操作系统概念学习笔记 10 CPU调度
操作系统概念学习笔记 10
CPU调度
多道程序操作系统的基础。通过在进程之间切换CPU,操作系统可以提高计算机的吞吐率。
对于单处理器系统,每次只允许一个进程运行:任何其他进程必须等待,直到CPU空闲能被调度为止。
多道程序的目标是在任何时候都有某些进程在运行,以使CPU的使用率最大化。多道程序的思想较为简单,当一个进程必须等待时,操作系统会从该进程拿走CPU的使用权,而将CPU交给其他进程。
CPU-I/O 区间周期
CPU的成功调度依赖于进程的如下属性:
进程执行由CPU执行周期和I/O等待周期组成。进程在这两个状态之间切换(CPU burst—I/O bust)。
进程执行从CPU区间(CPU burst)开始,在这之后是I/O区间(I/O burst)。接着另外一个CPU区间,然后是另外一个I/O区间,如此进行下去,最终,最后的CPU区间通过系统请求中止执行。

经过大量CPU区间的长度的测试。发现具有大量短CPU区间和少量长CPU区间。I/O约束程序通常具有很多短CPU区间。CPU约束程序可能有少量的长CPU区间。这种分布有助于选择合适的CPU调度算法。
CPU程序调度
每当CPU空闲时,操作系统就必须从就绪队列中选择一个进程来执行。进程选择由短期调度程序(short-term scheduler)或CPU调度程序执行。调度程序从内存中选择一个能够执行的进程,并为之分配CPU。
就绪队列不必是先进先出(FIFO)队列,也可为优先队列、树或简单的无序链表。不过队列中所有的进程都要排队以等待在CPU上运行。队列中的记录通常为进程控制块(PCB)。
抢占调度:
CPU调度决策可在如下4种情况环境下发生:
(1)当一个进程从运行切换到等待状态(如:I/O请求,或者调用wait等待一个子进程的终止)
(2)当一个进程从运行状态切换到就绪状态(如:出现中断)
(3)当一个进程从等待状态切换到就绪状态(如:I/O完成)
(4)当一个进程终止时
对于第1和4两种情况,没有选择而只有调度。一个新进程(如果就绪队列中已有一个进程存在)必须被选择执行。对于第2和第3两种情况,可以进行选择。
当调度只能发生在第1和4两种情况下时,称调度是非抢占的(nonpreemptive)或协作的(cooperative);否则,称调度方案为抢占的(preemptive)。采用非抢占调度,一旦CPU分配给一个进程,那么该进程会一直使用CPU直到进程终止或切换到等待状态。
抢占调度对方问共享数据是有代价(如加锁)的,需要新的机制来协调对共享数据的访问。
抢占对于操作系统内核的设计也有影响。在处理系统调用时,内核可能忙于进程活动。这些活动可能涉及要改变重要内核数据(如I/O队列)。
因为根据定义中断能随时发生,而且不能总是被内核所忽视,所以受中断影响的代码段必须加以保护以避免同时访问。操作系统需要在任何时候都能够接收中断,否则输入会丢失或输出会被改写。为了这些代码段不被多个进程同时访问,在进入时就要禁止中断,而在退出时要重新允许中断。
分派程序
分派程序(dispatch)是一个模块,用来将CPU的控制交给由短期调度程序选择的进程。
其功能包括:
- 切换上下文
- 切换到用户模式
- 跳转到用户程序的合适位置,以重新启动程序。
分派程序停止一个进程而启动另一个所花的时间成为分派延迟(dispatch latency)。
调度准则
为了比较CPU调度算法所提出的准则:
CPU使用率 : 需要使CPU尽可能忙
吞吐量 : 指一个时间单元内所完成进程的数量
周转时间 : 从进程提交到进程完成的时间段称为周转时间,周转时间是所有时间段之和,包括等待进入内存、在就绪队列中等待、在CPU上执行和I/O执行
等待时间 : 在就绪队列中等待所花费时间之和
响应时间 : 从提交请求到产生第一响应的时间
需要使CPU使用率和吞吐量最大化,而使周转时间、等待时间和响应时间最小化。绝大多数情况下需要优化平均值,有时需要优化最大值或最小值,而不是平均值。
调度算法
先到先服务调度
最简单的CPU调度算法是先到先服务算法(First-Come,First-Served scheduling):先请求CPU的进程先分配到CPU。FCFS策略可以用FIFO队列来容易实现。当一个进程进入就绪队列,其PCB链接到队列的尾部。当CPU空闲时,CPU分配给位于队列头的进程,接着运行进程从队列中删除。
FCFS策略的代码编写简单且容易理解,不过采用FCFS策略的平均等待时间通常比较长。当进程CPU区间时间变化很大,平均等待时间会变化很大。
比如以下例子
| 进程 | 区间时间 |
|---|---|
| P1 | 24 |
| P2 | 3 |
| P3 | 3 |
如果按照P1 P2 P3 顺序到达,Gantt图如下:

平均等待时间:(0+24+27)/3 = 17
如果按P2 P3 P1 顺序到达,
平均等待时间:(0+3+6)/3 = 3
另外考虑在动态情况下的性能,假设有一个CPU约束进程和许多I/O约束进程,CPU约束进程会移回到就绪队列并被分配到CPU。再次所有I/O进程会在就绪队列中等待CPU进程的完成。由于所有其他进程都等待一个大进程释放CPU,这称之为护航效果(convoy effect)。与让较短进程最先执行相比,这样会导致CPU和设备使用率变的很低。
FCFS调度算法是非抢占的。对于分时系统(每个用户需要定时的等待一定的CPU时间)是特别麻烦。允许一个进程保持CPU时间过长是个严重错误。
最短作业优先调度(shortest-job-first scheduling,SJF)
将每个进程与下一个CPU区间段相关联。当CPU为空闲时,它会赋给具有最短CPU区间的进程。如果两个进程具有同样长度,那么可以使用FCFS调度来处理。注意,一个更为适当地表示是最短下一个CPU区间的算法,这是因为调度检查进程的下一个CPU区间的长度,而不是其总长度。
比如以下例子
| 进程 | 区间时间 |
|---|---|
| P1 | 6 |
| P2 | 8 |
| P3 | 7 |
| P4 | 3 |
SJF: (0+3 + 9 + 16)/4 = 7
FCFS: (0+6+14+21)/4 = 10.25
SJF算法的平均等待时间最小。SJF算法的真正困难是如何知道下一个CPU区间的长度。对于批处理系统的长期(作业)调度,可以将用户提交作业时间所制定的进程时间极限作为长度。SJF调度经常用于长期调度。
它不能在短期CPU调度层次上加以实现。我们可以预测下一个CPU区间。认为下一个CPU区间的长度与以前的相似。因此通过计算下一个CPU区间长度的近似值,能选择具有最短预测CPU区间的进程来运行。下一个CPU区间通常可预测为以前CPU去剪的测量长度的指数平均(exponential average)。
SJF算法可能是抢占的或非抢占的。抢占SJF算法可抢占当前运行的进程,而非抢占的SJF算法会允许当前的进程先完成其CPU区间。抢占SJF调度有时称为最短剩余时间优先调度(shortest-remaining-time-first scheduling)。
比如以下例子
| 进程 | 到达时间 | 区间时间 |
|---|---|---|
| P1 | 0 | 8 |
| P2 | 1 | 4 |
| P3 | 2 | 9 |
| P4 | 3 | 5 |
根据Gantt图:

平均等待时间:
(0+0+(5-3)+(10-1)+(17-2))/4 = 26/4 = 6.5
非抢占SJF:
(0+(8-1)+(12-3)+(17-2))/4 = 7.75
优先级调度(priority scheduling algorithm)
SJF算法可作为通用的优先级调度算法的一个特例。每个进程都有一个优先级与其关联,具有最高优先级的进程会分配到CPU。具有相同优先级的进程按FCFS顺序调度。SJF,其优先级(p)为下一个CPU区间的倒数。CPU区间越大,则优先级越小,反之亦然。
优先级通常是固定区间的数字,如0~7,但是数字大小与优先级的高低没有定论。
对于下例,假设数字越小优先级越高
| 进程 | 区间时间 | 优先级 |
|---|---|---|
| P1 | 10 | 3 |
| P2 | 1 | 1 |
| P3 | 2 | 4 |
| P4 | 1 | 5 |
| P5 | 5 | 2 |
平均等待时间为:
(0+1+6+16+18)/5 = 8.2
优先级可通过内部或外部方式来定义。内部定义优先级使用一些测量数据以计算进程优先级。外部优先级是通过操作系统之外的准则来定义,如进程重要性等。
优先级调度可以是抢占的或非抢占的。
优先级调度算法的一个重要问题是无限阻塞(indefinite blocking)或饥饿(starvation)。可以运行但缺乏CPU的进程可认为是阻塞的,它在等待CPU。优先级调度算法会使某个有低优先级无穷等待CPU。
低优先级进程务求等待问题的解决之一是老化(aging)。老化是一种技术,以逐渐增加在系统中等待很长时间的进程的优先级。
轮转法调度(round-robin,RR)
专门为分时系统设计。它类似于FCFS调度,但是增加了抢占以切换进程。定义一个较小的时间单元,称为时间片(time quantum,or time slice)。将就绪队列作为循环队列。CPU调度程序循环就绪队列,为每个进程分配不超过一个时间片段的CPU。
新进程增加到就绪队列的尾部。CPU调度程序从就绪队列中选择第一个进程,设置定时器在一个时间片之后中断,再分派该进程。接下来将可能发生两种情况。进程可能只需要小于时间片的CPU区间。对于这种情况,进程本身会自动释放CPU。调度程序接着处理就绪队列的下一个进程。否则,如果当前运行进程的CPU区间比时间片要长,定时器会中断产生操作系统中断,然后进行上下文切换,将进程加入到就绪队列的尾部,接着CPU调度程序会选择就绪队列中的下一个进程。
RR策略的平均等待时间通常较长
比如以下例子,使用4ms时间片
| 进程 | 区间时间 |
|---|---|
| P1 | 24 |
| P2 | 3 |
| P3 | 3 |
画出Gantt图:
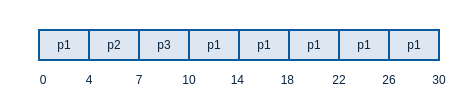
平均等待时间:
(0+4+7+(10-4))/3 = 5.66
如果就绪,那么每个进程会得到1/n的CPU时间,其长度不超过q时间单元。每个进程必须等待CPU时间不会超过(n-1)q个时间单元,直到它的下一个时间片为止。
RR算法的性能很大程度上依赖于时间片的大小。在极端情况下,如果时间片非常大,那么RR算法与FCFS算法一样。如果时间片很小,那么RR算法称为处理器共享,n个进程对于用户都有它自己的处理器,速度为真正处理器速度的1/n。
小的时间片会增加上下文切换的次数,因此,希望时间片比上下文切换时间长,事实上,绝大多数现代操作系统,上下文切换的时间仅占时间片的一小部分。
周转时间也依赖于时间片的大小。
多级队列调度(Multilevel Queue Scheduling)
前台(交互)进程和后台(批处理)进程。这两种不同各类型的进程具有不同响应时间要求,也有不同调度需要。与后台进程相比,前台进程要有更高(或外部定义)的优先级。
多级队列调度算法将就绪队列分成多个独立队列。根据进程的属性,如内存大小等,一个进程被永久地分配到一个队列(低调度开销但是不够灵活),每个队列有自己的调度算法。前台队列可能采用RR算法调度,而后台调度可能采用FCFS算法调度。
另外,队列之间必须有调度,通常采用固定优先级抢占调度,例如前台队列可以比后台队列具有绝对优先值。另一种可能在队列之间划分时间片例如,前台队列可以有80%的时间用于在进程之间进行RR调度,而后台队列可以有20%的CPU时间采用FCFS算法调度进程。
多级反馈队列调度(Multilevel Feedback-Queue Scheduling)
与多级队列调度相反,多级反馈队列调度允许进程在队列之间移动。主要思想是根据不同CPU区间的特点以区分进程。如果进程使用过多CPU时间,那么它可能被转移到较低优先级队列。这种方案将I/O约束和交互进程留在更高优先级队列。此外,在较低优先级队列中等待时间过长的进程会被转移到更高优先级队列。这种形式的老化组织饥饿的发生。
通常,多级反馈队列调度程序可由下列参数来定义:
- 队列数量。
- 每个队列的调度算法。
- 用以确定何时升级到更高优先级队列的方法。
- 用以确定何时降级到更低优先级队列的方法。
- 用以确定进程在需要服务时应进入哪个队列的方法。
多处理器调度(Multiple-Processor Scheduling)
如果多个CPU,则负载分配(load sharing)成为可能。其中主要讨论处理器功能相同(或同构)的系统,可以将任何处理器用于运行队列内的任何进程。
多处理器调度方法
在一个多处理器中,CPU调度的一种方法是让一个处理器(主服务器)处理所有的调度决定、I/O处理以及其他系统活动,其他的处理器只执行用户代码。这种非对称处理(asymmetric multiprocessing)方法更为简单,因为只有一个处理器访问系统数据结构,减轻了数据共享的需要。
另一种方法是使用对称多处理(symmetric multiprocessing,SMP)方法,即每个处理器自我调度。所有进程可能处于一个共同的就绪队列中,或每个处理器都有自己的私有就绪队列。无论如何,调度通过每个处理器检查共同就绪队列并选择一个进程来执行。如果多个处理器试图访问和更新一个共同数据结构,那么每个处理器必须仔编程:必须确保两个处理器不能选择同一进程,且进程不会从队列中丢失。
处理器亲和性
进程移到其他处理器上时,被迁移的第一个处理器的缓存中的内容必须为无效,而将要迁移的第二个处理器上的缓存需重新构建。由于使缓存无效或重构的代价高,因而SMP努力的使一个进程在同一个处理器上运行,这被称为处理器亲和性,即一个进程需有一种对其他运行所在的处理器的亲和性。
处理器亲和性的几种形式:
软亲和性(soft affinity,操作系统具有设法让一个进程保持在同一个处理器上运行的策略,但不能做任何保证)
硬亲和性(hard affinity,允许进程指定它不允许移至其他处理器),如LINUX
负载平衡(load balancing)
负载平衡设法将工作负载平均地分配到SMP系统中的所有处理器上。通常只是对那些拥有自己私有的可执行的进程的处理器而言是必要的,在具有共同队列的系统中,通常不需要负载平衡,因为一旦处理器空闲,会立刻从就绪队列中取走一个可执行进程。
两种方法:push migration和pull migration,对于push migration,一个特定的任务周期性地检查每个处理器上的负载,如果发现不平衡,即通过将进程从超载处理器移到(或推送到)空闲或不太忙的处理器,从而平均地分配负载,当空闲处理器从一个忙的处理器上推送pull一个等待任务时,发生pull migration。push migration和pull migration不能互相排斥。
负载平衡会抵消处理器亲和性。
对称多线程
提供多个逻辑(而非物理的)处理器来运行几个线程,称为对称多线程(SMT),或超线程(hyperthreading)技术。
SMT的思想是在同一个物理处理器上生成多个逻辑处理器,即使系统仅有单处理器,每个逻辑处理器都有它自己的架构状态,包括通用目的和机器状态寄存器。每个逻辑处理器负责自己的中断处理,这意味着中断被送到并被逻辑处理器所处理,每个逻辑处理器共享其物理处理器的资源,如缓存或总线。
SMT是硬件而非软件提供的。硬件应该提供每个逻辑处理器的架构状态的表示以及中断处理方法。调度程序首先设法把不同线程分别调度到每个物理处理器上,而不是调度到同一个物理处理器的不同逻辑处理器上。
线程调度
系统调度的是内核线程,而不是进程。用户线程由线程库管理,内核并不了解它们。用户线程最终必须映射到相应的内核级线程,尽管这种映射可能是间接的,可能使用轻量级进程(LWP)。
竞争范围
用户线程和内核线程的区别之一是它们是如何被调度的。在执行多对一模型和多对多模型系统上,线程库调度用户级线程到一个有效的LWP上运行,这被称为进程竞争范围(process-contention scope,PCS)方法,因为CPU竞争发生在属于相同进程的线程之间。为了决定调度哪个内核线程到CPU,内核采用系统竞争范围(system-contention scope,SCS)方法来进行,竞争CPU发生在系统所有线程中,采用一对一的模型的系统,调度仅使用SCS方法。
PCS是根据优先级完成的。