Java 7 Fork/Join 框架
在 Java7引入的诸多新特性中,Fork/Join 框架无疑是重要的一项。JSR 166旨在标准化一个实质上可扩展的框架,以将并行计算的通用工具类组织成一个类似java.util中Collection一样的包。其目标是使之对开 发人员易用且易维护,同时该框架也旨在并行计算地高质量实现。目前已经有多个新的类和接口被添加到该框架中了。
该新特性主要是解决Java社区中对于如synchronized,wait和notify等操作的低级别的话题活动的需求。Fork/Join框架被设计成可以容易地将算法并行化、分治化。开发人员曾多次想用自己(在非底层实现)的并发机制实现这一目标,因此新框架的想法是提供标准化和效率最高的并发工具协助开发人员实现各种多线程应用。其所需的类和接口都位于java.util.concurrent包中。
本文将描述Fork/Join框架及其如何用于解决Java并行问题(这些问题可参考本专题的第一部分)。
Fork/Join 框架
正如先前所说,Fork/Join框架是Java7中新增的一项特性,也是Java7平台的其中一项主要改进。上一篇文章中,我们知道了Java平台的多线程模型是如何从Java线程进化到Executor模型的。很明显,与普通Thread相比,Executor框架对多线程开发的支持要好得多。
在实际情况中,很多时候我们都需要面对经典的“分治”问题。要解决这类问题,主要任务通常被分解为多个任务块(分解阶段),其后每一小块任务被独立并行计算。一旦计算任务完成,每一快的结果会被合并或者解决(解决阶段)。
“分治”问题可以很容易地通过Callable线程的Executor接口来解决(Callable线程的细节可以参考上一篇文章)。通过为每个任务实例化一 个Callable实例,并在ExecutorService类中汇总计算结果来得出最终结果可以实现这一目的。那么自然而然想到的问题就是,如果这一 接口已经做得不错了,我们为什么还需要Java 7的其他框架?
使 用ExecutorService和Callable的主要问题是,Callable实例在本质上是阻塞的。一旦一个Callable实例开始执行,其他所有Callable都会被阻塞。由于队列后面的Callable实例在前一实例未执行完成的时候不会被执行,因此许多资源无法得到利用。Fork/Join框架被引入来解决这一并行问题,而Executor解决的是并发问题(译者注:并发和并行的区别就是一个处理器同时处理多个任务和多个处理器或者是多核的处理器同时处理多个不同的任务)。
Fork/Join框架中的”工作窃取(Work stealing)”
Fork/Join框架在java.util.concurrent包中加入了两个主要的类:
* ForkJoinPool
* ForkJoinTask
ForkJoinPool类是ForkJoinTask实例的执行者,ForkJoinPool的主要任务就是”工作窃取”,其线程尝试发现和执行其他任务创建的子任务。ForkJoinTask实例与普通Java线程相比是非常轻量的。
一 旦ForkJoinTask被启动,就会启动其子任务并等待它们执行完成。执行者ForkJoinPool负责将自任务赋予线程池中处于等待任务状态的另 一线程。线程池中的活动线程会尝试执行其他任务所创建的子任务。ForkJoinPool会尝试在任何时候都维持与可用的处理器数目一样数目的活动线程数
除了几个其他API方法以外,ForkJoinTask有两个主要的方法:
* fork () – 这个方法决定了ForkJoinTask的异步执行,凭借这个方法可以创建新的任务。
* join () – 该方法负责在计算完成侯返回结果,因此允许一个任务等待另一任务执行完成。
分支/合并的完整过程如下.
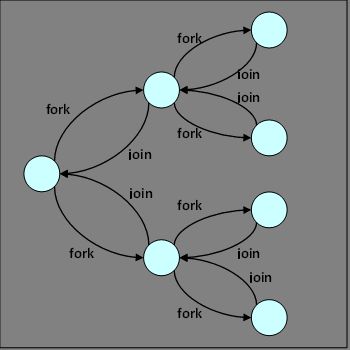
Java 7 Fork/Join 实例
本节中,我们将描述一个通过Java 7引入的Fork/Join框架进行n个自然数求和的例子。如前所述,本例的目的是将n个自然数求和的计算工作分解为更小的计算单元,再合并得出最终结果。检验和数的逻辑保持不变。
计算过程的基本原则是将n划分为更小的值来分别独立计算和数。整个遍历过程包括将n划分为1到n/2和(n+2)+1到n两部分,以及分别计算每一部分的和。
ForkJoinTask类如下定义:
EvaluateSumForkJoinTask 类扩展自递归结果处理类RecursiveTask,用于创建ForkJoinTask实例。RecursiveTask是泛型类,本例中设置为 Integer。EvaluateSumForkJoinTask重载了compute ()方法,该方法负责创建出新的任务分支,并合并计算结果。
既然主要问题可以被分解为两个大块,我们就创建两个工作者线程myWorker1和myWorker2,分别分配较小的n值给它们。一旦n值被减小到2,任务就没必要再并行化分解了。并行化停止条件可以根据具体的n值进行调整,以达到更好的并行效果。
客 户端类用于管理ForkJoinPool,并负责调用主任务。ForkJoinPool实例基于当前硬件条件下可用处理器数量进行配置。示例程序运行的机 器配有一个含2个处理器单元的双核处理器上。invoke()方法将对检验前n个(500个)自然数和的任务进行分解,该任务会轮流调用 EvaluateSumForkJoinTask类的compute()方法,EvaluateSumForkJoinTask类也扩展自 RecursiveTask。
计算结果比较
使用Fork/Join的计算过程由多个工作者线程代理,共同工作以计算和数。其计算结果和单线程的实现模式相比较得出以下结果:
| N值 |
单线程模型耗时 (ms) |
分支/合并模型耗时 (ms) |
备注 |
| 20 |
4 |
7 |
本例中,
分支/合并模型由于较小的n值耗时较长。对于非常小规模的问题而言,并行化未必值得。
|
| 100 |
15 |
6 |
在这三个例子中,
分支/合并模型由于使用了多处理器核心导致耗时较短。
|
| 500 |
124 |
6 |
|
| 1000 |
285 |
7 |
值得关注的一点是,单线程模型中CPU利用率比Fork/Join模型要小,如下所示:
单线程模型
分支/合并模型
结论
本 文通过单线程模型到Java 7引入的Fork/Join模型的演化,讨论了Java平台并行的编程特性。Java 5引入的Executor是一大进步,但由于其阻塞特性无法被应用于并行计算。因此Java 7引入的Fork/Join框架扮演了重要角色。本文通过一个非常简单的例子解释了并发及并行编程的概念,并通过两种方式结果数据的比较得出结论。
致谢
作者真诚感谢Subrahmanya先生,SV, VP, ECOM 研究组,以及E&R的指导,支持以及不断的鼓励,同事真心感谢Piram先生的审阅。
Nitin KL.
Nitin 先生是Infosys公司的技术主管,在Java EE技术方面有非常丰富的知识,致力于使用Hibernate, iBATIS及JPA框架的Java EE应用设计与开发工作。Nitin先生已经为Devx撰写过许多在线文章,可以通过[email protected]联系到他。
Sangeetha S.
S Sangeetha女士是Infosys公司电子商务研究室的高级技术架构师。她拥有超过14年的Java及Java EE应用设计开发经验。她是一本J2EE架构著作的作者之一,同时也为JavaWorld,java.net,Devx等撰写了许多在线文章,她的联系方 式为[email protected]。
译者注:
本 文是作者承接其另一篇讨论Java多线程及并行计算的文章(Java多线程及并行计算的挑战)而作的,本文也涉及了该文的部分概念,该文文原文可见 http://www.developer.com/java/java-multi-threading-and-the-challenges- of-parallel-computing.html。
英文原文:developer,编译:ImportNew - 郑玮