Java高级程序设计笔记 • 【第5章 XML解析】
全部章节 >>>>
本章目录
5.1 XML 文档概述
5.1.1 XML文档结构
5.1.1 XML结构说明
5.1.1 XML文档元素
5.1.2 XML文档语法规范
5.1.3 实践练习
5.2 使用 Dom4j 创建 XML 文档
5.2.1 Xml解析方法简介
5.2.1 Dom4j解析
5.2.2 Dom4j的使用
5.2.2 Dom4j创建Xml文件
5.2.3 实践练习
5.3 使用 dom4j 解析 XML 文档
5.3.1 Dom4j递归解析Xml
5.3.1 使用Dom4j解析Xml文档
5.3.2 实践练习
5.4 XPath 路径语言
5.4.1 XPath简介
5.4.2 XPath使用
5.4.2 实践练习
总结:
5.1 XML 文档概述
XML是可扩展标记语言(Extensible Markup Language)的缩写
主要用于提供数据表述格式,适用于不同应用程序间的数据交换,而且这种交换不以预先定义的一组数据结构为前提,增强了可扩展性
XML在各个行业、各类应用中广泛使用,作为数据存储、传输交互等重要作用,具有很强的扩展性 :
- 跨平台
- 跨语言
- 灵活度高,可扩展
5.1.1 XML文档结构
XML 是一套定义语义标记的规则,同时也是用于定义其他标识语言的原标识语言。使用 XML 时,首先需要了解XML 文件的基本结构。下面通过一个简单的 XML 文件来说明 XML 的文档结构
前面学习的Html就是在Xml基础之上发展而来
示例:一个用于描述通知信息的Xml文件
文档声明
公告栏
2018 年 11 月 11 日 11 时 11 分
比赛通知
辩论会

5.1.1 XML结构说明
一个基本的 XML 文档通常由序言和文档元素两部分组成。
序言中可以包括 XML 声明、处理指令和注释,但这 3 项不是必须的。
XML 文档中的元素以树形结构排列,一个元素可以嵌套在另一个元素中。
XML文件的声明虽然不是必须,但是规范性一般都建议加上:
version:用于指定遵循 XML 规范的版本号,必须在第一个出现。
encoding:用于指定 XML 文档中使用的编码(utf-8或gbk最为常用)
5.1.1 XML文档元素
XML 文档中有且只有一个顶层元素,称为文档元素或根元素,类似于 HTML 页面中的 元素,其他元素都嵌套在根元素中。
XML 文档元素由开始标记、属性、元素内容和结束标记这几个部分组成。
content
Xml结构和Html很像,但是Html中的标签必须是规定的,不能随意命名,而Xml中根据需要自己定义标签名。
示例:一个用于描述学生信息的Xml文件
张鹏飞
男
武汉
李玉林
女
长沙

5.1.2 XML文档语法规范
Xml虽然可以自由扩展标签,但是必须遵循如下规范:
- 必须包含一个根元素,其他元素必须嵌套在根元素中。
- 元素嵌套要正确。
- 每一个元素必须同时拥有开始标记和结束标记,且区分大小写,并且名称完全匹配。
- 元素类型名称中可以包含字母、数字以及其他字母元素类型,也可以使用非英文字符,但不能以数字或符号“-”开头,同时也不能包含空格符合和冒号“:”。
- 元素可以包含属性,但属性必须位于单引号或双引号中(前后两个引号必须一致,不能一个是单引号,一个是双引号)。在一个元素节点中,属性名不能重复。
5.1.3 实践练习
5.2 使用 Dom4j 创建 XML 文档
5.2.1 Xml解析方法简介
程序中很多时候需要通过代码自动产生或者读取Xml文档,如何通过代码产生Xml文档,现阶段有很多第三方Xml解析库,常用的包括:
- Dom解析
- SAX解析
- JDOM解析
- Dom4j解析
5.2.1 Dom4j解析
dom4j 是 sourceforge.net 上一个开源的 Java 项目,主要用于操作 XML 文档,如创建 XML 文档和解析 XML 文档。dom4j 应用于 Java 平台,是一款优秀的 XML 解析器,它具有性能优异、功能强大和易使用等特点。目前,多数 Java 产品中解释 XML 数据都是使用 dom4j 技术来完成的。
项目中使用Dom4j需要先下载Dom4j的jar包添加至项目构建路径,否则无法使用
5.2.2 Dom4j的使用
使用Dom4j创建Xml文档步骤如下:
1、使用 DocumentHelper 类的 createDocument() 方法可以创建一个 XML 文档对象。
Doucment document=DocumentHelper.createDocument();2、DocumentHelper对象的 createElement()方法创建一个节点,然后使用Document对象 的 setRootElement() 方法将该节点设置为根节点
Element rootEle = DocumentHelper.createElement("books");
doc.setRootElement(rootEle); 3、继续调用DocumentHelper对象的 createElement()方法创建一个节点,调用Element 节点的add()方法为节点添加子节点
Element bookEle = DocumentHelper.createElement("book");
rootEle.add(bookEle);为节点添加属性、内容:
4、调用Element对象的addAttribute方法为节点对象添加属性。
// 第一个参数为属性名,第二个参数为属性值
bookEle.addAttribute("id", "001"); 5、调用Element对象的setText方法为节点对象添加内容。
bookEle.setText(" 使用 Java 深入理解程序逻辑 ");创建文档及节点后仍然在内存中,需要输出保存为Xml文档:
6、使用格式化输出保存为Xml文档
// 创建 OutputFormat 对象,用于格式化输出
OutputFormat format = OutputFormat.createPrettyPrint(); // 设置文档的编码
format.setEncoding("UTF-8");// 创建 XMLWriter 对象,用于输出 XML 文档
XMLWriter writer = new XMLWriter(new FileWriter(path), format);// 将 Document 文档输入到 shool.xml 文件中
writer.write(doc);
writer.close();5.2.2 Dom4j创建Xml文件
示例:使用Dom4j创建Xml文件
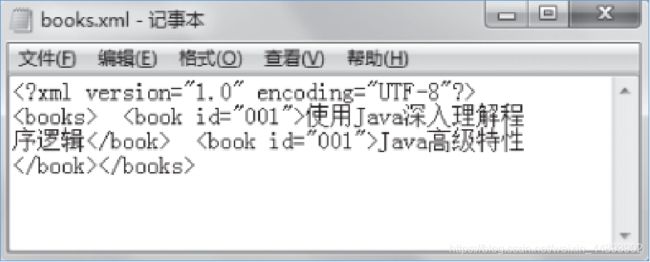
5.2.3 实践练习
5.3 使用 dom4j 解析 XML 文档
5.3.1 Dom4j递归解析Xml
程序中可以将数据信息创建保存为Xml文档,在必要的时候还需要读取Xml文档,dom4j除了可以保存Xml文档,还提供了对Xml文档读取解析的功能。
在解析 XML 文档前,需要先构建得到要解析的 XML 文件所对应的 XML 文档(Document)对象。
SAXReader reader=new SAXReader();// 实例化 SAXReader 对象// 获取 XML 文件的文档对象
Document document=reader.read(new File(“ xml文件路径名 "));获取Xml文档对象Document后,可以依次获取节点对象: 获取根节点对象。
Element rootElement = document.getRootElement();遍历节点下的相关子节点、属性、内容(可以使用递归逐层调用)
//定义递归遍历节点信息方法
public void listNodes(Element element) {
//获取相关属性、内容代码
//方法中获取当前节点下子节点,如果存在,则递归调用listNodes方法
}5.3.1 使用Dom4j解析Xml文档
示例:递归调用获取子节点相关信息方法:
// 递归遍历节点信息
public void listNodes(Element element) {
// 打印出节点名称
System.out.print("<" + element.getName());
// 获取节点的所有属性
List attributes = element.attributes();
Attribute attr = null;
// 循环遍历节点的每个属性
for (int i = 0; i < attributes.size(); i++) {
// 获取节点中的每个属性
attr = attributes.get(i);
// 打印出节点的属性名和属性值
System.out.print("\t" + attr.getName() + "=" + attr.getValue());
}
// 判断节点内是否有文本
if (!"".equals(element.getTextTrim())) {
System.out.print(">" + element.getText());
} else {
System.out.println(">");
}
// 获取当前节点下的所有子节点
Iterator eleIterator = element.elementIterator();
// 判断该节点下是否还有子节点
while (eleIterator.hasNext()) {
// 取出子节点
Element e = eleIterator.next();
// 递归遍历子节点的信息
listNodes(e);
}
5.3.2 实践练习
5.4 XPath 路径语言
5.4.1 XPath简介
如何在复杂的Xml文档中快速定位、查找所需要的节点信息?
XPath 即 XML 路径语言,它是一种用于确定 XML 文档中某部分位置的语言,能够帮助开发中快速定位、获取所需要的节点。
XPath 选取节点路径的表达式见表:
| 表达式 |
描述 |
| / |
从根节点出发选取 |
| // |
从当前节点出发,选择文档中的节点,不考虑它们的位置 |
| . |
选取当前节点的父节点 |
| @ |
选取属性 |
在 XPath 中定位某些指定的节点,需要使用 XPath 中的谓语。谓语用于查找某个特定的节点或包含某个指定的值的节点,谓语被嵌套在方括号中。XPath 中常用的谓语见表:
| 表达式 |
描述 |
| /note/info[1] |
选取属于 note 元素的第一个 info 元素 |
| /note/info[last()] |
选取属于 note 元素的最后一个 info 元素 |
| /note/info[last()-1] |
选取属于 note 元素的倒数第二个 info 元素 |
| //info[@id] |
选取所有属性名为 id 的 info 元素 |
| /info[@id='2'] |
选取所有属性名为 id 且该属性值为 2 的 info 元素 |
| /note/info[price>5] |
选取 note 节点下所有的 info 元素,而且其中的子元素 price 的值须大于 5 |
5.4.2 XPath使用
示例:使用 dom4j 解析 XML 文档内容,XML 文档格式如图

在 XML 文档中,所有的内容都可以成为节点,节点分为元素节点、属性节点和文本节点。
如果使用 XPath,必须添加 Jaxen 的 jar 文件,否则无法支持XPath路径
示例:使用XPath解析Xml
// 获取根节点对象
List rootNodeList = document.selectNodes("/books");
System.out.println(" 根节点名称:" + rootNodeList.get(0).getName());
// 获取所有 book 节点
List bookNodeList = document.selectNodes("/books/book");
// 获取所有 id 属性值
List idNodeList = document.selectNodes("//@id");
for (int i = 0; i < idNodeList.size(); i++) {
Node idNode = idNodeList.get(i);
System.out.println(" 第 " + ( i + 1) + " 个 book 节点的 id 值:" + idNode.getStringValue());
}

// 获取第 1 本书的书名
List firstBookList = document.selectNodes("/books/book[1]/name");
System.out.println(" 第 1 本书的书名是 :" + firstBookList.get(0).getText());
// 获取倒数第 2 本书的作者
List lastBookList = document.selectNodes("/books/book[last()-1]/author");
System.out.println(lastBookList.get(0).getStringValue());
System.out.println(" 倒数第 2 本书的作者是 :" + lastBookList.get(0).getText());

5.4.2 实践练习
总结:
- Xml文件普遍用于各行业、各类型软件中,作为存储和传输数据的格式。
- Xml文件具有跨平台、跨语言、灵活扩展等特点。
- 解析Xml文件的方法有很多,其中Dom4j是一款非常优秀的第三方Xml文档开源操作工具包,经常集成在各类优秀框架中。
- 利用Dom4j可以创建产生Xml文档以及读取解析Xml文档。
- XPath是一种对Xml文档进行快速查找、定位的路径语言,使用document对象的selectNodes方法可以加入路径语言获取需要的节点进行操作。