模型缺乏合适的策略去利用全局场景分类线索
3.除了用于像素预测的传统扩展FCN之外,我们还将像素级功能扩展到专门设计的全局金字塔池。 局部和全局线索一起使最终预测更可靠
4.我们还提出了一个具有深度监督损失的优化策略。
5.main contributions are threefold:
a.We propose a pyramid scene parsing network to embed difficult scenery context features in an FCN based pixel prediction framework
b.We develop an effective optimization strategy for deep ResNet based on deeply supervised loss
c.We build a practical system for state-of-the-art scene parsing and semantic segmentation where all crucial implementation details are included
二 重要观察
复杂场景解析的几个常见问题
1.不匹配关系:上下文关系普遍存在,特别是对复杂场景理解非常重要。存在共同视觉模式。例如,飞机一般在跑道或天空,而不是在路上。缺乏收集上下文信息的能力增加误分类的机会。
2.类别混淆:例如,field and earth; mountain and hill; wall, house, building and skyscraper.它们都有相同的外观。这些问题可以通过不同类别关系来解决。
3.不明显类别
总结这些问题,许多错误分类或多或少与上下文关系和不同感知野的全局信息有关,因此,对深度神经网络配置合适的全局场景级将有效改善场景分析表现。
三 Pyramid Pooling Module
1.在深度学习领域,感知野大小可以粗略地表示我们使用上下文信息的程度。但是,尽管理论上,ResNet的感知野大于输入图像,经验上CNN的感知野远小于理论上的感知野,特别实在深层神经网络中(B. Zhou, A. Khosla, A` . Lapedriza, A. Oliva, and A. Torralba. Object detectors emerge in deep scene cnns. arXiv:1412.6856, 2014.)。这使得许多神经网络没有充分利用重要的全局优先性质,我们提出一个有效的全局优先表示来解决这个问题。
2.GAP(global average pooling) 全局平均池是作为全局上下文先验的良好基线模型,其通常用于图像分类任务[34,13]。 在[24]中,它被成功应用于语义分割。 但是关于ADE20K [43]中的复杂图像,这一策略不足以覆盖必要的信息。
3.在(K. He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid pooling in deep convolutional networks for visual recognition. In ECCV, 2014.)中,由金字塔汇聚层产生的不同级别的特征图最终被平坦化并连接以被馈送到完全连接的层中进行分类。 该全局先验设计用于去除用于图像分类的CNN的固定大小约束。 为了进一步减少不同子区域之间的上下文信息丢失,我们提出了一种分层全局先验,包含不同尺度的信息,并且在不同的子区域之间变化。 在深层神经网络的最终特征图上,我们称之为全局场景金字塔池化模块。
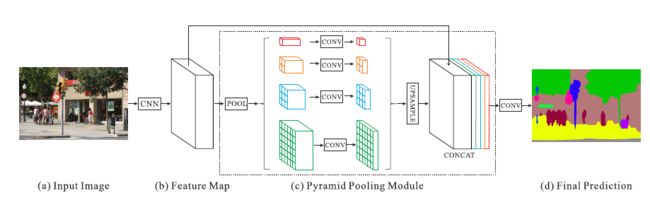
金字塔池化模块融合四种不同金字塔尺度特征。粗级别的用红色表示的,通过全局池化而产生一个单容器输出。其他金字塔层级分别构成不同子区域特征图,对不同位置形成池化表示。金字塔池化模块中不同层级的特征图尺寸不一,使用1*1卷积层降维,使用双线性插值获得原特征图相同大小,最后,不同层级的特征串联成最终金字塔池化全局特征。
四 网络架构
1. 使用带有扩张网络策略的预先训练的ResNet模型去提取特征,最终特征图大小维输入图像的1/8