原文转载自「刘悦的技术博客」https://v3u.cn/a_id_171
最近“全栈数据库”的概念甚嚣尘上,主角就是PostgrelSQL,它最近这几年的技术发展不可谓不猛,覆盖OLTP、OLAP、NoSQL、搜索、图像等应用场景,实实在在的全栈性发展。帮助公司解决了数据孤岛、数据平台多、同步一致性、延迟,软硬件成本增加等业务痛点,在互联网、金融、物联网、传统企业等领域得到了广泛的应用。PostgreSQL的应用场景丰富,不亚于商用数据库Oracle,常被业界称为“开源界的Oracle”。
至于Mysql大家都很熟悉,很多公司因为人才储备和数据量大的原因,一般是Hadoop+Mysql的模式,Hadoop计算大量原始数据,然后按维度汇总后的展示数据存储在Mysql上,但是Mysql也有很多的“坑”:比如著名的Emoji表情坑,由此引申出来的utf8mb4的坑(隐式类型转换陷阱),性能低到发指的悲观锁机制,不支持多表单序列中取 id,不支持over子句,几乎没有性能可言的子查询........有点罄竹难书的意思,更多的“罪行”详见:见鬼的选择:Mysql。而这些问题,在PostgrelSQL中得到了改善,本次我们在Win10平台利用Docker安装PostgrelSQL,并且初步感受一下它的魅力。
第一步当然是安装Docker,不熟悉的同学请参照:win10系统下把玩折腾DockerToolBox以及更换国内镜像源(各种神坑)。
随后拉取镜像,这里我们选择相对稳定的PostgrelSQL11.1。
docker pull postgres:11.1拉取成功后,输入命令查看镜像
docker images可以看到,它的镜像非常小,大概300m左右,比Mysql小很多。

然后我们就可以将容器启动了,输入命令
docker run -d --name dev-postgres -e POSTGRES_PASSWORD=root -p 6432:5432 postgres:11.1这里POSTGRES_PASSWORD是PostgrelSQL的用户密码,自己制定一个就可以了,默认端口号是5432,由于笔者的宿主机上已经安装好一个PostgrelSQL服务端,所以这里通过端口映射改成了6432。
输入命令
docker ps来查看容器运行状态
![]()
没有问题,现在我们进入命令行操作一下。
docker exec -it dev-postgres bash
psql -h localhost -U postgres
这样就可以进入容器内部的命令行,在命令行输入PostgrelSQL的命令l 就可以查看数据库列表。
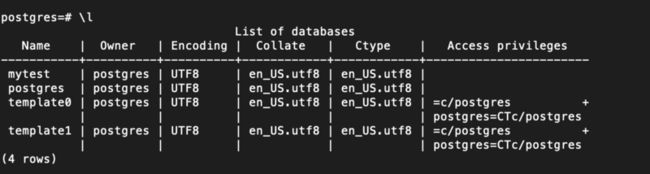
建立数据库
CREATE DATABASE mytest;使用数据库
\c mytest建立一张表
CREATE TABLE "public"."article" (
"id" int4 NOT NULL,
"content" text,
PRIMARY KEY ("id")
)
WITH (OIDS=FALSE);列出所有表
\d如果不习惯使用命令行,也可以用可视化工具来进行链接,比如Navicat

注意默认用户是postgres,值得一提的是,使用navicat无法像Mysql一样手动设置属性自增长(auto-increment),PostgrelSQL使用的是序列的形式来实现自增长:
CREATE SEQUENCE serial START 1;这里创建好的序列是从1开始计数。
随后,将需要设置的字段的默认值设为序列增长即可
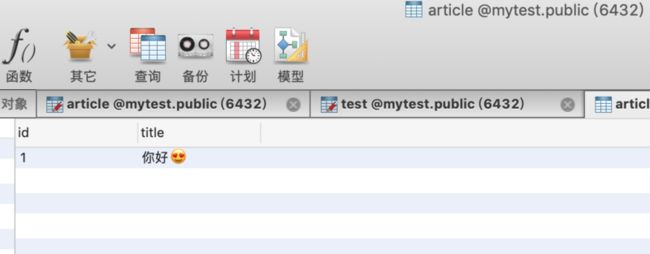
ALTER TABLE "public"."article" ALTER COLUMN "id" SET DEFAULT nextval('serial');可以使用utf-8编码轻松存储Emoji
over子句的应用,假设我们有一个员工薪资的表(部门、员工id,工资):
postgres=# d empsal
Table "public.empsal"
Column | Type | Modifiers
---------+-------------------+-----------
depname | character varying |
empno | integer |
salary | integer |有一些数据:
postgres=# select * from empsal ;
depname | empno | salary
-----------+-------+--------
develop | 11 | 5200
develop | 7 | 4200
develop | 9 | 4500
develop | 8 | 6000
develop | 10 | 5200
personnel | 5 | 3500
personnel | 2 | 3900
sales | 3 | 4800
sales | 1 | 5000
sales | 4 | 4800
(10 rows)现在我想将每一个员工的工资与他所在部门的平均工资做个比较,怎么做?其实这也是leetcode原题,用mysql只能用子查询,而用PostgrelSQL该查询可以很容易的实现
SELECT depname, empno, salary, avg(salary) OVER (PARTITION BY depname) FROM empsal;查询结果:
depname | empno | salary | avg
-----------+-------+--------+-----------------------
develop | 11 | 5200 | 5020.0000000000000000
develop | 7 | 4200 | 5020.0000000000000000
develop | 9 | 4500 | 5020.0000000000000000
develop | 8 | 6000 | 5020.0000000000000000
develop | 10 | 5200 | 5020.0000000000000000
personnel | 5 | 3500 | 3700.0000000000000000
personnel | 2 | 3900 | 3700.0000000000000000
sales | 3 | 4800 | 4866.6666666666666667
sales | 1 | 5000 | 4866.6666666666666667
sales | 4 | 4800 | 4866.6666666666666667
(10 rows)可以看到,这个查询中,聚合函数avg的含义没有变,仍然是求平均值。但和普通的聚合函数不同的是,它不再对表中所有的salary求平均值,而是针对同一个部门(PARTITION BY指定的depname)内的salary求平均值,而且得到的结果由同一个部门内的所有行共享,并没有将这些行合并,这就大大简化了sql的复杂度,同时也能很方便的解决 "每组取 top k" 的这类问题。
使用容器启动数据库会有个问题,就是每次容器停止,数据就会丢失,所有我们可以用docker的挂载命令将数据存在宿主机中,这样就可以持久化保存数据:
docker run -d --name dev-postgres -e POSTGRES_PASSWORD=root -e PGDATA=/var/lib/postgresql/data/pgdata
-v /custom/mount:/var/lib/postgresql/data -p 6432:5432 postgres:11.1如果你不习惯navicat这样的桌面可视化工具,也可以使用类似pgadmin4这样的网页端工具
$ docker pull dpage/pgadmin4
$ docker run
-p 80:80
-e '[email protected]'
-e 'PGADMIN_DEFAULT_PASSWORD=SuperSecret'
--name dev-pgadmin
-d dpage/pgadmin4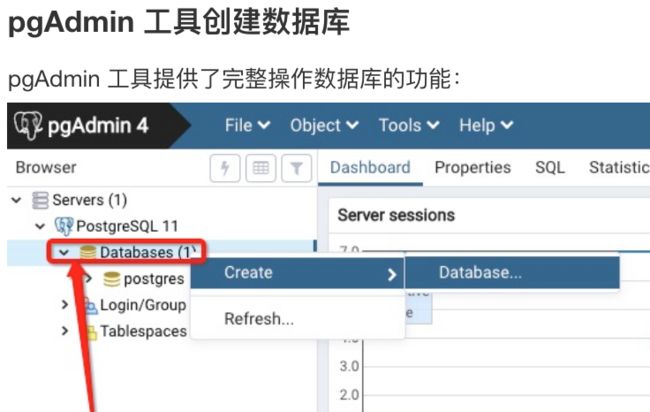
也可以使用Python和PostgrelSQL进行交互,安装三方库:
pip3 isntall psycopg2import psycopg2
import psycopg2.extras
conn = psycopg2.connect(host='localhost', port=6432, user='postgres', password='root', database='mytest')
cursor = conn.cursor(cursor_factory=psycopg2.extras.DictCursor)
cursor.execute('SELECT * FROM article WHERE id = 1;')
result = cursor.fetchone()
print(result)就可以查询出数据了

结语:如果对Mysql足够熟悉,那么上手PostgrelSQL并不是一件难事,自从MySQL被Oracle收购的那一刻起,它就已经不是开源软件的最佳选择了。所以,不要固执的拒绝时代浪潮,拥抱未来,拥抱PostgrelSQL吧。
原文转载自「刘悦的技术博客」 https://v3u.cn/a_id_171