贝叶斯网络、EM算法推导
文章目录
- 一、贝叶斯网络
-
- 1.1 网络推导
- 1.2 例题解析
- 二、EM算法
一、贝叶斯网络
贝叶斯网亦称“信念网”,它借助有向无环图(Directed Acyclic Graph,简称DAG)来刻画属性之间的依赖关系,并使用条件概率表(Conditional Probability Table,简称CPT)来描述属性的联合概率分布.
1.1 网络推导
具体来说, 一个贝叶斯网B由结构 G G G和参数 Θ Θ Θ两部分构成,即 B = ( G , Θ ) B= (G,Θ) B=(G,Θ).网络结构 G G G是一个有向无环图,其每个结点对应于一个属性,若两个属性有直接依赖关系,则它们由一条边连接起来;参数 Θ Θ Θ定量描述这种依赖关系,假设属性 x i x_i xi在 G G G中的父结点集为 π i π_i πi,则 Θ Θ Θ包含了每个属性的条件概率表 θ x i ∣ π i = P B ( x i ∣ π i ) θ_{x_i |π_i }= P_B (x_i |π_i) θxi∣πi=PB(xi∣πi).

贝叶斯网结构有效地表达了属性间的条件独立性.
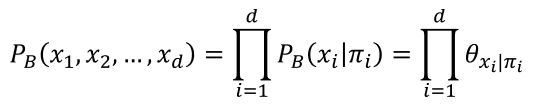
以图为例,联合概率分布定义为:
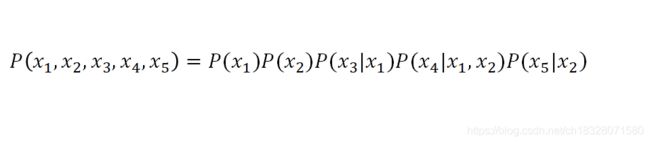
显然, x 3 x_3 x3和 x 4 x_4 x4在给定 x 1 x_1 x1的取值时独立, x 4 x_4 x4和 x 5 x_5 x5在给定 x 2 x_2 x2的取值时独立,分别简记为 x 3 ⊥ x 4 ∣ x 1 x_3⊥x_4 |x_1 x3⊥x4∣x1和 x 4 ⊥ x 5 ∣ x 2 x_4⊥x_5 |x_2 x4⊥x5∣x2.

在“同父”结构中,给定父结点 x 1 x_1 x1的取值,则 x 3 x_3 x3与 x 4 x_4 x4条件独立.在“顺序”结构中,给定x的值,则y与z条件独立. V型结构(V-structure)亦称“冲撞”结构,给定子结点 x 4 x_4 x4的取值, x 1 x_1 x1与 x 2 x_2 x2必不独立;若 x 4 x_4 x4的取值完全未知,则V型结构下 x 1 x_1 x1与 x 2 x_2 x2却是相互独立的.

为了分析有向图中变量间的条件独立性,可使用“有向分离”(D-separation).我们先把有向图转变为一个无向图:
找出有向图中的所有V型结构,在V型结构的两个父结点之间加上一条无向边;
将所有有向边改为无向边.
由此产生的无向图称为“道德图”,令父结点相连的过程称为“道德化”;
给定 x x x和 y y y,从道德图中将变量集合z去除后, x x x和 y y y分属两个连通分支,则称变量 x x x和 y y y被 z z z有向分离, x ⊥ y ∣ z x⊥y|z x⊥y∣z成立.


若网络结构已知,即属性间的依赖关系已知,则贝叶斯网的学习过程通过对训练样本“计数”,估计出每个结点的条件概率表即可.
但在现实应用中我们往往并不知晓网络结构,于是,贝叶斯网学习的首要任务就是根据训练数据集来找出结构最“恰当”的贝叶斯网.先定义一个评分函数(score function),以此来评估贝叶斯网与训练数据的契合程度,基于这个评分函数来寻找结构最优的贝叶斯网.
常用评分函数通常基于信息论准则,学习的目标是找到一个能以最短编码长度描述训练数据的模型,这就是“最小描述长度”(Minimal Description Length,简称MDL)准则.
给定训练集D={x_1, x_2,…,x_m},贝叶斯网B=⟨G,Θ⟩在D上的评分函数可写为

其中: f ( θ ) ∣ B ∣ f(θ)|B| f(θ)∣B∣是结构风险, L L ( B ∣ D ) LL(B|D) LL(B∣D)经验风险。 ∣ B ∣ |B| ∣B∣是贝叶斯网的参数个数; f ( θ ) f(θ) f(θ)表示描述每个参数 θ θ θ所需的字节数;而
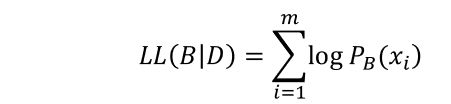
是贝叶斯网 B B B的对数似然(类似于极大似然估计).第一项是计算编码贝叶斯网B所需的字节数,第二项是计算B所对应的概率分布 P B P_B PB对 D D D描述的有多好.于是,学习任务就转化为一个优化任务,即寻找一个贝叶斯网B使评分函数 s ( B ∣ D ) s(B|D) s(B∣D)最小.
若f(θ)=1 ,即每个参数用1字节描述,则得到AIC(Akaike Information Criterion)评分函数

若 f ( θ ) = 1 2 l o g m f(θ)=\frac{1}{2}log m f(θ)=21logm,即每个参数用 1 2 l o g m \frac{1}{2} log m 21logm字节描述,则得到BIC(Bayesian Information Criterion)评分函数

显然,若 f ( θ ) = 0 f(θ)=0 f(θ)=0,即不计算对网络进行编码的长度,则评分函数退化为负对数似然,相应的,学习任务退化为极大似然估计.
不难发现,若贝叶斯网 B = ⟨ G , Θ ⟩ B=⟨G,Θ⟩ B=⟨G,Θ⟩的网络结构 G G G固定,则评分函数 s ( B ∣ D ) s(B|D) s(B∣D)的第一项为常数.最小化 s ( B ∣ D ) s(B|D) s(B∣D)等价于对参数 Θ Θ Θ的极大似然估计.参数 θ ( x i ∣ π i ) θ_(x_i |π_i ) θ(xi∣πi)能直接在训练数据 D D D上通过经验估计获得,即
![]()
因此,只需对网络结构进行搜索,而候选结构的最优参数可直接在训练集上计算得到.
从所有可能的网络结构空间搜索最优贝叶斯网结构是一个NP难问题.有两种常用的策略:第一种每次调整一条边,直到评分函数值不再降低为止;第二种是通过给网络结构施加约束来削减搜索空间,例如将网络结构限定为树形结构等.
推断:通过一些属性变量的观测值来推测其他属性变量的取值.例如在西瓜问题中,若我们观测到西瓜色泽青绿、敲声浊响、根蒂蜷缩,想知道它是否成熟、甜度如何.这样通过已知变量观测值来推测待查询变量的过程称为“ 推断”(inference), 观测值称为“证据”(evidence).
最理想的是直接精确计算后验概率, “精确推断”已被证明是NP难的; 此时需借助“近似推断”,推断常使用吉布斯采样(Gibbs sampling).
令 Q = { Q 1 , Q 2 , … , Q n } Q=\{Q_1,Q_2,…,Q_n\} Q={ Q1,Q2,…,Qn}表示待查询变量, E = E 1 , E 2 , … , E n E={E_1, E_2,…, E_n} E=E1,E2,…,En为证据变量,已知其取值为 e = { e 1 , e 2 , … , e k } e=\{e_1,e_2,…,e_k\} e={ e1,e2,…,ek}.目标是计算后验概率 P ( Q = q ∣ E = e ) P(Q=q|E=e) P(Q=q∣E=e),其中 q = q 1 , q 2 , … , q n q={q_1,q_2,…,q_n} q=q1,q2,…,qn是待查询变量的一组取值.
1.2 例题解析
以西瓜问题为例,Q= {好瓜,甜度},E= {色泽,敲声,根蒂}, e= {青绿,混响,蜷缩},查询q= {是,高},即这是好瓜且甜度高的概率有多大.
常用的方法:吉布斯采样
吉布斯采样算法先随机产生一个与证据 E = e E=e E=e 一致的样本 q 0 q^0 q0作为初始点,然后每步从当前样本出发产生下一个样本.
在第 t t t次采样中,算法先假设 q t = q t − 1 q^t= q^{t-1} qt=qt−1,然后对非证据变量逐个进行采样改变其取值,采样概率根据贝叶斯网B和其他变量的当前取值(即Z=z)计算获得.
假定经过T次采样得到的与q一致的样本共有n_q个,则可近似估算出后验概率
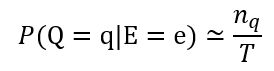

吉布斯采样是在贝叶斯网所有变量的联合状态空间与证据 E = e E= e E=e一致的子空间中进行“随机漫步”。每一步仅依赖于前一步的状态,这是一个“马尔可夫链”。 无论从什么初始状态开始,马尔可夫链第t步的状态分布在 t − → ∞ t-→∞ t−→∞时必收敛于一个平稳分布; 对于吉布斯采样来说,这个分布恰好是 P ( Q ∣ E = e ) P(Q| E=e) P(Q∣E=e).
马尔可夫链通常需很长时间才能趋于平稳分布。
二、EM算法
在这种存在“未观测”变量的情形下,是否仍能对模型参数进行估计呢?
未观测变量的学名是“隐变量”。令 X X X表示已观测变量集, Z Z Z表示隐变量集, Θ Θ Θ表示模型参数.若欲对 Θ Θ Θ做极大似然估计,则应最大化对数似然:
![]()
然而由于 Z Z Z是隐变量,上式无法直接求解。此时我们可通过对 Z Z Z计算期望,来最大化已观测数据的对数“边际似然”

EM (Expectation-Maximization)算法是一种迭代式的方法,其基本想法是:若参数 Θ Θ Θ已知,则可根据训练数据推断出最优隐变量 Z Z Z的值( E E E步);反之,若 Z Z Z的值已知,则可方便地对参数 Θ Θ Θ做极大似然估计( M M M步).
以初始值Θ^0为起点,可迭代执行以下步骤直至收敛:
(1)基于Θt推断隐变量Z的期望,记为Zt;
(2)基于已观测变量 X X X和 Z t Z^t Zt对参数 Θ Θ Θ做极大似然估计,记为 Θ t + 1 Θ^{t+1} Θt+1;
这就是EM算法的原型.
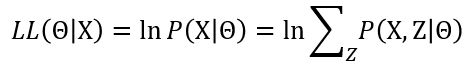
进一步,若我们不是取 Z Z Z的期望,而是基于 Θ t Θ^t Θt计算隐变量Z的概率分布 P ( Z ∣ X , Θ t ) P(Z|X,Θ^t) P(Z∣X,Θt),则EM算法的两个步骤是:
(1)E步: 以当前参数 Θ t Θ^t Θt推断隐变量分布 P ( Z ∣ X , Θ t ) P(Z|X,Θ^t) P(Z∣X,Θt), 并计算对数似然 L L ( Θ ∣ X , Z ) LL(Θ|X,Z) LL(Θ∣X,Z)关于Z的期望。

(2) M步: 寻找参数最大化期望似然,即:


简要来说,EM算法使用两个步骤交替计算:
- 第一步是期望(E)步,利用当前估计的参数值来计算对数似然的期望值;
- **第二步是最大化(M)步,**寻找能使E步产生的似然期望最大化的参数值.然后,新得到的参数值重新被用于E步,…直至收敛到局部最优解.
隐变量估计问题也可通过梯度下降等优化算法求解。
[上一篇]:贝叶斯分类器详解