Opencv图像分割之K-means聚类算法
kmeans是非常经典的聚类算法,至今也还保留着较强的生命力,图像处理中经常用到kmeans算法或者其改进算法进行图像分割操作,在数据挖掘中kmeans经常用来做数据预处理。opencv中提供了完整的kmeans算法,其函数原型为:
double kmeans( InputArray data, int K, InputOutputArray bestLabels, TermCriteria criteria, int attempts, int flags, OutputArray centers = noArray() );
其中data表示用于聚类的数据,是N维的数组类型(Mat型),必须浮点型;
K表示需要聚类的类别数;
bestLabels聚类后的标签数组,Mat型;
criteria迭代收敛准则(MAX_ITER最大迭代次数,EPS最高精度);
attemps表示尝试的次数,防止陷入局部最优;
flags 表示聚类中心的选取方式(KMEANS_RANDOM_CENTERS 随机选取,KMEANS_PP_CENTERS使用Arthur提供的算法,KMEANS_USE_INITIAL_LABELS使用初始标签);
centers 表示聚类后的类别中心。
关于kmeans的理论可以参考:基本Kmeans算法介绍及其实现
kmeans算法过程与简单的理解:
K-Means#####
聚类算法有很多种(几十种),K-Means是聚类算法中的最常用的一种,算法最大的特点是简单,好理解,运算速度快,但是只能应用于连续型的数据,并且一定要在聚类前需要手工指定要分成几类。
下面,我们描述一下K-means算法的过程,为了尽量不用数学符号,所以描述的不是很严谨,大概就是这个意思,“物以类聚、人以群分”:
- 首先输入k的值,即我们希望将数据集经过聚类得到k个分组。
- 从数据集中随机选择k个数据点作为初始大哥(质心,Centroid)
- 对集合中每一个小弟,计算与每一个大哥的距离(距离的含义后面会讲),离哪个大哥距离近,就跟定哪个大哥。
- 这时每一个大哥手下都聚集了一票小弟,这时候召开人民代表大会,每一群选出新的大哥(其实是通过算法选出新的质心)。
- 如果新大哥和老大哥之间的距离小于某一个设置的阈值(表示重新计算的质心的位置变化不大,趋于稳定,或者说收敛),可以认为我们进行的聚类已经达到期望的结果,算法终止。
- 如果新大哥和老大哥距离变化很大,需要迭代3~5步骤。
简单的手算例子#####
我搞了6个点,从图上看应该分成两推儿,前三个点一堆儿,后三个点是另一堆儿。现在手工执行K-Means,体会一下过程,同时看看结果是不是和预期一致。

1.选择初始大哥:
我们就选P1和P2
2.计算小弟和大哥的距离:
P3到P1的距离从图上也能看出来(勾股定理),是√10 = 3.16;P3到P2的距离√((3-1)2+(1-2)2 = √5 = 2.24,所以P3离P2更近,P3就跟P2混。同理,P4、P5、P6也这么算,如下:

P3到P6都跟P2更近,所以第一次站队的结果是:
- 组A:P1
- 组B:P2、P3、P4、P5、P6
3.人民代表大会:
组A没啥可选的,大哥还是P1自己
组B有五个人,需要选新大哥,这里要注意选大哥的方法是每个人X坐标的平均值和Y坐标的平均值组成的新的点,为新大哥,也就是说这个大哥是“虚拟的”。
因此,B组选出新大哥的坐标为:P哥((1+3+8+9+10)/5,(2+1+8+10+7)/5)=(6.2,5.6)。
综合两组,新大哥为P1(0,0),P哥(6.2,5.6),而P2-P6重新成为小弟
4.再次计算小弟到大哥的距离:
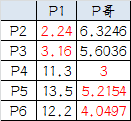
这时可以看到P2、P3离P1更近,P4、P5、P6离P哥更近,所以第二次站队的结果是:
- 组A:P1、P2、P3
- 组B:P4、P5、P6(虚拟大哥这时候消失)
5.第二届人民代表大会:
按照上一届大会的方法选出两个新的虚拟大哥:P哥1(1.33,1) P哥2(9,8.33),P1-P6都成为小弟
6.第三次计算小弟到大哥的距离:
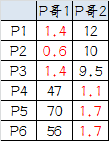
这时可以看到P1、P2、P3离P哥1更近,P4、P5、P6离P哥2更近,所以第二次站队的结果是:
- 组A:P1、P2、P3
- 组B:P4、P5、P6
我们发现,这次站队的结果和上次没有任何变化了,说明已经收敛,聚类结束,聚类结果和我们最开始设想的结果完全一致。
下面放上基于Opencv的代码:
#include
#include
using namespace cv;
using namespace std;
int main()
{
Mat srcImage = imread("girl1.jpg");
if (!srcImage.data)
{
printf("could not load image...\n");
return -1;
}
imshow("girl1.jpg", srcImage);
//五个颜色,聚类之后的颜色随机从这里面选择
Scalar colorTab[] = {
Scalar(0,0,255),
Scalar(0,255,0),
Scalar(255,0,0),
Scalar(0,255,255),
Scalar(255,0,255)
};
int width = srcImage.cols;//图像的宽
int height = srcImage.rows;//图像的高
int channels = srcImage.channels();//图像的通道数
//初始化一些定义
int sampleCount = width*height;//所有的像素
int clusterCount = 4;//分类数
Mat points(sampleCount, channels, CV_32F, Scalar(10));//points用来保存所有的数据
Mat labels;//聚类后的标签
Mat center(clusterCount, 1, points.type());//聚类后的类别的中心
//将图像的RGB像素转到到样本数据
int index;
for (int i = 0; i < srcImage.rows; i++)
{
for (int j = 0; j < srcImage.cols; j++)
{
index = i*width + j;
Vec3b bgr = srcImage.at(i, j);
//将图像中的每个通道的数据分别赋值给points的值
points.at(index, 0) = static_cast(bgr[0]);
points.at(index, 1) = static_cast(bgr[1]);
points.at(index, 2) = static_cast(bgr[2]);
}
}
//运行K-means算法
//MAX_ITER也可以称为COUNT最大迭代次数,EPS最高精度,10表示最大的迭代次数,0.1表示结果的精确度
TermCriteria criteria = TermCriteria(TermCriteria::EPS + TermCriteria::COUNT,10,0.1);
kmeans(points, clusterCount, labels, criteria, 3, KMEANS_PP_CENTERS, center);
//显示图像分割结果
Mat result = Mat::zeros(srcImage.size(), srcImage.type());//创建一张结果图
for (int i = 0; i < srcImage.rows; i++)
{
for (int j = 0; j < srcImage.cols; j++)
{
index = i*width + j;
int label = labels.at(index);//每一个像素属于哪个标签
result.at(i, j)[0] = colorTab[label][0];//对结果图中的每一个通道进行赋值
result.at(i, j)[1] = colorTab[label][1];
result.at(i, j)[2] = colorTab[label][2];
}
}
imshow("Kmeans", result);
waitKey(0);
return 0;
} 原图:

效果图:
