XPath Extractor的使用
XPath Extractor是另一个可被用来提取页面给定内容的Post Processor,XPath Extractor的使用方式与Regular Expression Extractor类似,只不过需要在该Extractor中指定的不是正则表达式,而是给定的XPath路径。
用xpath从前一个请求中取。这种形式比较适合于返回为xml片段的情况。在需要获得数据的请求上右击添加一个后置处理器-->xPath Extractor。引用名称即下一个请求要引用的参数名称,如填写body,则可用${body}引用它。
Xpath一般用于返回xml用得多。
XPath Extractor的设置界面:
· Main sample only: 只对主 sample 起作用。
· Sub-samples only: 只对子 sample 起作用。
· Main sample and sub-samles: 两种都起作用。
· JMeter Varibale: 这个变量是用于 JMeter的assertion, assertion 会对这个变量的内容起作用。
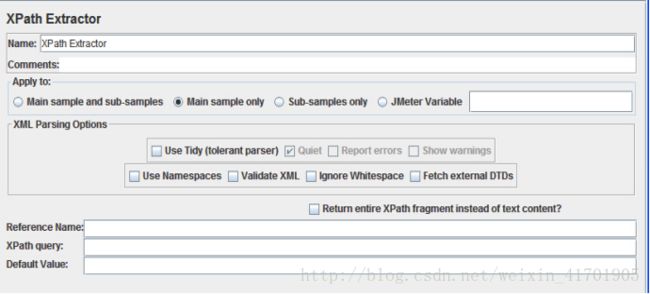
l Use Tidy?:当需要处理的页面是HTML格式时,必须选中该选项,当需要处理的页面是XML或XHTML格式(例如,RSS返回)时,取消选中该选项。
l Reference Name(引用名称):存放提取出的值的参数。
l XPathQuery:用于提取值的XPath表达式。
http://www.ruanyifeng.com/blog/2009/07/xpath_path_expressions.html(xpath提示表达式)
l Default Value:参数的默认值。
举例:-------------------------------------------------------------------------------------------
如果当前请求Post的某一个参数需要获取上一个请求的响应数据值,可以使用XPath Extractor进行处理。
操作步骤:
1,查看上一个请求的响应数据,找到你需要的元素的HTML文本,并转换成XPath获取。
eg:我需要的是这个元素的value值
对应的Xpath=//input[@id = "javax.faces.ViewState"]/@value
引用名称: {TOKEN}
XPath query: //form[@name="userform"]/input[@name="token"]/@value
2,在HTTP请求下添加XPath Extractor
3,填写引用名称和Xpath query.
注意如果响应数据为html的注意勾选下面两个选项,添加时默认时不勾选的,不然有可能获取不到元素。
正则表达式提取器和XPath Extractor的区别:
①正则表达式提取器可以用于对页面任何文本的提取,提取的内容是根据正则表达式在页面内容中进行文本匹配;
②XPath Extractor则可以提取返回页面任意元素的任意属性;
③如果需要提取的文本是页面上某元素的属性值,建议使用XPath Extractor;
④如果需要提取的文本在页面上的位置不固定,或者不是元素的属性,建议使用正则表达式提取器。
https://www.cnblogs.com/paulwinflo/p/5632294.html