【温故知新】-JVM相关知识点梳理
1.jvm内存模型
老规矩,还是看图说话,jvm的内存模型如图(网图):
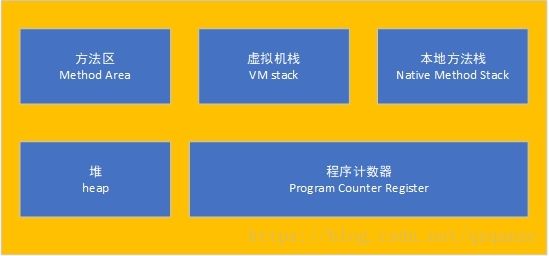
jvm的内存分为五个部分:
java虚拟机栈:线程私有,用于存放局部变量,方法的出口,动态链接等信息,每一个方法的调用就对应一个栈帧在虚拟机中从入栈到出栈的过程. 如果线程请求的栈的深度超过jvm所允许的最大深度,则会抛出stackOverFlowError,常见的比如递归方法没有出口,就会导致stackOverFlowError.
本地方法栈:线程私有,与虚拟机栈类似,不同的是本地方法栈是用于存储虚拟机所调用的本地方法所需信息,同样也会抛出stackOverFlowError
程序计数器:线程私有,用于存储线程的字节码指令,控制程序的执行,确保线程上下文切换后能够从正确的位置开始执行.
堆:线程共享,用于存放对象实例,垃圾回收主要发生在堆区,堆空间如果内存不足,会抛出OutOfMeoryError.
方法区:线程共享,用于存放已被虚拟机加载的类的信息以及static关键字修饰的静态变量,常量池等. 在JDK1.8之前对应永久代PermGen,JDK1.8以后对应元空间MetaSpace,是属于堆外内存,不受jvm内存空间限制.
2.java类加载机制
jvm的类加载顺序如图所示,包含加载->连接(验证,准备,解析)->初始化->使用->卸载五个步骤.

加载:将编译后的.class字节码文件通过classLoader装载到Jvm中.
连接:
- 验证:验证.class是否合乎Jvm规范,避免加载对jvm造成损害.
- 准备:为类变量(static修饰的成员变量)分配内存并设置变量初始值(如零值,False等),所需内存主要在方法区中分配.
- 解析:把常量池内的符号引用替换为直接应用,符号引用是指代码中的字面量,可以是任意形式的字面量,只要能唯一定位到常量即可,直接引用则是指向该常量的指针,或是能间接定位到目标的句柄。
初始化:对类变量(static修饰的成员变量)进行赋值,前面准备阶段仅是对变量设置一个初始值,变量真正的值是在初始化阶段进行赋值的,通过收集静态代码块,显式的赋值语句对类变量进行赋值.
划重点,什么时候才必须对类进行初始化?一共有5种情况:
- 直接使用new创建类的实例
- 访问某个类或接口的静态变量或对其赋值
- 调用类的静态方法
- 反射
- 初始化某个类的子类,其父类也会被初始化
使用:对类的使用,没啥好说的
卸载:也没啥好说的,就是把类从jvm中卸载,避免占用方法区内存.
类加载模型:双亲委派模型

类的加载不会优先使用自定义的类加载器,而是优先选择其父类的类加载器进行加载,当其父类的类加载器不能处理,则向上找,直到bootstrap类加载器,若还不能加载,才会使用自定义的类加载器,以此来保证内存中同样的类的字节码仅出现一份.
3.线程
线程的两种创建方式:继承Thread类或者实现Runnable方法,但都不推荐,推荐使用线程池.
线程池的创建方式:可以通过JDK自带的Executors类提供的创建各种线程池的方法创建,不推荐,一般演示或者测试时可以用,推荐手动创建线程池,指定核心线程数,最大线程数等参数.
调用Thread类的run()方法和start()方法有何不同?
调run方法仅仅就只是执行了Thread类中的run方法而已,并没有启动新的线程,本质只是调用了一个方法,调start方法会新启动一个线程,然后执行run方法中的逻辑.
线程sleep和wait有什么区别?
Sleep是Thread的方法,Wait是Object的方法; Sleep和Wait都会释放Cpu资源,不同的是Sleep并不释放锁,但Wait会释放锁,进入锁池等待;Sleep可以通过指定时间来唤醒,Wait需要通过Notify/NotifyAll来唤醒.
如果需要指定唤醒,可以使用ReentrantLock提供的condition.await和singinal来实现.
多线程带来的线程不安全问题可以通过volatile关键字,synchronized,Lock以及CAS锁来解决,不再赘述.
4.JVM运行时内存

Jvm运行时的内存主要分为堆区和非堆区(永久代PermGen,Jdk1.8后为元空间MetaSpace)
堆区主要由Young区和Old区组成,Young区细分为两块等大的servivor区和Eden区.
6.JAVA的四种引用类型
- 虚引用 引用不存在,最弱的一种引用,如果一个对象仅持有虚引用,可以随时被垃圾回收
- 弱引用 引用关系比较弱,无论内存是否够用,只要垃圾回收器进行垃圾回收就会被回收,可以用java.lang.ref.WeakReference来表示弱引用.
- 软引用 引用关系比弱引用略强,在内存不足的情况下,软引用对象才会被垃圾回收,因此常被用来做本地缓存,可以用java.lang.ref.SoftReference来表示软引用.
- 强引用 引用关系最强,除非显示将引用关系置为null,否则将永远不会被垃圾回收.
7.GC回收算法
标记-清除算法(mark-sweep): 标记清除算法分为两个步骤,第一步是标记出所有需要被清除的对象,第二步是清理,清理掉标记为被清除的对象. 优点是实现容易,缺点也比较明显,容易产生内存碎片,回收后的内存空间不连续,容易导致下次内存分配时没有连续物理内存空间而再次触发GC;
复制算法(copy) :复制算法的就是为了解决标记清除算法带来的碎片问题,

回收后=>

主要发生在Young区的Sevivor区,S区分为两块等大的S0和S1区,每次回收前先将其中一块区域的存活对象复制到另一块区域,然后把该区域清空,如此循环往复.优点是实现简单,不会产生内存碎片,缺点是浪费内存空间,如果存活对象较多,复制的对象会比较多,影响效率.
标记整理算法(mark-compact):复制算法虽然解决了碎片问题,但对于存活对象较多的情况,效率比较低,所以只适合在新生代使用,对于老年代,标记整理算法更为适合,标记整理算法第一步也是标记出需要被清除的对象,第二步是所有标记为存活的对象的往一端移动,然后清理边界以外的内存

分代收集算法(Generational Collection): 分代回收算法是目前大部分Jvm垃圾回收器采用的算法,由于不同代的对象存活特点不一样,所以采用组合的方式,对不同代采用不同的垃圾回收算法,可以提高垃圾回收效率.所以新生代一般采用复制算法,老年代一般采用标记整理算法.
8.GC垃圾回收器
Serial GC:串行的垃圾回收器,采用复制算法,主要发生在新生代,对应的发生与老年代的是Serial old,采用标记整理算法,Serial GC 出现于较早的Jdk版本中,适用于单核cpu的机器,现在几乎不怎么用了。
ParNew,Parallel Old:是Serial GC的多线程版,在多核cpu下比SerialGC有更好的表现。
Parallel Scavenge:是一款专注于吞吐量的垃圾回收器,适用于多核cpu且对暂停时间没有特别高要求的场景,比如后台在跑的一些批量任务.
CMSGC:并发的垃圾回收器,专注于低暂停时间,几乎可以与程序同时工作,适合多核cpu且对系统延迟有较高要求的场景.诟病是由于在Old区采用标记清除算法,清理完后为了减少暂停,没有对清理后的内存空间进行压缩,会产生内存碎片.
G1GC:G1GC是jdk1.7之后出现的一款垃圾回收器,采用全新的理念,是目前我用过最好用的垃圾回收器(shenandoah和zgc除外),所以这里重点介绍.
看了大量的G1GC相关文章,说实话G1GC的相关知识点还是比较难懂,而且涵盖量也很大,一个在orecal实验室孵化了近8年的产品,其复杂性可想而知,这里篇幅原因以及个人水平有限,所以只聊重点,如有不正之处感谢指正!
G1GC将jvm的内存区域划分为逻辑上连续且等大的多个region(块),每个region最大小可以手动设置,最小1M,最大32M,如果不设置,则由jvm自动算出.
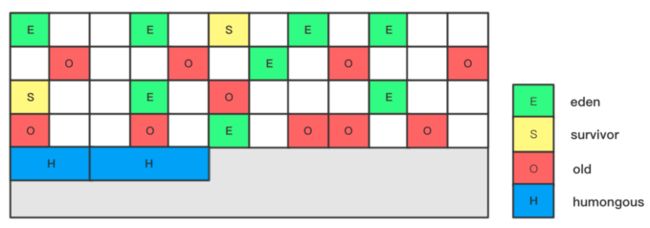
先介绍几个概念,RememberSet,CollectionSet,Snapshot at the begining.
RememberSet:在Region初始化时会生成RememberSet,简称Rset,Rset中存放了对象的引用信息,也可以理解为作为判断对象是否存活的依据.
CollectionSet:简称Cset,记录了最终GC需要回收的Region集合.
Snapshot at the begining:简称SATB,在开始GC前对存活对象生成快照,以此保证并发标记阶段的正确性.
G1GC的YoungGC比较简单,与之前的垃圾回收器YoungGC无异,所以这里主要介绍下G1GC的MixedGC,每次回收会发生在新生代及老年代.整个MixedGC过程如下:
- 初始标记 STW,初始化标记从GC ROOT开始直接可达的对象,记录进Rset中.
- 并发标记 这个阶段有多个线程参与,通过写屏障(可以类比volatile)更新Rset,保证Rset中存活对象的有效性.
- 最终标记 STW,标记出并发阶段发生变化的对象,将其合并到Rset中.
- 清除垃圾 STW,从Rset中挑选出回收收益最大的Region进行垃圾回收,因为这个原因,所以取名叫garbage first GC,简称G1GC,此过程的停顿时间是可以根据公式计算得出,所以说G1GC是有可预测停顿模型的垃圾回收器,由jvm决定从Cset中回收多少Region刚好满足设置的最大暂停时间.
Shenandoah GC: shenandoah gc是jdk12提供的一款低暂停时间的垃圾回收器,且暂停时间与堆大小无关,也常被简称为SGC.
ZGC:zgc是jdk11提供的低延迟垃圾回收器,在超大堆下有出色的表现.ZGC的目标是最大暂停时间不超过10ms,而且随着堆大小的增长,暂停时间几乎无影响,最大可以支持到16TB的堆内存,表现非凡!之所以有如此好的表现,主要是因为ZGC仅在Root对象扫描STW,其它阶段都是并发执行,使用有色指针和加载屏障来确保多线程并发执行下的正确性.
9.JVM调优
关于Jvm调优,我更倾向于使用工具,古人云:"工欲善其事必先利其器",还有一部分原因就是因为自己菜!没有牢固掌握jvm调优时用到的各种命令.
既然命令没掌握,又想达到大师级的调优,那还是老老实实用工具,这里推荐4款工具,2款监控用,2款调优用:
监控用:
①jdk自带的jconsole
②jdk自带的jvisovm
调优用:
①gceasy.io 强烈推荐
②gc viewer java写的桌面版调优参考工具
关于这些工具的使用及安装等可以参考我这篇:https://blog.csdn.net/lovexiaotaozi/article/details/82862196
这里仅说一下调优流程:
- 在jar启动的参数中添加:-Xloggc:$path/gc.log 把日志输出到自定义的目录下
- 通过xshell,winscp等工具把该文件从服务器拉取到你本地
- 把日志文件上传到gceasy.io 或者 gc viewer进行分析
- 根据分析结果调整jvm各区大小,停顿时间等,然后重复1-3,直到观察到的吞吐量,暂停时间达到期望状态或者表现最优.
jvm调优是门艺术,不同的服务器,项目,场景会有截然不同的调优参数,没有死参数.主要还是看目的,如果你觉得以上步骤太麻烦,不妨尝试把GC切换成G1GC,然后只需要简单指定下最大暂停时间,最大堆,剩下的交给G1GC自适应,G1G1还是比较先进和智能的,一两个参数基本上就能达到大师级的调优效果.
10.JAVA IO BIO/NIO/AIO
在java中,IO分为BIO,NIO,AIO.
要讲清楚这些IO,可以先看下知乎上有个人讲的一个通俗易懂的例子:
假设你开了一家茶水店,茶水间里有好多个茶壶,每个茶壶都需要烧开水,对应BIO,NIO,AIO下分别是这么处理的:
BIO:同步阻塞IO,一个茶壶就得雇一个服务员,这个服务员专门盯着这个茶壶,直到水开了才去处理,中间过程啥也不做.
NIO:异步非阻塞IO,茶水间里的这些茶壶由一个服务员看着就行了,有茶壶水烧开了这个服务员就去处理下.
AIO:异步非阻塞IO,给每个茶壶装个报警器,水开了就发出警报提醒服务员去处理,服务员不需要在水还没开的时候傻傻等着了.
看完这个例子基本上也就清除三种IO的差别了,BIO在大量请求下会创建大量的线程,一个线程只能处理一个请求,在请求处理过程中,其实线程有大部分时间是啥也不做的,对系统而言,线程资源本来就很宝贵,BIO会造成大量的线程资源浪费,有性能瓶颈.
NIO在大量请求下也只有一个线程去处理,效率很高,典型的NIO框架比如Netty,Mina,都是经得住海量并发请求,经过实战检验的.
jdk提供的原生nio框架对程序猿不太友好,代码繁琐复杂,而且有臭名昭著的空轮询bug,所以在用到NIO时还是尽量使用Netty等框架,虽然它们底层用的还是Jdk的nio,但修复了空轮询bug,在性能上也作了很多优化,而且对程序猿也比较友好.
AIO:虽然出来也好几年了,但目前用的人还是比较少的,原因可能是因为目前NIO的生态已经比较好了,有大量优秀框架,而且性能也不差,另外AIO的性能尚没有经过大量实战考验,有没有坑也不知道,加上学习成本,所以这可能是AIO暂时没太多人用的缘故.但我相信未来肯定会有越来越多的人用AIO,因为它设计理念上的先进性.
目前我所了解到的比较好的一个AIO框架:smart-io,国人写的,性能也比较高,4核8G单机QPS约75W,100M/秒左右的吞吐.
有兴趣可以看看: https://gitee.com/smartboot/smart-socket?_from=gitee_search
最后,空轮询bug也一起来看一下,再看看netty的解决方案,这个点也经常会被面试官问到.

写了一段死循环,selector.select()方法在正常情况下是阻塞的,直到筛选出有IO操作的key,但Linux内核低于2.6的情况下,这个方法并不一定能保证100%被阻塞,比如在一些极端情况下,用户先发起了请求,然后又断开了连接,这个时候尽管linux告诉jdk你是有select到值的,但实际上代码执行到it.hasNext时,却为false,因为key并没有真正被注册进selector里.
因为selector.select()方法不阻塞了,然后while(it.hasNext())里的代码也不执行了,于是上面这段代码就几乎变成了一段只有while(true){}的代码,导致cpu使用率逐步飙升,直到100%.
上面这个问题,jdk官方有3种解决方案,最终比较靠谱的是netty采用的那种,所以我这里也简单介绍下netty的解决思路:
当空轮询bug出现后,首先while(true){//①这里的代码块会被重复执行N次},而且每次因为不需要执行后续while(it.hasNext()){//②我不会被执行}中的逻辑,所以每次重复执行的时间间隔会非常短,正常情况下,一次io的处理时需要耗费一些时间的,Netty将这两个现象作为是否发生空轮询bug的判断条件,如果确认是发生了空轮询bug,说明selector已经抽风了,就重新创建一个selector,让程序回归正常.
netty的判断条件是:当selector.select()方法执行的阻塞时间极短时,就开始统计代循环次数,如果循环次数超过512次,就说明发生了空轮询bug,可以参考这段伪代码:
long currentTimeNanos = System.nanoTime();
for (;;) {
// 1.定时任务截止事时间快到了,中断本次轮询
...
// 2.轮询过程中发现有任务加入,中断本次轮询
...
// 3.阻塞式select操作
selector.select(timeoutMillis);
// 4.解决jdk的nio bug
long time = System.nanoTime();
//此处的逻辑就是: 当前时间 - 循环开始时间 >= 定时select的时间timeoutMillis,说明已经执行过一次阻塞select()
if (time - TimeUnit.MILLISECONDS.toNanos(timeoutMillis) >= currentTimeNanos) {
// 说明发生过一次阻塞式轮询
selectCnt = 1;
// 如果空轮询的次数大于空轮询次数阈值 SELECTOR_AUTO_REBUILD_THRESHOLD(512)
} else if (SELECTOR_AUTO_REBUILD_THRESHOLD > 0 &&
selectCnt >= SELECTOR_AUTO_REBUILD_THRESHOLD) {
/* setlctRebuildSelector():
* 1.首先创建一个新的Selecor
* 2.将旧的Selector上面的键及其一系列的信息放到新的selector上面。
*/
rebuildSelector();
selector = this.selector;
selector.selectNow();
selectCnt = 1;
break;
}
currentTimeNanos = time;
...
}关于jvm的知识点暂时梳理到这里,由于Jvm涉及的面比较广,后面在锁的章节会继续梳理与锁相关的Jvm知识点.