前言
正则表达式(Regular Expression)字面意思是具有一定规则的表达式,通常被用来检索、替换那些符合某个规则的文本。
自己刚接触正则的时候也是一脸懵逼的,看各种正则表达式也是看的一头雾水的...所以没有去深挖,工作中用到正则才去百度-.-
个人总结,正则匹配无非就两个:
- 匹配字符
- 匹配位置(可以理解为限定条件)
还是举个例子吧,比如一个简单的匹配,匹配一个数字:
- 匹配字符
/d+/gm
匹配了多个数字,其中d 代表匹配数字,+表示至少匹配 一次(贪婪)

- 匹配位置
/^d+/gm
这次我们先匹配了一个 ^(开头),后面又匹配了多个数字

其实我们可以这样理解,限定了数字必须紧跟着开头,可以改写为
/(?<=^)d+/gm
?<=^ 表示匹配 ^ 后面的位置

自己初学正则的时候看到一堆字符也是一头雾水的,安利两个有助于学习的网站:
- Regular Expressions 101
非常好用,强烈推荐
- Regulex
图形化,非常有助于拆解、理解复杂的正则
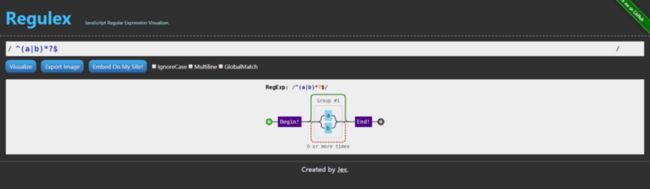
下面开始进入正题~.~
正则基础
声明
- 字面量创建方式
let reg = /pattern/attributes;
- 实例创建方式
let reg = new RegExp(pattern, attributes)
RegExp 对象方法
- exec()
exec() 方法用于检索字符串中的正则表达式的匹配。返回一个数组,其中存放匹配的结果。如果未找到匹配,则返回 null
/hello/.exec('hello world');
// ["hello", index: 0, input: "hello world", groups: undefined]
- test()
test() 方法用于检测一个字符串是否匹配某个模式。返回值 true 或 false
/hello/.test('hello world'); // true
修饰符
| 修饰符 | 描述 |
| :----: | :--------------------: |
| g | global(执行全局匹配) |
| i | IgnoreCase(忽略大小写) |
| m | Multiline(多行模式) |
元字符
常用的拥有特殊含义的字符:
| 元字符 | 描述 |
| ------ | :----------------------------------------------------------------: |
| . | 通配符,换行符、回车符、行分隔符和段分隔符除外 1 |
| | 转义字符 |
| | | 或者 |
| () | 分组 |
| ^ | 限定开始位置 => 本身不占位置 |
| $ | 限定结束位置 => 本身不占位置 |
| w | 匹配单词字符 [0-9a-zA-Z_] |
| W | 除了w 2 |
| d | 匹配数字 [0-9] |
| D | 除了d 3 |
| s | 查找空白字符 [tvnrf] |
| S | 除了s 4 |
| b | 匹配单词边界 |
| B | 除了b |
| 0 | 查找 NUL 字符 |
| n | 匹配换行符 |
| f | 查找换页符 |
| r | 查找回车符 |
| t | 查找制表符 |
| v | 查找垂直制表符 |
量词
| 量词 | 描述 |
| ----- | :------------------: |
| * | 0 到多个 |
| + | 1 到多个 |
| ? | 0 次或 1 次 可有可无 |
| {n} | n 次 |
| {n,} | n 到多次 |
| {n,m} | n 次到 m 次 |
锚点
| 修饰符 | 描述 |
| -------------- | :------------------------------------: |
| ^ | 开头 |
| $ | 结尾 |
| b | 单词边界 |
| B | 非单词边界 |
| (?=p)、(?<=p) | p 前面(位置)、p 后面(位置) |
| {?!p}、(?) | 除了 p 前面(位置)、除了 p 后面面(位置) |
字符匹配总结
1 模糊匹配
1.1 横向模糊匹配
一个正则可匹配的字符串的长度不是固定的,可以是多种情况的。
let reg = /ab{2,5}c/g;
let str = 'abc abbc abbbc abbbbc abbbbbc abbbbbbc';
console.log(str.match(reg)); // ["abbc", "abbbc", "abbbbc", "abbbbbc"]
1.2 纵向模糊匹配
一个正则匹配的字符串,具体到某一位字符时,它可以不是某个确定的字符,可以有多种可能。
let reg = /a[123]b/g;
let str = 'a0b a1b a2b a3b a4b';
console.log(str.match(reg)); // ['a1b', 'a2b', 'a3b']
2 贪婪匹配和惰性匹配
2.1 贪婪匹配
贪婪匹配是尽可能多的匹配
let str = "123456789";
let reg = /d{2,5}/g;
console.log(str.match(reg));
// ["12345", "6789"] 每次都是最大化的5次
2.2 非贪婪匹配
非贪婪匹配是在满足匹配的情况下,尽可能少的匹配。在量词后面加个'?'
let str = "123456789";
let reg = /d{2,5}?/g;
console.log(str.match(reg));
// ["12", "34", "56", "78"] 每次都是最小化的2次,匹配到9时不满足匹配条件
3 多表达分支
只要其中某个子表达式能够匹配,整个多选结构的匹配就成功;如果所有子表达式都不能匹配,则整个多选结构匹配失败。
let str = "helloworld";
let reg1 = /hello|helloworld/g;
let reg2 = /helloworld|hello/g;
console.log(str.match(reg1)); // ["hello"]
console.log(str.match(reg2)); // ["helloworld"]
类似于 js 中的|,会短路前面匹配上了(为 true),后面的就不管了
位置匹配总结
1 位置特性
位置,可以理解成空字符 '';
例如,我们可以拆解字符串:
"hello" === "" + "h" + "" + "e" + "" + "l" + "" + "l" + "o" + "";
"hello" === "" + "" + "hello"

所以对于 /^hello$$/ 其实等价于 /^^^^^^hello$$$$$$/
2 锚点符
| | 描述 |
| -------------- | :------------------------------------: |
| ^ | 开头 |
| $ | 结尾 |
| b | 单词边界 |
| B | 非单词边界 |
| (?=p)、(?<=p) | p 前面(位置)、p 后面(位置) |
| {?!p}、(?) | 除了 p 前面(位置)、除了 p 后面面(位置) |
锚点可以理解为限制条件,我们还是举个例子吧,假设有一个字符串 'hello , i love you'
- 匹配 'hello'
so easy,信手拈来
/hello/gm

- 匹配 'hello'中的'e'
emmm.....这个......,如果 用 /e/gm,那么 'love'中的'e'也会被匹配进去,这个时候我们的锚点符就派上用场了。
我们可以限制必须是 'hello'中的'e':
/(?<=h)e(?=l)/gm

上面的正则翻译为人话就是 在'h'和'l'之间的位置,匹配一个'e',注意锚点符只是启了限制作用,并不匹配 'h'、'l'
3 经典案例
3.1 url 参数截取
简单,懂了位置匹配(可理解为限定条件),再也不用老掉牙的字符串切割了哈哈哈哈~.~
function get_query_param(param_name) {
const reg = new RegExp(`(?<=${param_name}=)[^&]*`, 'g');
const result = window.location.search.substr(1).match(reg);
return result ? result[0] : '';
}
3.2 正整数或一位小数
要求写一个正则,校验数字是否为正整数或者一位小数。
这对我来说不是很简单,不就是校验正整数+小数校验吗:
- 正整数部分 ([1-9]d*|0)
- 小数部分 (.d{1})?
/^([1-9]d*|0)(.d{1})?$/g
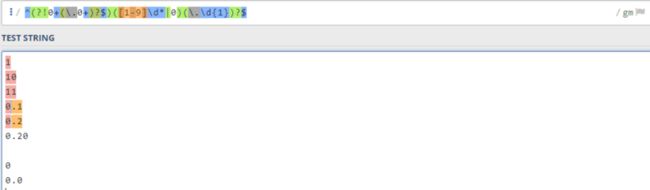
这段正则看起来很完美,可是却忽略了一些,因为不考虑小整数情况下,零是不可能存在在整数位上的,但如果支持小数的话,就会出现一些问题,如 0 0.0 等

所以我们还得对开头做一些限制,限制一些特殊情况,限制开头可以用 (?!^),完整代码如下:
function check_is_positive_integer_one(check_num) {
const reg = /^(?!0+(.0+)?$)([1-9]d*|0)(.d{1})?$/g;
return reg.test(check_num);
}
括号总结
1 分组
和数学上一样,计算机的括号可以用来分组隔离,括号内的被当成一个整体
let regex = /^I love (guagndong|xizang)$/;
console.log( regex.test("I love guagndong") ); // true
console.log( regex.test("I love xizang") ); // true
2 引用分组
yyyy-mm-dd => mm/dd/yyyy
let reg = /(d{4})-(d{2})-(d{2})/;
let str = '2020-06-02';
str.replace(reg, '$2/$3/$1'); // "06/02/2020"
3 反向引用
匹配如下三种日期格式:
2020-06-02
2020/06/02
2020.06.02
可使用1、2......3 来引用前一个()相同的匹配,即1 代表引用第一个括号的匹配,依次类推:
- 括号嵌套,以左括号为准依次数 1,2,...
- 括号分组若超过 10,则10 代表匹配1 和 0
- 引用不存的分组,则1 代表匹配转义后的'1'
let reg = /d{4}(-|/|.)d{2}1d{2}/;
reg.test('2020-06-02'); // true
reg.test('2020/06/02'); // true
reg.test('2020.06.02'); // true
reg.test('2020-06/02'); // false
4 非捕获分组 (?:p)
如果只想要括号最原始的功能,但不会引用它,即,既不在 API 里引用,也不在正则里反向引用。此时可以使用非捕获分组(?:p)
let reg = /(?:ab)+/g;
let str = 'ababab aba ab';
str.match(reg);
// ["ababab", "ab", "ab"]
纯手码,如有不足或问题,欢迎指出
原文链接:JS 正则总结
END