移植sql server 的存储过程到mysql中,遇到了sql server中的:
IF @@ROWCOUNT < 1
对应到mysql中可以使用 FOUND_ROWS() 函数来替换。
1. found_rows() 函数
文档地址:http://dev.mysql.com/doc/refman/5.6/en/information-functions.html#function_found-rows
1)found_rows() 的第一种使用情况(带有SQL_CALC_FOUND_ROWS,):也带有
A SELECT statement may include a LIMIT clause to restrict the number of rows the server returns to the client. In some cases, it is desirable to know how many rows the statement would have returned without the LIMIT, but without running the statement again. To obtain this row count, include a SQL_CALC_FOUND_ROWS option in the SELECT statement, and then invoke FOUND_ROWS() afterward:
mysql>SELECT SQL_CALC_FOUND_ROWS * FROM->tbl_nameWHERE id > 100 LIMIT 10;mysql>SELECT FOUND_ROWS();
The second SELECT returns a number indicating how many rows the first SELECT would have returned had it been written without the LIMIT clause.
前面的带有limit的select语句如果加上了 SQL_CALC_FOUND_ROWS,那么接下来执行的 SELECT FOUND_ROWS(); 将返回前面语句不带limit语句返回的行数。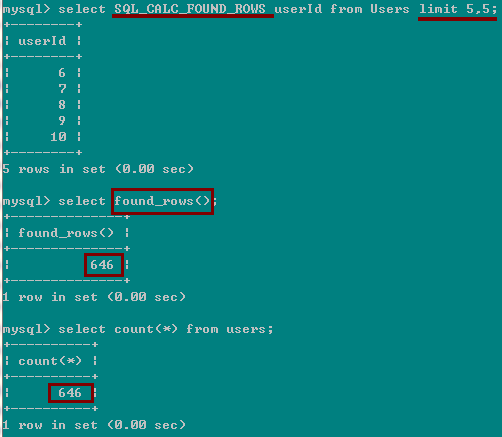
此种情况下,select found_rows() 和 select count(*) 有一个很小的区别:如果userId允许为null,那么select found_rows() 的结果可能要比select count(*) 要小一些。因为前者等价于:select count(userId) from Users; 而该语句不会计算userId 为null的行在内。而count(*)会计算在内。
2)found_rows() 的第二种/第三中使用情况(不带有SQL_CALC_FOUND_ROWS):
In the absence of the SQL_CALC_FOUND_ROWS option in the most recent successful SELECT statement, FOUND_ROWS() returns the number of rows in the result set returned by that statement. If the statement includes a LIMIT clause, FOUND_ROWS() returns the number of rows up to the limit. For example, FOUND_ROWS() returns 10 or 60, respectively, if the statement includes LIMIT 10 or LIMIT 50, 10.
The row count available through FOUND_ROWS() is transient and not intended to be available past the statement following the SELECT SQL_CALC_FOUND_ROWS statement. If you need to refer to the value later, save it:
mysql>SELECT SQL_CALC_FOUND_ROWS * FROM ... ;mysql>SET @rows = FOUND_ROWS();
If you are using SELECT SQL_CALC_FOUND_ROWS, MySQL must calculate how many rows are in the full result set. However, this is faster than running the query again without LIMIT, because the result set need not be sent to the client.
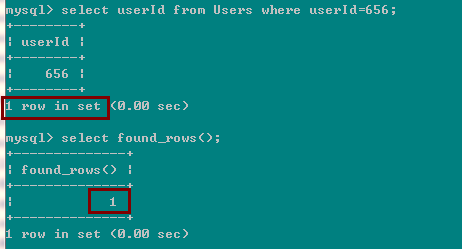
1> 第二种使用情况(不带有SQL_CALC_FOUND_ROWS,):也没有带 limit
如果前面的select语句没有带 SQL_CALC_FOUND_ROWS,也没有带 limit ,那么后面的 SELECT FOUND_ROWS(); 返回的结果就是前面的select返回的行数;
2> 第三中使用情况(不带有SQL_CALC_FOUND_ROWS,但是):有带 limit
如果前面的select语句没有带 SQL_CALC_FOUND_ROWS,但是带有 limit,那么后面的 就是limit语句到达的最大的行数,比如:select * from xxx limit 10; 到达的最大的行数为10,所以 found_rows() 返回10;比如 select * from xxx limit 50,10; 它要从第50行开始,再扫描10行,所以到达的最大的行数为60,所以SELECT FOUND_ROWS(); 返回的结果found_rows() 返回60。
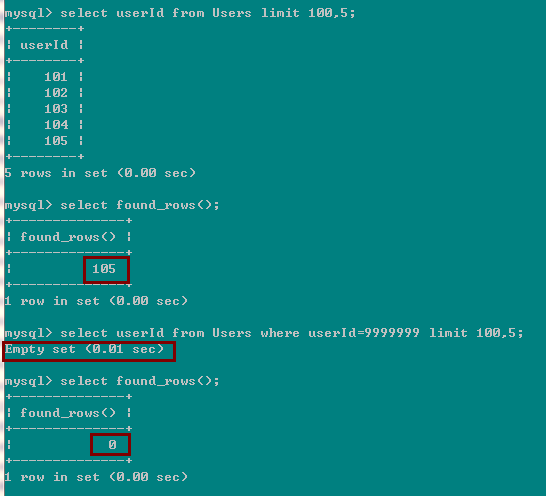
这里第一个select found_rows() 返回105,因为他是从偏移100的地方,再扫描5行,所以返回105;但是第二个扫描的结果为空,select found_rows()返回了0!而不是105,因为 where userId=999999的结果为空,所以后面的 limit 100,5根本就没有执行。所以select found_rows()返回了0。
再看一个例子,更深入的理解其中情况下的 found_rows():
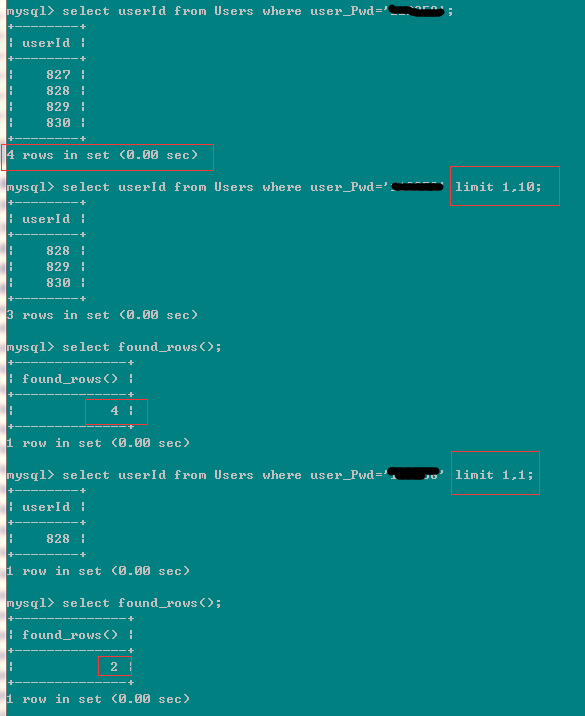
上面sql中 user_Pwd=xx 的值都是一样的。可以看到这种情况下的found_rows() 是对的select语句的中间结果,再 limit 时,此时的limit的扫描到的最大的行数。和原始表中的数据的行数,是没有关系的。他是对select的中间结果的limit,然后才得到最后的结果集,再返回。
3)SQL_CALC_FOUND_ROWS and FOUND_ROWS() 适合使用的场景
SQL_CALC_FOUND_ROWS and FOUND_ROWS() can be useful in situations when you want to restrict the number of rows that a query returns, but also determine the number of rows in the full result set without running the query again. An example is a Web script that presents a paged display containing links to the pages that show other sections of a search result. Using FOUND_ROWS()enables you to determine how many other pages are needed for the rest of the result.
1> SQL_CALC_FOUND_ROW + limit + found_rows() 可以使用在分页的场合。
2> 不带SQL_CALC_FOUND_ROW 的 found_rows() 可以使用在存储过程中判断前面的select是否为空:

DELIMITER //
DROP PROCEDURE IF EXISTS loginandreg //
CREATE PROCEDURE loginandreg(
OUT userId BIGINT,
IN user_Pwd VARCHAR(32),
IN user_MobileCode VARCHAR(16),
IN user_RegIP VARCHAR(16)
)
BEGIN
IF EXISTS(SELECT * FROM Users u WHERE u.user_MobileCode=user_MobileCode) THEN
SELECT u.userId INTO userId FROM Users u WHERE u.user_MobileCode=user_MobileCode AND u.user_Pwd=user_Pwd;
IF FOUND_ROWS() < 1 THEN
SELECT -1 INTO userId;
END IF;
ELSE
INSERT INTO Users(user_Pwd,user_MobileCode,user_Visibility,user_Level,user_RegTime,user_RegIP,user_Collecter,user_Collected)
VALUES (user_Pwd,user_MobileCode,6,6,NOW(),user_RegIP,0,0);
SELECT LAST_INSERT_ID() INTO userId;
END IF;
END //
DELIMITER ;
上面存储过程中的:
SELECT u.userId INTO userId FROM Users u WHERE u.user_MobileCode=user_MobileCode AND u.user_Pwd=user_Pwd;
IF FOUND_ROWS() < 1 THEN
SELECT -1 INTO userId;
END IF;
就是一个很好的使用的例子。
这种存储过程的场景中就可以使用 mysql 的 FOUND_ROWS() 替换 sql server 存储过程中的 IF @@ROWCOUNT < 1 语句。
--------------------------------------------------------------------------------------------------------------------------
2. row_count() 函数
文档地址:http://dev.mysql.com/doc/refman/5.6/en/information-functions.html#function_row-count
一句话,row_count() 函数一般用于返回被 update, insert, delete 实际修改的行数。
In MySQL 5.6, ROW_COUNT() returns a value as follows:
-
DDL statements: 0. This applies to statements such as
CREATE TABLEorDROP TABLE. -
DML statements other than
SELECT: The number of affected rows. This applies to statements such asUPDATE,INSERT, orDELETE(as before), but now also to statements such asALTER TABLEandLOAD DATA INFILE. -
SELECT: -1 if the statement returns a result set, or the number of rows “affected” if it does not. For example, forSELECT * FROM t1,ROW_COUNT()returns -1. ForSELECT * FROM t1 INTO OUTFILE ',file_name'ROW_COUNT()returns the number of rows written to the file. -
SIGNALstatements: 0.
For UPDATE statements, the affected-rows value by default is the number of rows actually changed. If you specify the CLIENT_FOUND_ROWS flag to mysql_real_connect() when connecting to mysqld, the affected-rows value is the number of rows “found”; that is, matched by the WHERE clause.
也就是说对于update语句,row_count() 默认返回的是实际被修改的行数;但是通过参数设置,也可以返回找到的行数(或者说匹配的行数,受影响的行数),这样设置就能兼容于Oracle ps/sql中 sql%rowcount 和 sql server 中的 @@RowCount。
但是 row_count() 的结果和 mysql 的JDBC driver的默认行为却是不一致的,mysql jdbc中的 Statement.getUpdateCount() 函数返回的是被找到的行数,而不是实际被修改的行数,如果要返回被实际修改的行,应该使用存储过程,相关链接说明:
http://stackoverflow.com/questions/17544782/how-to-tell-number-of-rows-changed-from-jdbc-execution
http://mybatis-user.963551.n3.nabble.com/Return-number-of-changed-rows-td3888464.html#a3903155
http://dev.mysql.com/doc/connector-j/en/connector-j-reference-configuration-properties.html (这里包含了所有mysql jdbc 链接可设置的参数)
useAffectedRows Don't set the CLIENT_FOUND_ROWS flag when connecting to the server (not JDBC-compliant, will break most applications that rely on "found" rows vs. "affected rows" for DML statements), but does cause "correct" update counts from "INSERT ... ON DUPLICATE KEY UPDATE" statements to be returned by the server. Default: false Since version: 5.1.7
该参数默认为false,我们最好不要进行修改,如果修改了就和JDBC标准不兼容!如果需要返回实际被修改的行,应该使用存储过程(使用row_count())
If you need to know how many records were *changed* (not that same as the number matching the where) then you might consider a stored procedure.
但是设置 useAffectedRows=true; 有一个好处,就是它能正确的返回 insert ... on duplicate key update 的结果(如果不设置为true,返回的结果是错误的):参见:http://blog.sina.com.cn/s/blog_7325f5150101i3v4.html
mysql jdbc url 另外两个重要的参数 userUnicode 和 characterEncoding:
useUnicode
Should the driver use Unicode character encodings when handling strings? Should only be used when the driver can't determine the character set mapping, or you are trying to 'force' the driver to use a character set that MySQL either doesn't natively support (such as UTF-8), true/false, defaults to 'true'
Default: true
Since version: 1.1g
characterEncoding If 'useUnicode' is set to true, what character encoding should the driver use when dealing with strings? (defaults is to 'autodetect') Since version: 1.1g
userUnicode 参数默认就是true,而characterEncoding默认是自动侦测。所以一般
jdbc:mysql://localhost:3306/dbname?useUnicode=true&characterEncoding=UTF-8
可以简化为:jdbc:mysql://localhost:3306/dbname?characterEncoding=UTF-8
关于对mysql复制的影响:
Important FOUND_ROWS() is not replicated reliably using statement-based replication. This function is automatically replicated using row-based replication.
Important ROW_COUNT() is not replicated reliably using statement-based replication. This function is automatically replicated using row-based replication.
注意:found_rows() 和 row_count() 在基于 语句的复制 环境中是不可靠的,它们自动使用 基于行的复制行为。
3. 总结
1)在存储过程迁移时, sql server 的 @@RowCount, oracle 的 sql%rowcount 可以被 mysql 的 found_rows()和row_count()替代;
2)mysql 中的 found_rows() 的三种用法;
3)mysql jdbc url 另外两个重要的参数 userUnicode 和 characterEncoding;
mysql jdbc 所有参数参见:http://dev.mysql.com/doc/connector-j/en/connector-j-reference-configuration-properties.html