ffmpeg代码笔记5:MP4文件读取packet,计算DTS
最近对MP4文件结构比较感兴趣,这几天每天早上都在研究,在网上翻看了很多资料,包括MP4的国际标准文件(都是英文,本人英文最渣,读起来很是吃力)。最终皇天不负有心人,终于理清了ffmpeg代码读取MP4文件的packet,稍微有点成就感。废话不多了,开始吧!
“stbl”几乎是普通的MP4文件中最复杂的一个box了,首先需要回忆一下sample的概念。sample是媒体数据存储的单位,存储在media的chunk中,chunk和sample的长度均可互不相同,如下图所示。

“stbl”包含了关于track中sample所有时间和位置的信息,以及sample的编解码等信息。利用这个表,可以解释sample的时序、类型、大小以及在各自存储容器中的位置。“stbl”是一个containerbox,其子box包括:sampledescription box(stsd)、time tosample box(stts)、sample sizebox(stsz或stz2)、sample tochunk box(stsc)、chunk offsetbox(stco或co64)、compositiontime to sample box(ctts)、sync samplebox(stss)等。
“stsd”必不可少,且至少包含一个条目,该box包含了datareference box进行sample数据检索的信息。没有“stsd”就无法计算mediasample的存储位置。“stsd”包含了编码的信息,其存储的信息随媒体类型不同而不同。
Sample Description Box(stsd)
box header和version字段后会有一个entrycount字段,根据entry的个数,每个entry会有type信息,如“vide”、“sund”等,根据type不同sampledescription会提供不同的信息,例如对于video track,会有“VisualSampleEntry”类型信息,对于audiotrack会有“AudioSampleEntry”类型信息。
视频的编码类型、宽高、长度,音频的声道、采样等信息都会出现在这个box中。
Time To Sample Box(stts)
“stts”存储了sample的duration,描述了sample时序的映射方法,我们通过它可以找到任何时间的sample。“stts”可以包含一个压缩的表来映射时间和sample序号,用其他的表来提供每个sample的长度和指针。表中每个条目提供了在同一个时间偏移量里面连续的sample序号,以及samples的偏移量。递增这些偏移量,就可以建立一个完整的time to sample表。
Sample Size Box(stsz)
“stsz” 定义了每个sample的大小,包含了媒体中全部sample的数目和一张给出每个sample大小的表。这个box相对来说体积是比较大的。该字段可以得到有多少个sample(帧)
Sample To Chunk Box(stsc)
用chunk组织sample可以方便优化数据获取,一个thunk包含一个或多个sample。“stsc”中用一个表描述了sample与chunk的映射关系,查看这张表就可以找到包含指定sample的thunk,从而找到这个sample。
主要介绍下stsc结构。它非常的“特别”。
它用了一种巧妙的方式来说明sample和chunk的映射关系,特别介绍一下。
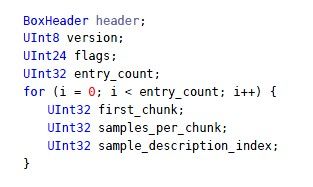
这是stsc box的结构,前几项的意义就不解释了,可以看到stsc box里每个entry结构体都存有三项数据,它们的意思是:“从first_chunk这个chunk序号开始,每个chunk都有samples_per_chunk个数的sample,而且每个sample都可以通过sample_description_index这个索引,在stsd box中找到描述信息”。也就是说,每个entry结构体描述的是一组chunk,它们有相同的特点,那就是每个chunk包含samples_per_chunk个sample,好,那你要问,这组相同特点的chunk有多少个?请通过下一个entry结构体来推算,用下一个entry的first_chunk减去本次的first_chunk,就得到了这组chunk的个数。最后一个entry结构体则表明从该first_chunk到最后一个chunk,每个chunk都有sampls_per_chunk个sample。很拗口吧,不过,就是这个意思:)。由于这种算法无法得知文件所有chunk的个数,所以你必须借助于stco。
Sync Sample Box(stss)
“stss”确定media中的关键帧。对于压缩媒体数据,关键帧是一系列压缩序列的开始帧,其解压缩时不依赖以前的帧,而后续帧的解压缩将依赖于这个关键帧。“stss”可以非常紧凑的标记媒体内的随机存取点,它包含一个sample序号表,表内的每一项严格按照sample的序号排列,说明了媒体中的哪一个sample是关键帧。如果此表不存在,说明每一个sample都是一个关键帧,是一个随机存取点。
Chunk Offset Box(stco)
“stco”定义了每个thunk在媒体流中的位置。位置有两种可能,32位的和64位的,后者对非常大的电影很有用。在一个表中只会有一种可能,这个位置是在整个文件中的,而不是在任何box中的,这样做就可以直接在文件中找到媒体数据,而不用解释box。需要注意的是一旦前面的box有了任何改变,这张表都要重新建立,因为位置信息已经改了。通过该字段可以得到有多少个chunk。
上面的介绍可以大致归纳下图:

那么,我们可以想象下MP4是如何播放的呢?1.根据时间,可以在stts box提供的表找到对应的sample。2.根据sample 可以在stsc box提供的表中查询到chunk。3.根据chunk 可以在stco查询到该chunk的偏移量(如果该sample不是该chunk的第一个sample,需要在偏移量上加上该sample之前所有sample的大小和)。4.查询stsz box提供的表,可以知道该sample大小。知道了偏移量和sample的大小,那么可以直接读取该sample(帧)进行解码播放了。
ffmpeg代码(mov_bulid_index)为每个帧都建立了索引。可以根据时间来查询对应的sample。索引结构体如下:
typedef struct AVIndexEntry{
int64_t pos;//该帧的偏移量
int64_t timestamp;//该帧的时间戳,相对于整个文件的时间偏移量
int flag;//是否关键帧
int size;//帧大小
int min_distance;//理最近关键帧的距离
}
mov_build_index流程如下:

ffmpeg根据上图给每个帧建立索引。那么只要知道时间,遍历所有的帧,比较帧的timestamp就可以知道具体的帧了。然后根据帧的偏移量读取data部分,赋值给packet.buf。然后把帧的size 赋值给packet.size,timestamp赋值给packet.dts。
延伸下知识。ffmpeg命令参数-ss的处理,根据-ss的参数时间值取查找索引,可以知道具体的sample,知道sample就知道了很多信息。然后av_read_packet函数从该sample之后挨个读取后面的sample。
注:计算DTS的时候,往往需要先计算elst box,因为在该box定义了流的开始时间,如果为空,则说明流式从0开始。如果不为空,则说明要跳过指定时间后才开始播放,所以DTS需要加上一个偏移量。